
Google Gemini Pro VisionのAPIをStreamlitでウェブアプリ構築方法

Google Gemini Pro Visionという画像に対して操作が可能なAPIがあります。
今回、Google Gemini Pro VisionのAPIを利用して、Streamlitでウェブアプリを構築方法を紹介していきます。

まずは、app.pyとして以下を用意します。
import streamlit as st
import google.generativeai as genai
from PIL import Image as PIL_Image
from io import BytesIO
# APIキーの設定
api_key = st.sidebar.text_input("API Key", type="password")
genai.configure(api_key=api_key)
# モデル読み込み
multimodal_model = genai.GenerativeModel("gemini-pro-vision")
# Streamlitの画面設定
st.title("😱画像解析アプリ(Gemini Pro Vision)")
st.write("画像をアップロードして、その内容についての説明を得るアプリです。")
# ファイルアップロード
uploaded_file = st.file_uploader("画像をアップロードしてください", type=["png", "jpg", "jpeg"])
if uploaded_file is not None:
# 画像の表示
image = PIL_Image.open(uploaded_file)
st.image(image, caption="アップロードされた画像", use_column_width=True)
# プロンプト入力
prompt = st.text_input("画像についてのプロンプトを入力してください", "この画像について説明しなさい?")
# コンテンツの準備
contents = [image, prompt]
# レスポンスの生成
if st.button("解析開始"):
with st.spinner("解析中..."):
responses = multimodal_model.generate_content(contents, stream=True)
# レスポンスの表示
for response in responses:
st.write(response.text)
次に、Pythonがインストールされている環境で以下を実行しますと完成となります。
python -m venv venv
venv\Scripts\Activate
pip install google-generativeai streamlit
streamlit run app.py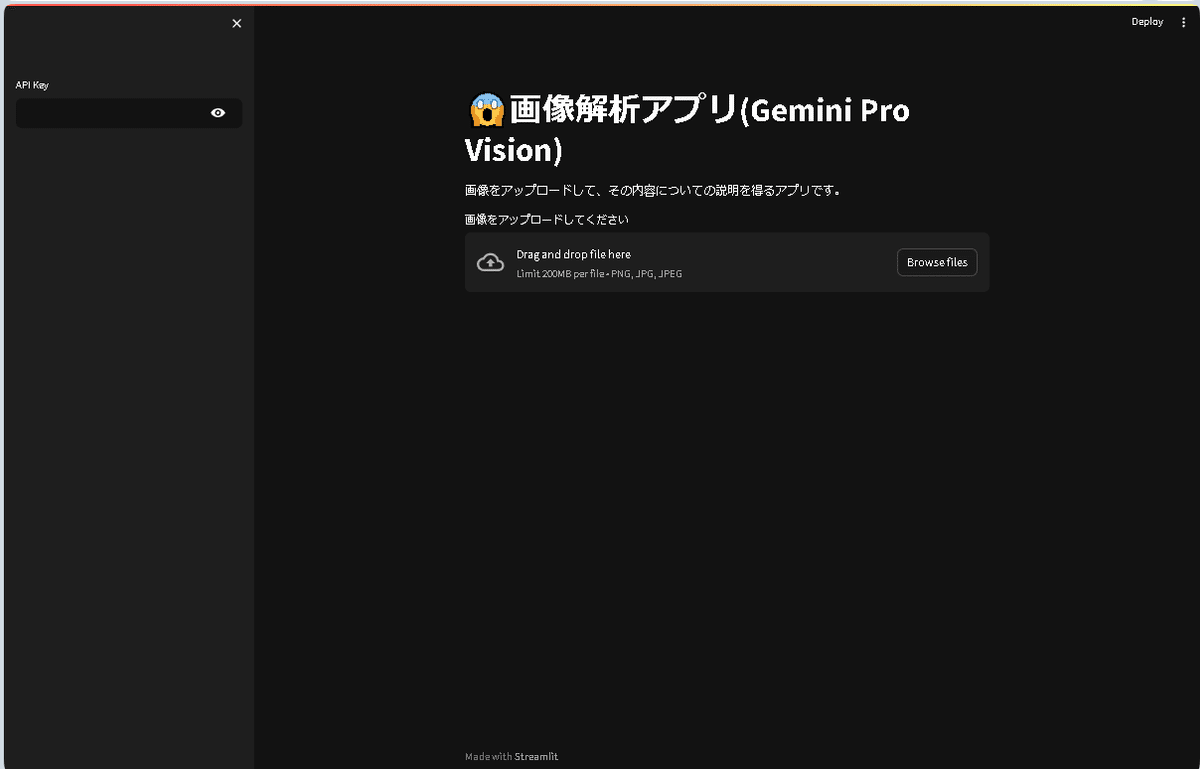
使い方は、左側にAPI Keyと書かれているところに、Google GeminiのAPIキーを入力します。
次に、右側で"Browsefiles"をクリックして、読み込ませたい画像をアップロードします。
次に、画像が表示されますので、この画像に対してAIに問いたいことをPromptに書いて、解析開始ボタンを押します。

この画像について、色々と聞いてみます。



この記事が気に入ったらサポートをしてみませんか?