
OpenAIのGPT-4Vを使用したパソコン画面操作の方法

今回は、OpenAIのGPT-4Vを使用したパソコン画面を操作することができるコードの紹介です。
GPT-4Vは、OpenAIの画像認識あるいは画像理解ができるAPIです。
このGPT-4VのAPIを使用して、パソコン画面を操作しようというコードを見つけました。
自PCで下記を実行します。上記はMac用なので、Windows用に少し修正しています。
git clone https://github.com/OthersideAI/self-operating-computer.git
cd self-operating-computer
python -m venv venv
venv\Scritps\activate
pip install -r requirements.txt
pip install .
rename .example.env .env次に、.envファイルを開いて、your-key-hereにOpenAIのAPIキーを記載します。
OPENAI_API_KEY='your-key-here'そして、次のコマンドを打って実行します。
operate実行すると下記のような画面が出ますので、Enterを押下します。
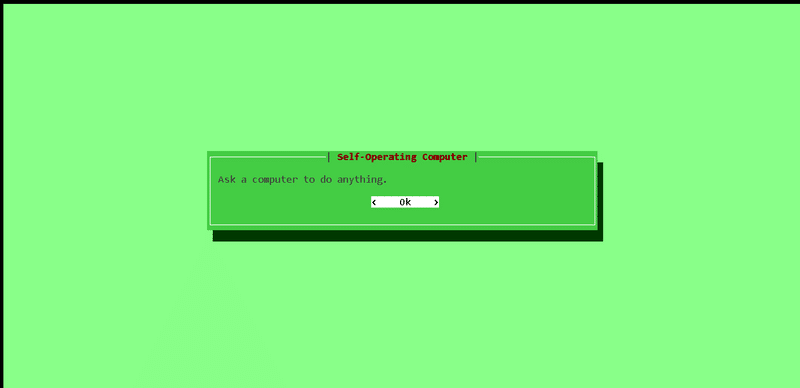
次に、[User]のところに何か実行させたいことを英語で依頼してみましょう。

下記のように実行ログが出力されていきます。

実行結果は、1回だけうまく行きましたが、それ以外はうまくいきませんでした。
WindowsではなくMacならうまくいったのかもしれません。
所感としては、GPT-4VのAPIで画像認識あるいは画像に対する説明結果を取得することができるようになったので、パソコン画面を画像として認識して、GPT-4Vで画像認識させてパソコンを操作させるのは面白いです。
精度的にイマイチのように思いますが、今後の発展が色々と見込まれます。
精度が向上したり、自然言語の音声からパソコンを操作することができるようになったりとかすることが見えてきています。
ちなみに、今回数回ほどガチャガチャしてみましたが、API利用料金は以下となります。
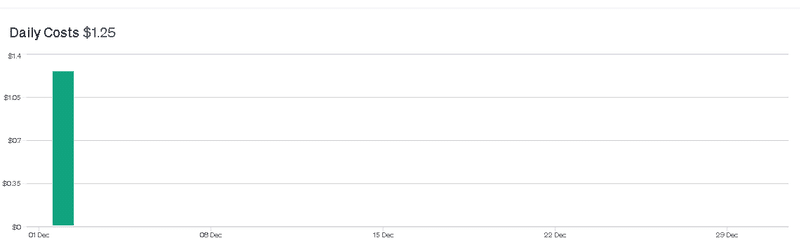
数回使用しただけで1ドル超えているとは、API使用量は要注意ですね。
この記事が気に入ったらサポートをしてみませんか?