
Open-InterpreterをLinuxで使うための考察。(InfraGPT構築記録v4)

今回は、Open-IntepreterをLinuxにインストールしてどのように使えるかを紹介していきます。
今までのInfraGPT構築記録も興味がありましたら読んでいただければ幸いです。
使用環境は、AWSのUbuntsuにPython環境を構築し、open-interpreterをインストールして基盤機能についてどのように扱えるかを検証します。
検証項目は、基盤観点で考えています。
cpu、memory使用率の表示
cpuのHW情報の表示
プロセス情報の表示
ネットワークインターフェース情報の表示
サービス停止及び起動
OS停止
root権限になったところからスタートします。python3はデフォルトでインストールされております。pip3はインストールされていないのでインストールします。python3-pipをインストールするときに、yをEnterします。
python3 --version
apt update
apt install python3-pip
また、次の画面が表示されたら、TabキーでOKを選択し、Enterキーを押します。

次に、Open-Intepreterをインストールします。
pip install open-intepreterここまでで、Open-Interpreterのインストールは完了となります。次に、下記コマンドを打ち、OpenAIのAPIキーを入力するところがありますので、sk---で始まるOpenAIのAPIキーを入力すると開始となります。
interpreter
cpu、memory使用率の表示
まずは、cpuの使用率について聞いてみます。必要な個所のみ画像で貼り付けています。


次に、memoryの使用率について聞いてみます。


cpuのHW情報の表示
cpuのHW情報について伺ってみます。


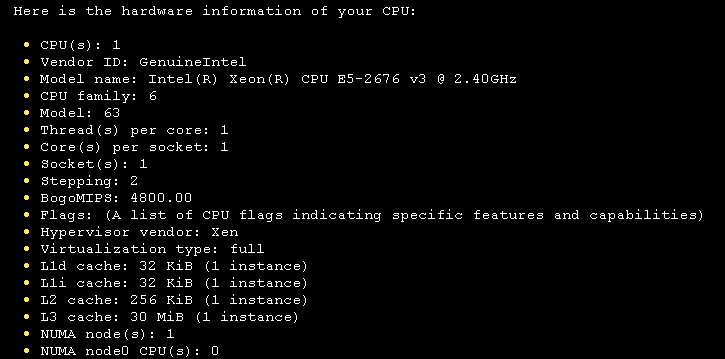
少し細かすぎますが、cpuの詳細な情報が出力されました。
プロセス情報の表示
どんなプロセスが必要か気になりますので、プロセス情報を確認します。
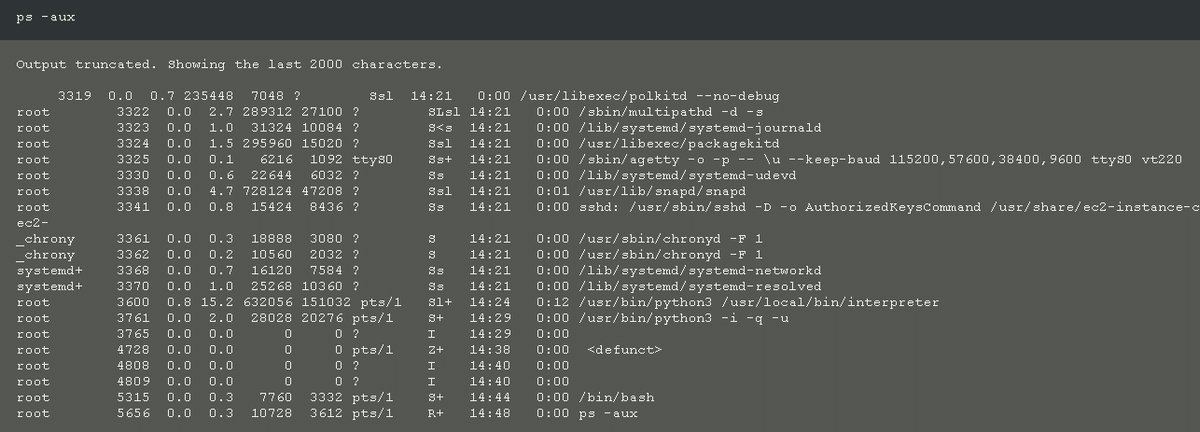
ネットワークインターフェース情報の表示
ネットワークインターフェース情報を得てみます。なお、今まではgpt-4を使用していましたが、利用料が高いので、gpt-3.5-turboに切り替えています。


サービス停止及び起動
サービス停止及び起動ということで、nginxを停止及び起動してみます。

では、次にnginxを起動します。

OS停止
OSの停止を試してみます。

全体の所感としては、Linuxにopen-interpreterを導入してLinux操作ができるか確認しました。自然言語をコマンドにして、正確に実行してくれて驚きました。基盤系の基本的な作業は実行できることがわかりました。複雑な作業をできるかどうか検証してみると面白いです。例えば、Nginxをインストールして、Nginxの詳細なパラメータ設定ができるかどうかなどです。
あとは、gpt-4を使用するとコストがかかるので、gpt-3.5-turboが落としどころなのかなと考えています。本日の検証だけで、1.2ドルほどかかりました。
この記事が気に入ったらサポートをしてみませんか?