
BigQueryと大規模言語モデル(LLM)の統合で始めるテキストエンべディングを用いたSEO改善の事例

この記事は Ubie Engineering Advent Calendar 2023 の 19 日目の記事です。昨日はTatsuro Nakamuraによる「強い開発チームを作るためのコツ〜課題の抽出・可視化・共有のプラクティス〜 」でした。
初めまして、Ubie Product Platformのグロースチームでエンジニアをしている田口です。「健康が空気のように自然になる世界」を目指し、症状検索による発症から受診までのサポートするサービス症状検索エンジン「ユビ―」を提供しています。
前回BigQueryとサーチコンソールを連携し、LLMを使ってキーワードの分類タスクを行った記事を書きました。
今回は続きとして、分類した結果を元に症状検索エンジン「ユビー」が生活者のニーズを捉えたコンテンツを提供できているのか、セマンティック検索の考え方に沿った分析をテキストエンべディングを活用して自動化した事例を紹介します。
ML.GENERATE_TEXT_EMBEDDINGとは
ML.GENERATE_TEXT_EMBEDDINGを利用すると、SQLだけでBigQuery テーブルに保存されているテキストを埋め込むことができます。
テキスト エンベディングを使うと次のタスクを行うことができます。
セマンティック検索
推奨
分類
クラスタリング
外れ値検出
今回は特にセマンティック検索に着目して活用してみました。
詳細については、下記のドキュメントを参照してください。
セマンティック検索とは
セマンティック検索とは、検索文から検索ユーザーの意図や目的を検索エンジンが適切に理解し、ユーザーが求めるものに即した検索結果を提供するための技術のことです。
セマンティック検索は、今やウェブ検索の基本ともいえる重要な要素です。流入キーワードと自社コンテンツの類似度を分析することで、読者のニーズに合ったコンテンツを提供し、より効果的な情報発信が可能となります。
テキストエンベディングとは、テキストの高次ベクトル表現です。2 つのテキストが意味的に類似している場合、それぞれのエンベディングはエンベディング ベクトル空間内で互いに近接しています。流入キーワードと自社コンテンツの類似度を比較することで、検索意図に近しいページを計算することができます。
計算した検索意図に近いページと、実際にキーワードを獲得しているページを比較することで、キーワードやコンテンツの重複を検知することができます。
SQLでモデルを作成する
VertexAIのリモートモデルを作成します。モデルの作成もSQLで行うことができます。remote_service_typeにはCLOUD_AI_TEXT_EMBEDDING_MODEL_V1を指定します。
-- SQL
CREATE OR REPLACE MODEL `<your-project-id>.<your-dataset-id>.<your-model-id>`
REMOTE WITH CONNECTION `<your-project-id>.<your-location-id>.<your-connection-id>`
OPTIONS (REMOTE_SERVICE_TYPE = 'CLOUD_AI_TEXT_EMBEDDING_MODEL_V1');詳しいリモートモデルの設定については、下記のドキュメントを参照してください。
まずは大きなカテゴリでキーワードを分類する
ここは前回の記事の内容と変わりありませんが、事前にキーワードのリストをある程度のカテゴリで分類しておきます。
症状検索エンジン「ユビー」は気になる症状があったら調べて見るサービスなので特に症状について気にしていそうなキーワードをまず事前にフィルタリングします。
事前に分類できるものは分類しておいたほうが、コンテンツの類似度計算の計算量が減るのでおすすめです。
CREATE TEMP FUNCTION
CreatePrompt(text STRING)
RETURNS STRING
LANGUAGE js AS r"""
return `
以下のtextをintentに分類しなさい。intentのみ出力すること。
intent:
病気について
症状について
診断について
検査について
治療について
薬について
健康診断について
手続きや支援について
受診について
病院について
その他
出力例:
text: "帯状疱疹"
intent: 病気について
text: "ユビー"
intent: その他
text: "お腹が痛い"
intent: 症状について
text: ${text}
intent:
`.trim();
""";
CREATE OR REPLACE TABLE `<your-project-id>.<your-dataset-id>.searchdata_url_impression_with_intent`
SELECT
*
FROM
-- このモデルは `CLOUD_AI_LARGE_LANGUAGE_MODEL_V1` を利用してください。
ML.GENERATE_TEXT( MODEL `<your-project-id>.<your-dataset-id>.<your-model-id>`,
(
SELECT
CreatePrompt(query) AS prompt,
*,
FROM
`<your-project-id>.<your-dataset-id>.searchdata_site_impression`
QUALIFY
data_date = MAX(data_date) OVER() -- 全件だと流石に多すぎるので最新のデータを使う
),
STRUCT( 0.8 AS temperature,
100 AS max_output_tokens,
0.95 AS top_p,
40 AS top_k,
TRUE AS flatten_json_output ) )キーワードを埋め込む
ML.GENERATE_TEXT_EMBEDDINGを使ってキーワードのベクトルを得ます。
CREATE OR REPLACE TABLE `<your-project-id>.<your-dataset-id>.searchdata_url_impression_with_embedding` AS
SELECT
*
FROM
-- このモデルは `CLOUD_AI_TEXT_EMBEDDING_MODEL_V1` を利用してください
ML.GENERATE_TEXT_EMBEDDING( MODEL `<your-project-id>.<your-dataset-id>.<your-model-id>`,
(
SELECT
*,
query AS content
FROM
`<your-project-id>.<your-dataset-id>.searchdata_url_impression_with_intent`
WHERE
ml_generate_text_llm_result LIKE "%症状について%" -- 症状に関連するキーワードのみ
),
STRUCT(TRUE AS flatten_json_output))完了するとtext_embeddingカラムにベクトルを得ることができます。
ページコンテンツを埋め込む
Ubieでは分析環境のBigQueryにページコンテンツそのものや、メタデータをエクスポートしています。もし、BigQueryにデータがない場合は手動でアップロードすることもできます。
BigQuery上に自社データを集約することで、サーチコンソールのデータだけではできない、自社データと掛け合わせた分析を行うことができます。
キーワードと同様にページコンテンツも埋め込みを行います。
CREATE OR REPLACE TABLE `<your-project-id>.<your-dataset-id>.content_table_with_embedding` AS
SELECT
*
FROM
-- このモデルは `CLOUD_AI_TEXT_EMBEDDING_MODEL_V1` を利用してください
ML.GENERATE_TEXT_EMBEDDING( MODEL `<your-project-id>.<your-dataset-id>.<your-model-id>`,
(
SELECT
*,
html AS content
FROM
`<your-project-id>.<your-dataset-id>.content_table`),
STRUCT(TRUE AS flatten_json_output))キーワードとページコンテンツの類似度を計算する
キーワードとページコンテンツのコサイン類似度を計算し、キーワードに対してもっとも類似度の高いページコンテンツを計算します。
ML.DISTANCE関数を利用することで簡単に計算することができます。
WITH
calc_ml_distance AS (
SELECT
a.content AS keyword,
a.url AS actual_url,
b.content AS similar_content,
b.url AS similar_url,
ML.DISTANCE(a.text_embedding, b.text_embedding, 'COSINE') AS distance,
FROM
`<your-project-id>.<your-dataset-id>.searchdata_url_impression_with_embedding` AS a,
`<your-project-id>.<your-dataset-id>.content_table_with_embedding` AS b
)
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY keyword ORDER BY distance) AS rank
FROM
calc_ml_distance
QUALIFY
rank = 1
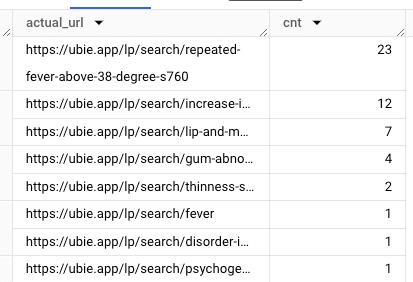
得られた結果をもとに、ある発熱のページに関して深掘りして見てみると、発熱系のキーワードが複数のページにまたがっている事がわかりました。
この結果を参考に、キーワードやコンテンツの重複を発見し、ユーザー体験向上のための記事品質の改善活動を行っています。
まとめ
BigQueryを使ったテキストエンべディングでSEOを改善した事例を紹介しました。
テキストエンベディングや、コサイン類似度の比較も機械学習モデルの作成や、バッチアプリケーションの準備は不要です。
アイデア次第でセマンティック検索以外にも、記事のレコメンデーションやクラスタリングなどにも活用できそうです。
今回は流入キーワードと自社コンテンツの類似度を計算しましたが、キーワード同士やコンテンツ同士の比較でも、示唆が得られるかもしれません。
自社データをBigQueryに集約することでサーチコンソールだけではできなかった分析が可能になります。
宣伝
グロースチームでは、GenerativeAIの活用も含め、「健康が空気のように自然になる世界」を目指して、企画、開発、分析など様々な業務に取り組んでいます。
開発業務だけにとどまらず、サービスグロースのためのあらゆる挑戦に興味がある方はぜひお話しましょう。
twitter / pitta で募集しています。