
データマーケティングの強い味方!?BigQueryと大規模言語モデル(LLM)の統合で始める検索意図分析の事例

初めまして、Ubie Product Platformのグロースチームでエンジニアをしてる田口です。「健康が空気のように自然になる世界」を目指し、症状検索による発症から受診までのサポートするサービス症状検索エンジン「ユビ―」を提供しています。
さて、サービスを成長させる上で、ユーザーの行動を理解することが不可欠です。ユーザーが何を求め、どのようにサービスを利用しているのかを知ることで、サービスの満足度を向上させるための改善策が見えてきます。
しかし、大規模なウェブサイトの場合、分析すべき検索クエリが膨大になっているという課題がありました。
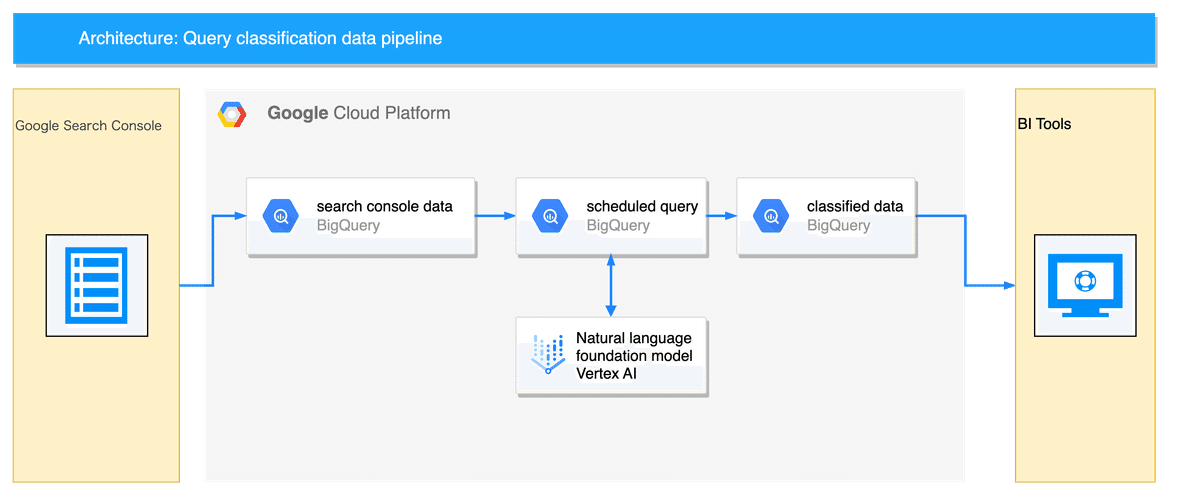
今回は、ML.GENERATE_TEXTを用いてプロンプトベースのデータパイプラインを作り、ユーザーの検索意図分析を行ってみた事例を紹介します。
ML.GENERATE_TEXTとは
ML.GENERATE_TEXTは、VertexAIの自然言語基盤モデルをBigQueryから呼び出す機能です。これにより、SQLだけで自然言語生成が可能になります。
詳細については、下記のドキュメントを参照してください。
プロンプトを調整すれば、以下のタスクをSQLだけで処理でき、非常に便利な機能です。
分類
感情分析
エンティティ抽出
抽出型質問応答
要約
異なるスタイルでの文章書き換え
広告コピー生成
コンセプトアイデアの発想
分類させたいデータを準備する
まず、Go・Do・Buy・Knowの4つの検索クエリに分類するタスクから始めてみました。これは検索意図分析でよく使われる方法です。
4つの検索クエリ
●Doクエリ …何かをしたいという意図が含まれているアクションに結びつくクエリ
●Knowクエリ …情報を知りたい、問題を解決したいという意図のクエリ
●Goクエリ …「特定のサイトに行きたい」という意図のクエリ (物理的にどこかに行くのとは違う)
●Buyクエリ …Buyクエリは、Doクエリの中でも「買いたい、購入したい」という意図のクエリ
ユーザーの検索意図を分類するためには検索クエリが必要ですので、Google Search Consoleのデータを利用します。
Google Search ConsoleとBigQueryはデータ転送機能を提供されており、BigQueryのプロジェクトがある場合、データの連携を容易に行うことができます。
設定メニューから一括エクスポートを選択し、エクスポート先を設定するだけです。ただし、転送設定は1つしか作成できないことに注意してください。


詳しい作業内容やGoogle Cloud Platformの設定については、下記のドキュメントを参照してください。
SQLでMODELを作成する
VertexAIのリモートモデルを作成します。モデルの作成もSQLで行うことができます。remote_service_typeにはCLOUD_AI_LARGE_LANGUAGE_MODEL_V1を指定します。
-- SQL
CREATE OR REPLACE MODEL `<your-project-id>.<your-dataset-id>.<your-model-id>`
REMOTE WITH CONNECTION `<your-project-id>.<your-location-id>.<your-connection-id>`
OPTIONS (remote_service_type = 'CLOUD_AI_LARGE_LANGUAGE_MODEL_V1');詳しいリモートモデルの設定については、下記のドキュメントを参照してください。
SQLで検索クエリの分類を行う
まず、プロンプトを準備します。今回は、与えられた検索クエリに対応するプロンプトを生成する関数を、柔軟な表現が可能なJavaScript UDFを利用して実装しました。
-- SQL
CREATE TEMP FUNCTION
CreatePrompt(text STRING)
RETURNS STRING
LANGUAGE js AS r"""
return `
以下のtextをintentに分類しなさい。intentのみ出力すること。
intent:
Do 何らかのアクションをとりたいという意図を持っている
Know 情報を知りたいという意図を持っている
Go 自分の目的とするWebサイトに行きたい、という意図を持っている
Buy 特定の物、商品などを買いたいという意図を持っている
Other 分類に迷うもの
出力例:
text: "Google Chrome ダウンロード"
intent: Do
text: "ユビー"
intent: Go
text: "BigQuery 活用事例"
intent: Know
text: "Google Cloud Platform 料金"
intent: Buy
text: ${text}
intent:
`.trim();
""";ML.GENERATE_TEXTの呼び出し方は以下の通りです。
1つ目のポイントは、flatten_json_outputをオプションとして渡すことでJSONではなく出力されたテキストをレスポンスで受け取っています。
2つ目のポイントは、ML.GENERATE_TEXTにpromptだけでなく、*を指定している点です。その結果、元々のデータとLLMで生成された文章のデータが両方含まれた結果が返されます。後で分析する際に元々のデータが残っていると便利です。
-- SQL
SELECT
*
FROM
ML.GENERATE_TEXT( MODEL `<your-project-id>.<your-dataset-id>.<your-model-id>`,
(
SELECT
CreatePrompt(query) AS prompt,
*,
-- 元々のsearchdata_site_impressionのカラムも全てSELECT結果に含める
FROM
`<your-project-id>.<your-dataset-id>.searchdata_site_impression`
),
STRUCT( 0.8 AS temperature,
100 AS max_output_tokens,
0.95 AS top_p,
40 AS top_k,
TRUE AS flatten_json_output ) )データ量が多いと時間がかかります。最初は件数を絞り、プロンプトやパラメータを調整することをおすすめします。
最終的なSQLは以下の通りです。
-- SQL
CREATE TEMP FUNCTION
CreatePrompt(text STRING)
RETURNS STRING
LANGUAGE js AS r"""
return `
以下のtextをintentに分類しなさい。intentのみ出力すること。
intent:
Do 何らかのアクションをとりたいという意図を持っている
Know 情報を知りたいという意図を持っている
Go 自分の目的とするWebサイトに行きたい、という意図を持っている
Buy 特定の物、商品などを買いたいという意図を持っている
Other 分類に迷うもの
出力例:
text: "Google Chrome ダウンロード"
intent: Do
text: "ユビー"
intent: Go
text: "BigQuery 活用事例"
intent: Know
text: "Google Cloud Platform 料金"
intent: Buy
text: ${text}
intent:
`.trim();
""";
SELECT
*
FROM
ML.GENERATE_TEXT( MODEL `<your-project-id>.<your-dataset-id>.<your-model-id>`,
(
SELECT
CreatePrompt(query) AS prompt,
*,
-- 元々のsearchdata_site_impressionのカラムも全てSELECT結果に含める
FROM
`<your-project-id>.<your-dataset-id>.searchdata_site_impression`
),
STRUCT( 0.8 AS temperature,
100 AS max_output_tokens,
0.95 AS top_p,
40 AS top_k,
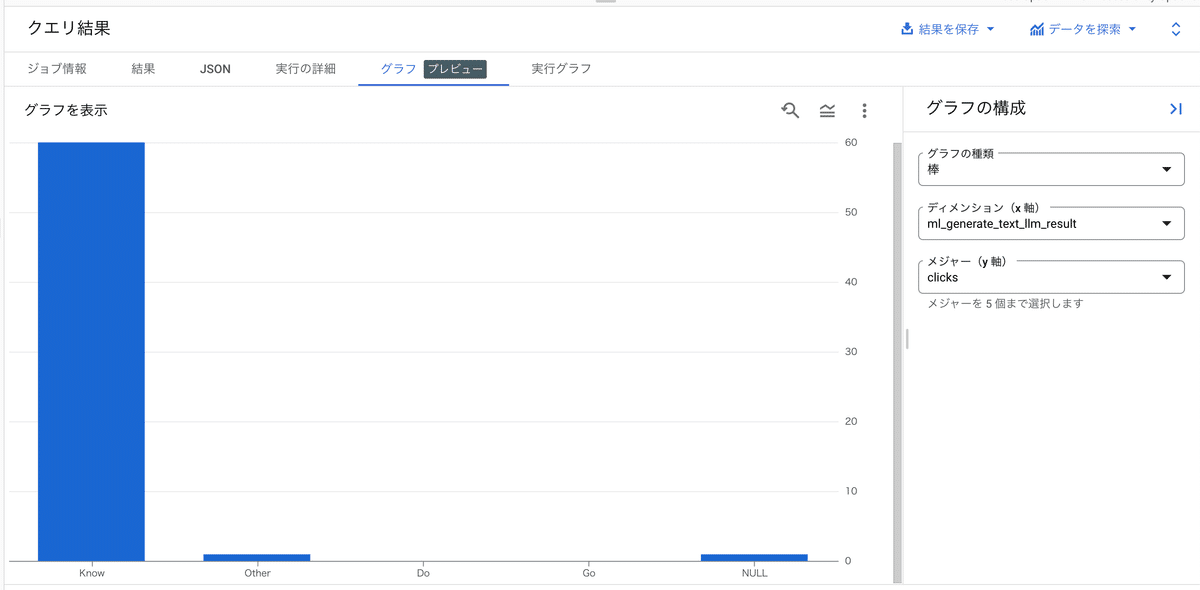
TRUE AS flatten_json_output ) )処理が完了したらBigQueryのグラフ機能を用いて、分類結果を確認してみます。問題が見つかった場合は、プロンプトを改善します。生成された文章はml_generate_text_llm_resultカラムに格納されています。
いくつかサンプリングして実行した結果、症状検索エンジン「ユビ―」では、Knowクエリが多い結果となりました。医療情報の提供サービスですので妥当な結果が出ていそうです。
Knowクエリの検索意図を更に分類する
Knowクエリが多いことは元々予想していたので、更にそれを細分化し、ユーザーがどのような情報を求めているかを分析させてみました。
症状検索エンジン「ユビ―」が提供する情報にはカテゴリが付与されています。それにより、検索クエリをカテゴリごとに分類できます。
プロンプトの変更だけで、さまざまなユースケースにも対応できて素晴らしいですね。
-- SQL
CREATE TEMP FUNCTION
CreatePrompt(text STRING)
RETURNS STRING
LANGUAGE js AS r"""
return `
以下のtextをintentに分類しなさい。intentのみ出力すること。
intent:
病気について
症状について
診断について
検査について
治療について
薬について
健康診断について
手続きや支援について
受診について
病院について
その他
出力例:
text: "帯状疱疹"
intent: 病気について
text: "ユビー"
intent: その他
text: "お腹が痛い"
intent: 症状について
text: ${text}
intent:
`.trim();
""";結果から、私たちが設定したカテゴリに当てはまらないものがあることが分かりました。これらは、予想外の検索クエリから生じており、潜在的なユーザーニーズの理解に役立ちました。数万もの検索クエリから注目すべき特定の検索クエリに着目するのは人間の手作業では限界があったのではないでしょうか。

また、検索クエリのImpressionやCTRと検索意図の関連性を分析することでも、新たな示唆を得られるかもしれません。
分類の永続化とスケジュール化
分類した結果を基に更に色々と分析したくなります。しかし、毎回ML.GENERATE_TEXTを実行すると時間とコストがかかります。分類結果をテーブルに保存し、分析用途ではそちらを参照するのが便利です。
また、Google Search Consoleのデータは毎日自動で連携されますが、それを毎日手動で処理するのも大変です。プロンプトのサイズやレコード数によっては、時間が大幅にかかります。今回はサンプリングした1000個の検索クエリを分類するのに約16分かかりました。
そこで、処理をスケジュール化し、夜間に自動計算させる設定をしました。その結果はBigQueryテーブルとして保存されます。
BigQueryのコンソールから、スケジュールボタンを押し設定するだけです。

詳しいSQLのスケジューリングの設定については、下記のドキュメントを参照してください。
まとめと今後の展望
BigQueryとLLMの統合によって、SQLだけで検索意図分析を実施した事例を紹介しました。
ここまでの操作は、基本的にBigQuery上の操作だけで完結しており、従来のように機械学習モデルの作成や、バッチアプリケーションの準備は不要です。プロンプトをチューニングすることで、多くのタスクをこなせる柔軟性が大きなメリットだと感じました。
すぐに思いつくだけでも、検索意図の分析以外にプロンプトのチューニングで以下のようなタスクが実現できそうです。
問い合わせフォームの内容を要約する
商品レビューの感情分析
BigQueryにデータさえあれば、SQLだけで手軽に実行できるのでまた試してみたいと思います。
現在、ML.GENERATE_TEXTはプレビュー版ですが、今後の発展に大いに期待します。
注意点
大規模言語モデル(LLM)の特性として予期しない結果を返す可能性があります。また、有害なカテゴリでは制限がかかる場合があります。
詳しくは責任あるAIに関しての下記のドキュメントを参照してください。
宣伝
グロースチームでは、GenerativeAIの活用も含め、「健康が空気のように自然になる世界」を目指して、企画、開発、分析など様々な業務に取り組んでいます。
開発業務だけにとどまらず、サービスグロースのためのあらゆる挑戦に興味がある方はぜひお話しましょう。
twitter / pittaで募集しています。
参考資料
続編
続編を書きました。コンテンツの類似度を計算してコンテンツやキーワードの重複を計算してみました。