
生成AIの活用事例 10選

「テクノロジーで人々を適切な医療に案内する」をミッションに、医療プラットフォームを提供しているUbie株式会社の@masa_kazamaです。
この記事は#Ubieアドベントカレンダー5日目にエントリーしています。
今年は生成AI一色の1年でした。Ubieでは、生成AIをプロダクト活用と社内生産性向上の観点で取り組んでいます。(取り組みの詳細は、こちらの記事で紹介しています。)
この記事では、社内生産性向上観点で、社内の業務プロセスに溶け込んでいて、なくてはならない使い方になっている事例を10個ご紹介します。その中のいくつかは、実際に生産性が倍以上になっていたり、外部委託のコストが半分になったりしています。この記事が、生成AIを活用している人や活用していきたい人のご参考になれば幸いです。
プロダクト活用にもいくつか事例が出ており、問診の内容を大規模言語モデル(LLM)を活用して要約する機能をリリースし、数百の医療機関で実際に利用されています。こちらの詳細については、「生成AIを活用した新機能開発を通して医師PdMが得たものとは」の記事をご覧ください。
それではまず10個の事例をご紹介していきます。生成AIに関するツールや使い方、プロンプトなどをご紹介します。(粒度がバラバラですがご了承ください。) 最後に、UbieでのLLMアプリケーションエンジニアの求人についてもご紹介します。
生成AIの活用事例10選
コンテンツ作成のレビュー
Ubieでは病気や症状に関するコンテンツを作成して提供しています。
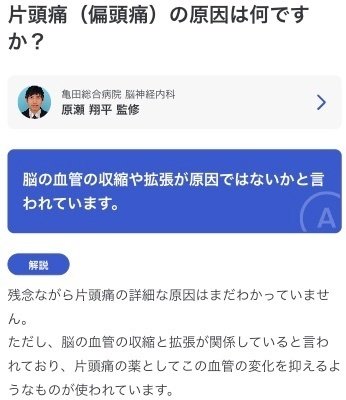
このようなコンテンツは、社内の医師や監修医が医学書や論文をもとに、ユーザーに分かりやすいように作成しています。まず、医師が下書きを書きます。次に、それの分かりやすさや観点のぬけもれがないかのレビューをします。そのレビューを反映して最終的なコンテンツが完成します。
このコンテンツ作成のプロセスにおいて、レビューの時間に数時間かかっていました。このレビューでは、重点的に見る項目(読みやすさ等)がすでに決まっていたので、その部分をLLMを活用して自動化することで、レビューの負担を減らしました。
コンテンツは、Googleスプレッドシート上で、医師が文章を入力しています。Google App Script(GAS)を利用して、その文章を各重点項目について5点満点で採点させて、改善すべき要素を提案するシステムを構築しました。そのレビューに対して、人間のレビュアーがさらに追記します。

右上の「レビュー開始」を押すとレビューがされる
今まで作業していたスプレッドシートに1つボタン(右上のレビュー開始ボタン)が追加され、それを押すだけで自動でレビューが走ります。そのため、今までの業務プロセスにシームレスに溶け込む形で、結果的に今までのレビュー時間が半分以下になりました。また、レビューのクオリティも同等か、人による偏りがない分より良くなる場合がありました。(※コンテンツ自体を生成AIで作成することは安全面や質の観点でしておりません。)
このGASの仕組みは、社内の医師が自ら、LLMを活用してGASのコードを書いて、システムを構築しました。
tl;dvとLLMによる文字起こしと要約
社内では、Google Meetを使って打ち合わせをすることが多いです。tl;dvというサービスを利用すると、Google Meetのオンライン会議の内容を文字起こししてくれます。

この文字起こしテキストとLLMを活用すると、会議の要約やブログ記事の投稿や会議改善の示唆出しができます。特にブログ記事執筆では、なかなか筆が進まないときに、オンライン会議で雑談する形で話したものをブログ記事用にLLMに修正してもらうと、原稿の下書きが完成します。
2023年11月に、OpenAI社がgpt-4-1106-previewという新しいAPIをリリースしました。こちらは入力の文字数が約10万字まで対応しています。そのため、tl;dvで数時間話した内容もそのまま入力することができ、とても便利です。
社内用ChatGPTツール
Ubie社内では、社内用ChatGPTを内製しています。本家のChatGPTとは異なり、機密情報を入力できたりプロンプトを社内共有できたりします。(開発背景については、こちらの記事をご覧ください。)

画像生成や認識機能や音声入力、エージェント機能なども実装しており、社内で幅広く使われています。
特に、社内で便利なプロンプトを共有する仕組みによって、社内での生成AI活用がより活発になりました。この後に紹介する事例も、この社内用ChatGPTを利用して、社内で共有されたものが多いです。
非エンジニアによるGAS作成やJiraの検索効率化
LLMの登場によって、Google App Script(GAS)のコードを書くハードルが非常に下がりました。今まではエンジニアではないとコードを書いたりエラー対処したりするのが難しい状態でした。LLMを活用すると、自分がしたいことを入力するとGASのコードを書いてくれ、エラーが出た場合もそれを入力すれば、対応策を教えてくれます。それによって、エンジニア以外の営業や医師、バックオフィスの人が、日々のスプレッドシートの処理の自動化をするGASコードを書いています。GASの活用までとは行かずとも、スプレッドシートの関数を書くサポートとして活用している社員も多くいます。

また、社内ではJiraを利用してプロジェクトを管理しており、その検索クエリ(JQL)をLLMで生成して効率化しています。JQLは馴染みが薄く、Webで検索しても欲しい情報が得られないことが多いです。LLMにやりたいことを入力すると候補が複数提案されます。それらを試すことで簡単にやりたいことを実現できます。
このように、LLM登場によって、非エンジニアがコードを書くハードルが下がり、自らの業務をエンジニアの手を借りずに自ら自動化するケースが増えてきました。
ギャル語による分かりやすい説明
ギャル語で難しい用語や文章を説明してもらっています。
例えば、ChatGPTのパラメータのTempartureに関しての回答は次のようになります。

社員からは、次のような声が上がっています。
法律文章などを噛み砕いて教えてくれるのでとても分かりやすい
テンション高く回答してくれるのでなんだか嬉しい
何回質問しても嫌な顔せず、すごく丁寧に教えてくれる
社内での生成AI活用の浸透を促進させるためには、このようなシンプルだけど、便利さを体感しやすいものを広めていくことが重要だと思います。エンジニアはプログラミングにおいて便利さを感じやすいですが、エンジニア以外では、このような事例が重要になってきます。
外部資料の調査・整理
市場調査や技術動向のキャッチアップなど、情報を検索してそれを要約するタスクはたくさんあります。それらを効率化する目的で、生成AIを活用しています。主に、使用しているのは、ChatGPT+検索系のプラグイン、ChatGPT+ファイルアップロード、Bing、Perplexityを活用しています。
また、ChatGPTでは画像をアップロードして文字起こししてもらうことができます。そのため、資料や論文の図表の内容を簡単に整理してまとめることができます。

英語IDの提案
作成したコンテンツをシステムに入稿する際に、英語のIDを付与して社内で管理しています。例えば、「片頭痛の原因」の場合は、「migraine_causes」です。英語IDには次のような命名規則があります。
半角英数字、アンダースコア(_)を用いた文字列のみ指定
括弧()や!などの記号は使えない
なるべく4単語におさめたい
今までは、人手でDeepLなどを駆使して命名していましたが、地味に時間がかかっていました。そこで、社内用ChatGPTで、英語ID提案プロンプトを作成し、それを社内や業務委託の方にも共有しました。英語ID化したいタイトルを大量に入力しても、瞬時にルールに則った英語IDを提案してくれます。

BigQueryでのLLM活用
Ubieでは様々なデータがGoogleのBigQuery(BQ)に蓄積されています。BQでは、SQL上で簡単にLLMを利用することができます。その機能を使って、ユーザーの検索意図をSQLだけで分析し、サイト改善やSEO強化に活用しました。詳細は、こちらの記事に書いてありますので、ここでは概要だけ説明します。
UbieのWebアプリでは、ユーザーがGoogleで「肺炎について知りたい」や「目黒区の病院」などのキーワードで検索して流入します。Webアプリの各ページに流入したキーワードを分類することで、そのページの改善の示唆を得ることができます。例えば、このページに関しては病院について知りたいユーザーが多いため、病院についてのコンテンツも増やすなどです。
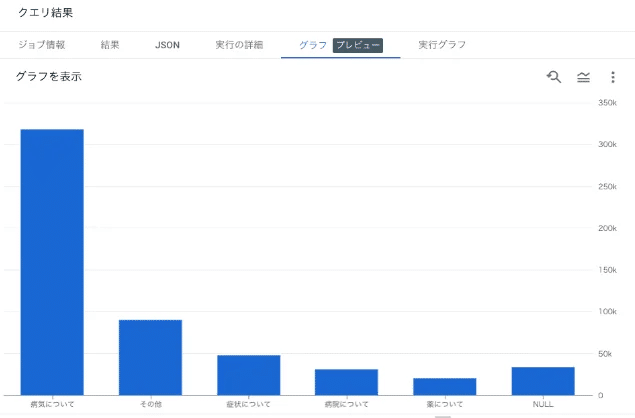
Googleでの検索がキーワードがBQのテーブルに入っている場合は、次のような魔法のようなSQLクエリを書くだけで、キーワードを「病気について」「症状について」などの11個の目的に分類してくれます。
SELECT
*
FROM
ML.GENERATE_TEXT( MODEL `llm-sandbox-dummy.llms.llm_v1`,
(
SELECT
keyword,
CONCAT( 'textに対応するintentを以下のカテゴリの中からふさわしいものを選んでください。 text:', keyword,
"""intent: 「病気について」「症状について」「診断について」「検査について」「治療について」「薬について」「健康診断について」「手続きや支援について」「受診について」「病院について」「その他」
# 出力形式
{"text": string , "intent": string}
# 出力例
{"text": "カレーライス", "intent": "その他"}
{"text": "虫垂炎", "intent": "病気について"}
""") AS prompt
FROM
`llm-sandbox-dummy.llms.search_keywords`
),
STRUCT(
0.8 AS temperature,
1024 AS max_output_tokens,
0.95 AS top_p,
40 AS top_k,
TRUE AS flatten_json_output
)
)BQを使うと結果をその場でグラフ表示してくれます。この結果をもとに、このページは、病院について知りたいユーザーが多いので、その内容を増やそうなどのアクションを取ることができます。
この分類タスクを従来の機械学習で構築しようとすると、データの収集やモデルの学習、システム実装に数ヶ月ほどかかります。一方で、LLMを活用すると学習データの整備がほぼ要らなくなり、モデル学習もプロンプトの日本語を修正するだけです。また、BQを利用することで、SQLだけでLLMを利用できるので、バッチ処理への組み込みも簡単です。

このBQ×LLMの取り組みは、最近プレスリリースを出した「Ubie US進出1年足らずで200万回利用 」の裏側を支えています。今回のような分類だけでなく、Embedding機能を組み合わせて、キーワードの生成などをしています。これによって、人手だけでは難しいコンテンツ改善やSEO強化が大量に高速に可能になっています。
データ分析業務における質と効率の向上
データ分析業務においてもLLMは大活躍しています。LLMで情報を正規化・抽出することで、今まで分析が難しかった・時間がかかった非構造化データが、分析可能なデータとして利用できます。また、そのような分析の1要素にLLMを活用するだけでなく、分析の全プロセスをLLMエージェントにしてもらうケースもあります。ツールとしては、Open InterpreterやLangChain、Streamlitを活用しています。それらの使い勝手を簡単に紹介します。
Open Interpreterは、自由度が高く柔軟に対応してくれます。実際に、とある施策の効果検証を因果推論のライブラリを利用して正しく行えるかを試しています。
「あなたは、因果推論の知識を持ち合わせているデータサイエンティストです。 ある企業のキャンペーンが、ユーザーの再訪問に繋がっているかの効果検証を行いたいです。 pd.read_csv("data.csv")でユーザーのデータを読み込んでください。性別、行動種別は、カテゴリー変数なので、適切に処理してください。 因果推論のライブラリdowhyを利用して、キャンペーンが再訪問にどれだけ影響をあたえているかの効果検証をしてください」
このような指示をすると必要なライブラリのダウンロードから、データの読み込み、効果検証までしてくれます。さらに追加して、「傾向スコアマッチングでも分析して」などの依頼にも柔軟に対応してくれます。
しかし、Chatの途中でフリーズしてしまうことが多かったり、毎回ライブラリーをダウンロードしたりします。そのため、Open Interpreterの使い方としては、ざっくり分析の一連のコードのドラフトを書いてもらって、ある程度コードが固まったら、それをColab notebookに分析テンプレートとして保存して、それをBIチーム内で共有するような使い方をしています。過去にしたことがある分析に関しては素早くドラフトコードを書いてくれて便利ですが、データ分析をしたことがない人がOpen Interpreterを利用して因果推論などをするにはまだハードルが高いです。
Open Interpreterの自由度が高いため、分析に特化した用途でLangChainのpandas-dataframe-toolkitの検証も進めています。BQで取得したデータを渡すことで、それに対して、自然言語で集計や可視化を柔軟にすることができます。Colab notebookでの共有も便利ですが、データサイエンティスト以外の利用を促進させるためにStreamlitでのWebアプリ化もしています。ただ、Streamlitではグラフの可視化の種類が限られているのが、課題でもあります。
このようにLLMを活用することで、分析の高速化やLLMによる情報の正規化・抽出による分析の質の向上に繋がっています。実際に、特定の分析業務では、LLMを活用したことで、捌ける分析案件が2倍になることもありました。
Cursorエディタ
社内では、すでにGitHub Copilotを利用していて、40%ほどの生産性が向上しています。(詳細はこちらの記事をご覧ください。)
Cursorは、VSCodeをベースにしたAIファーストのエディタです。OpenAI社が800万ドルを投資したことでも有名です。VSCodeベースなので、VSCodeの設定やプラグインも使用でき、VSCodeから非常に簡単に移行できます。
Cursorでは、至る所でLLMの恩恵を受けれる設計になっており、コードの生成・検索・テストが高速に柔軟にできるようになっています。また、外部のドキュメントを読み込ませることが可能(※)で、それをもとにコードを生成させることが可能です。例えば、特定のライブラリの利用ガイドを読み込ませると、そのライブラリを使用したコードを簡単に作成ができます。
(※コードやドキュメントのEmbeddingがVector DBに保存されて活用できます。)

実際に業務で活用している社員も増えてきました。Cursorの活用事例としては、「LightdashというBIツールをTerraformで管理できるようにした」というプロジェクトがあります。LightdashのドキュメントをCursorに読み込ませることで、開発が高速に進み、OSSとしてコードを公開することもできました。
まとめ
以上が、Ubie社内で活用している生成AIの事例になります。社内では、賞金総額50万円ほどの生成AIのアイデアソンを開催するなどして、生成AIの利用促進を進めています。最後に、LLMアプリケーションエンジニアの求人のご紹介をしますので、ご興味ある方はぜひご連絡ください。
LLMアプリケーションエンジニア
Ubieでは、LLMのプロダクト活用と生産性向上をより加速させるために、LLMアプリケーションエンジニアを募集しています。このポジションでは、LLMのプロダクト活用や社内生産性向上の観点で、顧客や社員にニーズをヒアリングして、プロトタイプを作成し、改善していくというプロセスを高速に回していきます。新技術に対する興味関心が高く、それらを素早く実装して顧客に届けたい方からのご応募を待っています。詳細は、下記のリンクよりご覧ください。
その他の職種でも一緒に働きたいメンバーをまだまだ募集しています。
興味を持っていただけた方はカジュアル面談もご用意しています。お気軽にご登録お待ちしています。
【提供するサービス一覧】
▽生活者向け 症状検索エンジン「ユビー」
日本版:https://ubie.app/
US版:https://ubiehealth.com
▽医療機関向け「ユビーメディカルナビ」
https://intro.dr-ubie.com/