ユーザー調査とユーザビリティテストの違いを考えてみる 3/3 最終回

前回は、調査と評価の組み合わせを検討しました。最終回はゼロイチで開発する場合のフェーズごとの調査/評価の使い分けを考えていきます。
フェーズを6つに分けて見ていきましょう。
1. 準備段階
2. 開発前
3. 開発初期
4. 開発中
5. リリース前
6. リリース後
1. 準備段階
調査
ここは「ユーザー調査」というキーワードで思い浮かぶような、UXDやHCD的メソッドがそのまま使えると思います。
ユーザビリティテストと同じく、発話法を使います。なんとなく作りたいもののイメージがあるなら、潜在的にユーザーとなりうる人をリクルーティングして、関係がありそうな行動を普段どうやっているか「根掘り葉掘り」聞き取っていきます。
デプスインタビューもこのタイミングで実施する場合が多いと思います。
評価
本段階ではいかなるUIも作られていないため、なかなか評価する対象がないかもしれません。
調査の結果出てきた仮説の案が本当に存在しそうか確かめるのは、評価というよりは検証的調査でしょう。
2. 開発前
調査
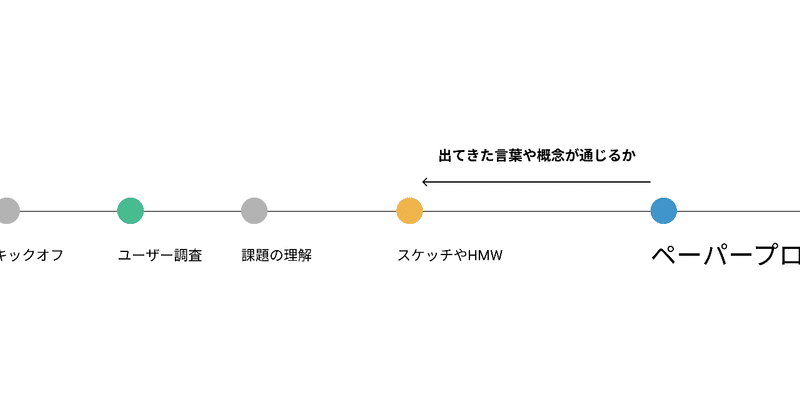
初期の仮説が出揃い、概念レベルで静的構造のアイデアが出てきているかもしれません。作りたいプロダクトの対象となる領域で、できる事や登場するモノの呼び名が、ユーザーの頭の中とマッチしそうか調査するとIAやドメインモデルの精度が高まります。
これには、カードソーティングを用いることができます。カードソーティングはプロダクト上に登場するモノの名前を個別の紙に書き、ユーザーに分類してもらう方法です。一見、Trello等でもできそうですが、分類の軸がどうなるかわかりません。紙のほうが参加者の思考を制限しないはずです。
評価
カードソーティングなどを活用し、何らかのペーパープロトまで作れたら、それを元に形成的評価ができます。
想定していた情報や概念の静的構造が、ここで使い物になるか間接的に検証できそうです。多くの場合、概念の構造や妥当性を確かめるのにGUIのディテールは不要なはずです。ペーパープロトだけで何回も形成的評価を繰り返すほうが、Figmaなどでデザインを始めるより安上がりです。
3. 開発初期
調査
スケジュール的に可能なら、複数の画面遷移やレイアウトのバリエーションを用意し、ユーザーのメンタルモデルを調査することができます。
対象となる領域のユーザーが好む色やディテールのようなビジュアルのスタイルも、ここで見つけられるかもしれません。
評価
FigmaやXDなどを使い、実際にGUIを作って評価します。この段階に来てから、IAや語彙の妥当性を評価するのはコストフルです。
下の例のように、語彙やIAに依存して画面やUIがどんどん作られはじめると、修正のコストも同じように跳ね上がっていくからです。
【先にできる調査をやらずに辛くなる例】
我々は、少し堅苦しい言葉遣いの概念「申請」をドメインモデルやIAに登場させました。行動としての「申請」とモノとしての「申請」があり、GUIの都合で行動のほうの語彙を「提出」にしたとします。その結果、画面に「提出する」ボタンや「提出の確認」ダイアログなどが現れました。
あとから調査や評価により、概念「申請」としていたものをユーザーが「稟議」と呼んでいた事に気づきました。「稟議」を「提出する」という言い回しに違和感を覚えた場合、各画面プロトの「提出」という言葉を全て直したくなるかもしれません。
これがアイコンを作ってしまった後に起きた場合を想像してください。複数の概念で起きた場合を想像してください。検索と置換を繰り返す作業は全く創造的ではありません。
4. 開発中
評価
プロダクトが実装される前に忠実度の高いプロトないしモックでユーザビリティテストが実施できます。ただし、作業仮説やテストタスクの書き方にかなり精度が求められると思います。知りたい事項を具体的に特定しなければ、テスト参加者の発話やフィードバック内容が未完成品だから出てきているのか本質的に潜む課題なのか見分けがつかないからです。
これは、大きな落とし穴になり得ます。「なにを評価するか」曖昧なまま、運悪く未完成品ゆえに現れた課題に注目してしまうと、プロダクトが全て完成してからでないとテストが出来ないような錯覚に陥る恐れがあります。
調査
このフェーズでは従来型開発にせよスクラムにせよ何らかの仕様があり、それに従って開発が進むはずです。もしスクラム等で開発しているなら、すでに出来たユーザーストーリーを試して、該当箇所を今後リッチにする場合のネタを掘り当てられるかもしれません。
5. リリース前
評価
ここではシンプルに、総括的評価を実施できます。タスクを達成するスピードや想定ユーザーの組み合わせで、NE比など定量的なデータを出しても良いかもしれません。ここで行った総括的評価は、ある種のスナップショットとして役立つはずです。次回プロダクトを改善する時の指標にできるからです。
6. リリース後
調査
このフェーズで、ついに実際のユーザーが実際のデータを使って操作する様子を知ることができます。
ここではタイミングに分けて何度か調査しても良さそうです。リリース直後に新しいプロダクトを使いづらく感じていても、数日で気にならなくなるかもしれません。また、現実のユーザーは往々にして思わぬ使い方をします。慣れた後はどのように操作が慣習化されたか知ることができれば、今後の改善の参考として大いに役立つはずです。
総括
時系列ごとに調査と評価の使い所を考えてきました。ここに書かれているアイデアは、ほとんどが教科書どおりの無難なもので、内容的に特筆すべき点はありません。重要なのは、フェーズごとにできる調査も評価も異なるところです。
言い方を変えると、早い段階で確かめたり調べられることを後になって実施するのは、大きなリスクを抱えることなります。
私は、調査や評価にいくつもの種類や目的があるのは、不要なことをせず適材適所に活用するためだと理解しています。例えば、こんな感じに使い分けられると思います:

使い分けできてこそ、無駄や大げさな工数を割かずに必要十分な仮説検証が進められるのではないでしょうか。今後もその辺りを業務で意識して進めていきたいと思います。