【第4章予測】練習問題4.5.2「メキシコにおける選挙と条件付き現金給付プログラム」

1.データセット
(1)データセット
・第4章の練習問題を解く際に使うデータセットは、以下のリンク先からダウンロードできる。
(2)元論文
・この練習問題の元論文を参考のためリンクを貼っておく。
2.練習問題4.5.2「メキシコにおける選挙と条件付き現金給付プログラム」
(1)簡易的な方法による条件付き現金給付プログラムの効果推定
<投票率(変数t2000)への影響>
①トリートメントグループの投票率の平均値は約68.08% 。一方、コン
トロールグループの平均値は約63.81%。
②各グループへの割当がランダムに行われたと仮定すれば、条件付き現
金給付プログラムは約4.26%も投票率を引き上げる。
③線形回帰モデルの結果は、切片がコントロールグループの平均値と、
予測変数の係数は平均的なトリートメント効果と一致している。
<得票率(変数pri2000s)への影響>
①トリートメントグループにおける与党の得票率の平均値は約38.1% 、
コントロールグループの平均値は約34.5%
②各グループへの割当がランダムに行われたと仮定すれば、条件付き現
金給付プログラムは約3.62%も得票率を引き上げる。
③線形回帰モデルの結果は、切片がコントロールグループの平均値と、
予測変数の係数は平均的なトリートメント効果と一致している。
> progresa <- read.csv("progresa.csv")
> dim(progresa)
[1] 417 20
> mean(progresa$t2000[progresa$treatment == 1])
[1] 68.08451
> mean(progresa$t2000[progresa$treatment == 0])
[1] 63.81483
> mean(progresa$t2000[progresa$treatment == 1]) - mean(progresa$t2000[progresa$treatment == 0])
[1] 4.269676
> fit1 <- lm(t2000 ~ treatment,data = progresa)
> fit1
Call:
lm(formula = t2000 ~ treatment, data = progresa)
Coefficients:
(Intercept) treatment
63.81 4.27
> mean(progresa$pri2000s[progresa$treatment == 1])
[1] 38.11145
> mean(progresa$pri2000s[progresa$treatment == 0])
[1] 34.48895
> mean(progresa$pri2000s[progresa$treatment == 1]) - mean(progresa$pri2000s[progresa$treatment == 0])
[1] 3.622496
> fit2 <- lm(pri2000s ~ treatment,data = progresa)
> fit2
Call:
lm(formula = pri2000s ~ treatment, data = progresa)
Coefficients:
(Intercept) treatment
34.489 3.622 (2)重回帰モデルによる条件付き現金給付プログラムの効果推定
<投票率(変数t2000)への影響>
①トリートメントの係数は約4.59%で単回帰モデルと同水準の値。
なお、重回帰モデルの係数の方が約0.33%大きい。
②但し、このモデルの調整済決定係数は0.062と小さく、説明力は低い。
<得票率(変数pri2000s)への影響>
①トリートメントの係数は約2.92%で単回帰モデルと同水準の値。
なお、重回帰モデルの係数の方が約0.7%小さく効果を推定している。
②このモデルの調整済決定係数約0.20は、結果変数が投票率の場合より
も大きいが、依然として説明力は低い。
> fit3 <- lm(t2000 ~ treatment + avgpoverty + pobtot1994 + votos1994 + pri1994 + pan1994 + prd1994,data = progresa)
> fit3
Call:
lm(formula = t2000 ~ treatment + avgpoverty + pobtot1994 + votos1994 +
pri1994 + pan1994 + prd1994, data = progresa)
Coefficients:
(Intercept) treatment avgpoverty pobtot1994 votos1994 pri1994 pan1994 prd1994
64.011735 4.549445 0.310255 -0.001213 -0.026152 0.036055 0.026538 0.017575
> fit3.summary <- summary(fit3)
> fit3.summary$adj.r.squared
[1] 0.06273301
> fit4 <- lm(pri2000s ~ treatment + avgpoverty + pobtot1994 + votos1994 + pri1994 + pan1994 + prd1994,data = progresa)
> fit4
Call:
lm(formula = pri2000s ~ treatment + avgpoverty + pobtot1994 +
votos1994 + pri1994 + pan1994 + prd1994, data = progresa)
Coefficients:
(Intercept) treatment avgpoverty pobtot1994 votos1994 pri1994 pan1994 prd1994
37.9500862 2.9277395 0.5329801 -0.0004996 -0.0417278 0.0624589 -0.0487349 -0.0287363
> fit4.summary <- summary(fit4)
> fit4.summary$adj.r.squared
[1] 0.2072516(3)代替モデルによる条件付き現金給付プログラムの効果推定
<投票率(変数t2000)への影響>
①トリートメントの係数は約-0.15%と実質的に影響をあたない水準で、
元の重回帰モデルと異なる結果になっている。
②調整済決定係数の値は約0.68と元のモデルよりもかなり改善しており
説明力が高いモデルになっている。
<得票率(変数pri2000s)への影響>
①トリートメントの係数は約0.23%と実質的に影響を与えない水準で、
元の重回帰モデルと異なる結果になっている。
②また、調整済決定係数は約0.57と元のモデルよりも改善しており、
説明力が高くなっている。
> fit6 <- lm(t2000 ~ treatment + avgpoverty + I(log(pobtot1994)) + t1994 + pri1994s + pan1994s + prd1994s,data = progresa)
> fit6
Call:
lm(formula = t2000 ~ treatment + avgpoverty + I(log(pobtot1994)) +
t1994 + pri1994s + pan1994s + prd1994s, data = progresa)
Coefficients:
(Intercept) treatment avgpoverty I(log(pobtot1994)) t1994
19.7984 -0.1530 2.8621 -3.2471 0.6605
pri1994s pan1994s prd1994s
0.1943 0.6374 0.3065
> fit6.summary <- summary(fit6)
> fit6.summary$adj.r.squared
[1] 0.6868331
> fit7 <- lm(pri2000s ~ treatment + avgpoverty + I(log(pobtot1994)) + t1994 + pri1994s + pan1994s + prd1994s,data = progresa)
> fit7
Call:
lm(formula = pri2000s ~ treatment + avgpoverty + I(log(pobtot1994)) +
t1994 + pri1994s + pan1994s + prd1994s, data = progresa)
Coefficients:
(Intercept) treatment avgpoverty I(log(pobtot1994)) t1994
35.85174 0.23547 2.47163 -4.62934 0.03257
pri1994s pan1994s prd1994s
0.51047 -0.18384 -0.05293
> fit7.summary <- summary(fit7)
> fit7.summary$adj.r.squared
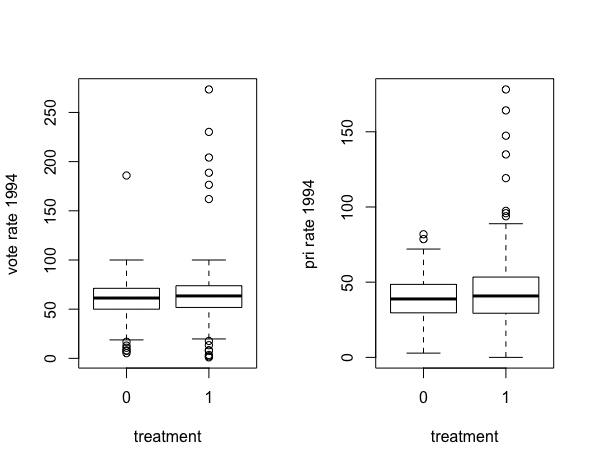
[1] 0.5721621(4)グループ別の予測変数の確認
①いずれの予測変数も第1四分位〜第3四分の範囲及び中央値は、コント
ロールグループとトリートメントグループで殆ど同じ。
②但し、トリートメントグループの方がコントロールグループより外れ
値を多く含んでいる。特に投票率とPRI支持率は高い外れ値が目立つ。
> par(mfrow = c(1,2),cex=1)
> boxplot(log(pobtot1994)~treatment,data = progresa,ylab = "log pobtot")
> boxplot(avgpoverty~treatment,data = progresa,ylab = "avgpoverty")
> boxplot(t1994~treatment,data = progresa,ylab = "vote rate 1994")
> boxplot(pri1994s~treatment,data = progresa,ylab = "pri rate 1994")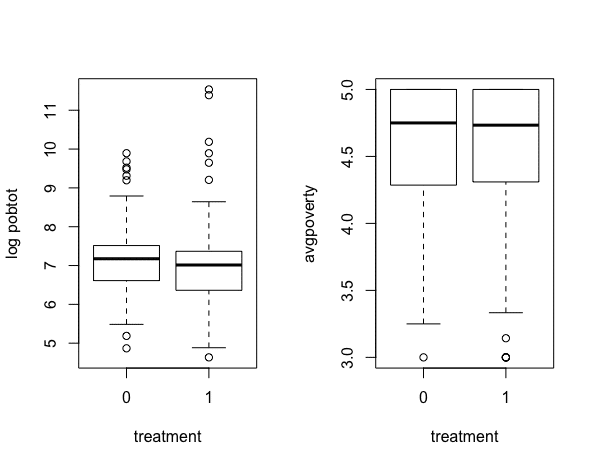
(5)予測変数の変更による重回帰モデルへの影響
<投票率(変数t2000r)への影響>
①トリートメントの係数は約-1.0%で、投票率に与える影響は小さい。
②調整済決定係数の値は約0.16と小さく、説明力が低い。
<得票率(変数pri2000v)への影響>
①トリートメントの係数は約0.8%で、得票率に与える影響は小さい。
②調整済決定係数は約0.47と上記の投票率のモデルよりは高いが、
このモデルによる得票率の説明力は半分程度になっている。
> fit8 <- lm(t2000r ~ treatment + avgpoverty + I(log(pobtot1994)) + t1994r + pri1994v + pan1994v + prd1994v,data = progresa)
> summary(fit8)
Call:
lm(formula = t2000r ~ treatment + avgpoverty + I(log(pobtot1994)) +
t1994r + pri1994v + pan1994v + prd1994v, data = progresa)
Residuals:
Min 1Q Median 3Q Max
-38.041 -4.555 0.029 5.010 29.069
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 33.47237 8.85553 3.780 0.000180 ***
treatment -1.08094 0.81683 -1.323 0.186465
avgpoverty -0.27734 0.88768 -0.312 0.754874
I(log(pobtot1994)) -0.27878 0.47487 -0.587 0.557487
t1994r 0.22238 0.03102 7.168 3.59e-12 ***
pri1994v 0.12473 0.05489 2.272 0.023586 *
pan1994v 0.27356 0.07257 3.770 0.000188 ***
prd1994v 0.11323 0.05790 1.955 0.051209 .
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 7.795 on 408 degrees of freedom
(1 observation deleted due to missingness)
Multiple R-squared: 0.1809, Adjusted R-squared: 0.1669
F-statistic: 12.87 on 7 and 408 DF, p-value: 5.603e-15
> fit9 <- lm(pri2000v ~ treatment + avgpoverty + I(log(pobtot1994)) + t1994r + pri1994v + pan1994v + prd1994v,data = progresa)
> summary(fit9)
Call:
lm(formula = pri2000v ~ treatment + avgpoverty + I(log(pobtot1994)) +
t1994r + pri1994v + pan1994v + prd1994v, data = progresa)
Residuals:
Min 1Q Median 3Q Max
-37.876 -7.686 1.072 7.461 34.758
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 50.22721 14.43904 3.479 0.000558 ***
treatment 0.80172 1.33185 0.602 0.547536
avgpoverty 3.19082 1.44737 2.205 0.028042 *
I(log(pobtot1994)) -2.59489 0.77428 -3.351 0.000879 ***
t1994r -0.08612 0.05058 -1.703 0.089421 .
pri1994v 0.35738 0.08950 3.993 7.73e-05 ***
pan1994v -0.48863 0.11832 -4.130 4.41e-05 ***
prd1994v -0.24158 0.09441 -2.559 0.010862 *
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 12.71 on 408 degrees of freedom
(1 observation deleted due to missingness)
Multiple R-squared: 0.4836, Adjusted R-squared: 0.4747
F-statistic: 54.58 on 7 and 408 DF, p-value: < 2.2e-16(6)貧困レベルによる平均トリートメント効果の差異
<投票率(変数t2000)への影響>
> fit10 <- lm(t2000 ~ treatment + I(log(pobtot1994)) + avgpoverty + I(avgpoverty^2) + treatment:avgpoverty + treatment:I(avgpoverty^2),data = progresa)
> summary(fit10)
Call:
lm(formula = t2000 ~ treatment + I(log(pobtot1994)) + avgpoverty +
I(avgpoverty^2) + treatment:avgpoverty + treatment:I(avgpoverty^2),
data = progresa)
Residuals:
Min 1Q Median 3Q Max
-41.389 -13.710 -2.435 7.475 280.248
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 125.832 186.017 0.676 0.499
treatment 34.809 211.509 0.165 0.869
I(log(pobtot1994)) -16.114 1.662 -9.693 <2e-16 ***
avgpoverty 29.018 85.369 0.340 0.734
I(avgpoverty^2) -3.794 9.790 -0.388 0.699
treatment:avgpoverty -18.037 98.477 -0.183 0.855
treatment:I(avgpoverty^2) 2.321 11.342 0.205 0.838
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 27.78 on 410 degrees of freedom
Multiple R-squared: 0.2051, Adjusted R-squared: 0.1935
F-statistic: 17.63 on 6 and 410 DF, p-value: < 2.2e-16
> par(mfrow = c(1,2))
> plot(x = 0:5,y = yT.hat,type = "l",xlim = c(-1,6),ylim = c(10,70),xlab = "avgpoverty",ylab = "t2000",col="blue")
> lines(x = 0:5 , y = yC.hat , lty ="dashed",col ="red")
> text(0.5,65,"Treatment",col="blue")
> text(2.5,35,"Control",col="red")
> plot(x = 0:5,y=yT.hat-yC.hat,type = "l",xlim = c(0,5),ylim = c(-10,40),xlab = "avgpoverty",ylab = "ATE")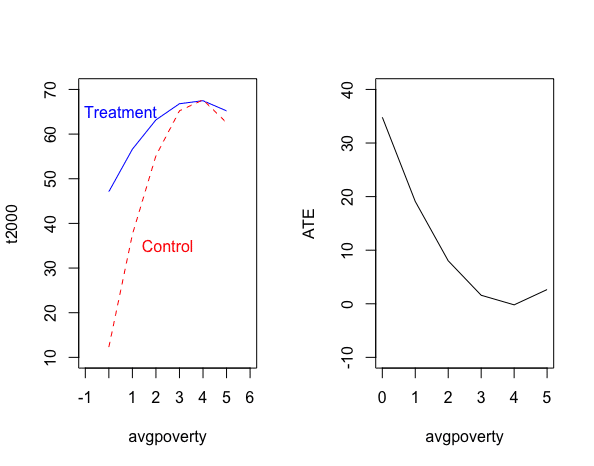
<得票率(変数pri2000s)への影響>
> fit11 <- lm(pri2000s ~ treatment + I(log(pobtot1994)) + avgpoverty + I(avgpoverty^2) + treatment:avgpoverty + treatment:I(avgpoverty^2),data = progresa)
> summary(fit11)
Call:
lm(formula = pri2000s ~ treatment + I(log(pobtot1994)) + avgpoverty +
I(avgpoverty^2) + treatment:avgpoverty + treatment:I(avgpoverty^2),
data = progresa)
Residuals:
Min 1Q Median 3Q Max
-34.498 -9.430 -1.569 7.553 98.038
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 36.7179 104.0801 0.353 0.724
treatment 109.0592 118.3435 0.922 0.357
I(log(pobtot1994)) -10.8381 0.9301 -11.652 <2e-16 ***
avgpoverty 33.1890 47.7658 0.695 0.488
I(avgpoverty^2) -3.6441 5.4776 -0.665 0.506
treatment:avgpoverty -51.4069 55.0998 -0.933 0.351
treatment:I(avgpoverty^2) 6.0420 6.3459 0.952 0.342
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 15.54 on 410 degrees of freedom
Multiple R-squared: 0.2897, Adjusted R-squared: 0.2793
F-statistic: 27.88 on 6 and 410 DF, p-value: < 2.2e-16
> par(mfrow = c(1,2))
> plot(x = 0:5,y = yT.hat2,type = "l",xlim = c(-1,6),ylim = c(-40,70),xlab = "avgpoverty",ylab = "pri2000s",col="blue")
> lines(x = 0:5 , y = yC.hat2 , lty ="dashed",col ="red")
> text(3.5,65,"Treatment",col="blue")
> text(0,35,"Control",col="red")
> plot(x = 0:5,y=yT.hat2-yC.hat2,type = "l",xlim = c(0,5),ylim = c(-5,110),xlab = "avgpoverty",ylab = "ATE")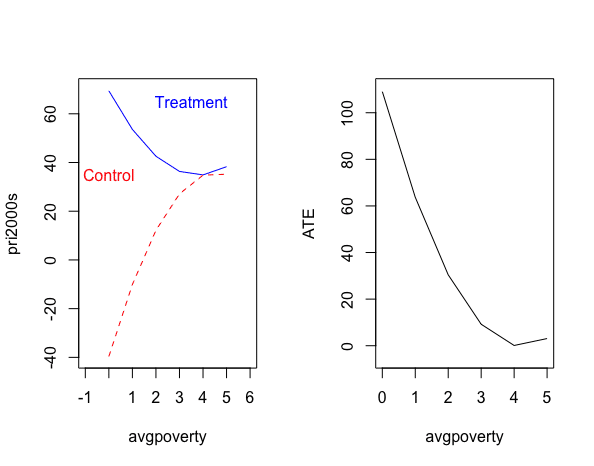
この記事が気に入ったらサポートをしてみませんか?