
『生活の満足度』を分析して社員満足度を上げよう!

テーマに期待すること
とある会社の人事部で数年間、新卒採用の担当をしていた時、「内定を蹴られないためには何をすれば良いか」とか、「また社員が辞めちゃった」なんてことで良く頭を悩ませていたものです。懐かしい。
最近の働く人は昇進よりも自分の生活を重視する傾向が強い傾向があるそうですね。ならその生活の満足度を会社の福利厚生が適切にフォローできたら、社員満足度が上がるし内定者アピールにも繋がるんじゃない?と思いつきました。きっと離職者削減もできるはず!
ということで、今回の分析の目標点は
【生活満足度に寄与する項目を特定し、手厚い福利厚生に繋げよう!】
です。
言語はPython、環境はGoogle Colaboratoryを使用しました。
前準備
分析フロー
分析の流れは以下の通りです。
元データの項目をエクセル上で確認し、重要項目にあたりをつける。
複数のモデルで学習させ、ベストモデルの予測精度を表示させる。
相関係数を出し、相関の強いものを説明変数の候補とする。
説明変数を精度を基に特定・作成する。
考察する。
使用したデータについて
データ :「第4回(2022年度)満足度・生活の質に関する調査」
取得URL :https://form.cao.go.jp/keizai2/opinion-0021.html
出展 :内閣府
回答人数:10,633人
質問数 :316問
とてもしっかりとした内容で、別の観点での分析も面白いだろうなと感じるデータです。回答は大抵10点満点で答える方式で、一部最も適当な選択肢を選ぶようになっています。また、「家計と資産」「雇用環境と賃金」といった大項目があり、それを深堀りするように小項目が組まれています。
今回の目的変数は「あなたは全体としてどの程度生活に満足していますか("Q1.1")」という質問への回答にしました。

重要項目にあたりをつけてみた
まずはざらっとエクセル上で質問内容を把握しました。生活の事柄を細分化し、それぞれへの満足度を点数化する質問があったので、まずこれらを説明変数の主軸としました。「家計と資産」「雇用環境と賃金」「住宅」「WLB」「健康状態」「自身の教育水準・教育環境」「交友関係」「政治・行政」「生活を取り巻く自然環境」「身の回りの安全」「子育てのしやすさ」「介護のしやすさ」「生活の楽しさ・面白さ」("Q3S1.1"~”Q3S13.1")の計13項目です。 これらに加え、影響がありそうな「居住地("Q39.1")」「性別("SEX")」「年代("NAGE")」を足した16項目で『SLS_res』としました。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
#SLS = Subjective Life Satisfaction(生活満足度) res = Research
Original_data=pd.read_excel("/content/drive/MyDrive/第4回(2022年度) 満足度・生活の質に関する調査_ローデータ提供用.xlsx","ローデータ",header=1).drop(index=[0,1,2],columns="Q39.1-1")
SLS_res=Original_data[["Q1.1","Q3S1.1","Q3S2.1","Q3S3.1","Q3S4.1","Q3S5.1","Q3S6.1","Q3S7.1","Q3S8.1","Q3S9.1","Q3S10.1","Q3S11.1",
"Q3S12.1","Q3S13.1","Q39.1","SEX","NAGE"]]
#欠損値の確認
display(SLS_res.describe())SLS_resに欠損値は確認されませんでした。
相関係数を可視化しよう
上記の説明変数と目的変数の相関係数を可視化してみました。
#相関をヒートマップで可視化する。
import seaborn as sns
fig=plt.figure(figsize=(15,5))
SLS_res=SLS_res.astype(int)
sns.heatmap(SLS_res.corr(), vmax=1, vmin=-1, annot=True)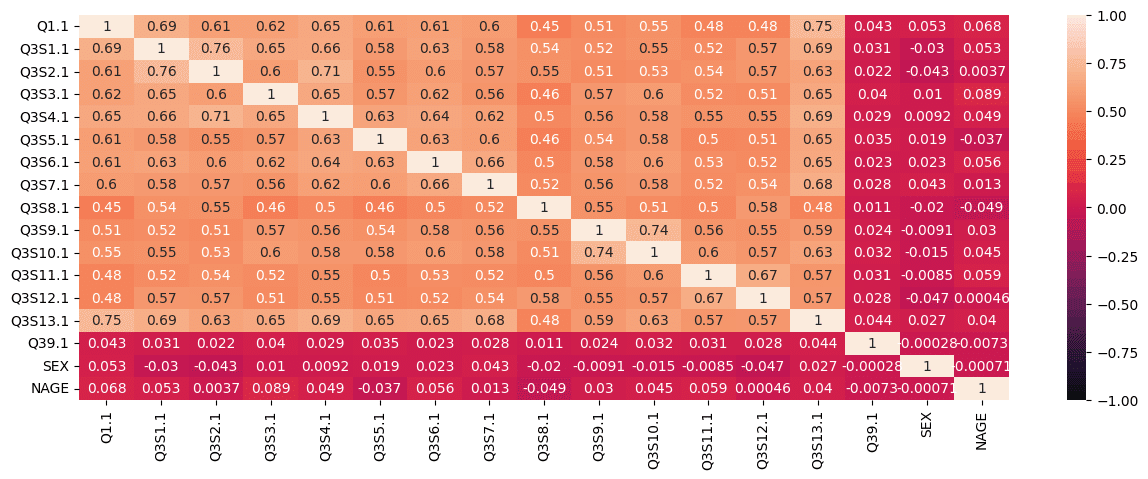
13項目全てに正の相関が見られました。中でも強い相関が見られたのは「家計と資産("Q3S1.1")0.69」「WLB("Q3S4.1")0.65」「人生の楽しさ・面白さ("Q3S13.1")0.75」の3つだと見て取れます。
その一方、追加していた居住地・性別・年代は相関がないという結果になってしまいました。悩みどころですが、そんなことあるのかな?という自分の感覚を信じてそのまま残しておきます。
関数を作成!
今後「最適モデルの選択・精度の計算」を繰り返して説明変数を特定していくことになるので、その過程を関数にしました。
#モデルの比較を関数化
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Lasso
from sklearn.linear_model import Ridge
from sklearn.linear_model import ElasticNet
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.svm import LinearSVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
def Model_score(data):
X=data.drop(columns={"Q1.1"})
y=data["Q1.1"]
train_X, test_X, train_y, test_y = train_test_split(X, y, random_state=42)
list=[LinearRegression(),Lasso(),Ridge(),ElasticNet(),LogisticRegression(),SVC(),
LinearSVC(),DecisionTreeClassifier(),RandomForestClassifier()]
max_score=0
best_model=""
for i in list:
model=i
model.fit(train_X,train_y)
score=model.score(test_X,test_y)
if max_score < score:
max_score=score
best_model=i
print("best model:{}".format(best_model))
print("best score:{}".format(max_score))この後は評価データにおける回帰分析の精度を指標とし、数値が良くなるような説明変数を調査・同定します。
精度を計算してみた
元のデータ(Original_data)と重要項目のみのデータ(SLS_res)で回帰分析の精度を計算してみます。
早速計算してみると、
〈Original_data〉
best model:Ridge()
best score:0.6518776212707091
説明変数計:316項目
〈SLS_res〉
best model:Ridge()
best score:0.6406364403421048
説明変数計:16項目
SLS_resの方が精度が下がりましたが、だいたい同じ値です。下がった分、他にも重要項目があるということでしょう。残りの質問項目には上記13項目に対する「将来の不安度」という項目もあります。これは点数が高いほど不安がないという質問項目です。
#将来への不安を足してみる。
#相関をヒートマップで可視化する。
data_1=Original_data[["Q1.1","Q4S1.1","Q4S4.1","Q4S2.1","Q4S3.1","Q4S5.1","Q4S6.1","Q4S7.1","Q4S8.1",
"Q4S9.1","Q4S10.1","Q4S11.1","Q4S12.1","Q4S13.1"]]
fig=plt.figure(figsize=(15,5))
sns.heatmap(data_1.corr(), vmax=1, vmin=-1, annot=True)
#将来への不安の項目を足す。
SLS_res=pd.concat([SLS_res,data_1.drop(columns="Q1.1").astype(int)],axis=1)
これらも全て正の相関が見られたので、説明変数に加え、精度を計算してみました。
best model:Ridge()
best score:0.6446371223677885
説明変数計:29項目
少しですが数値が良くなりました。
中でも強い相関が見られたのは、「家計と資産("Q4S1.1")0.64」「WLB("Q4S4.1")0.61」「人生の楽しさ・面白さ("Q4S13.1")0.69」の3つでした。この後は強い相関が見られた項目を中心に説明変数の同定を進めていきます。
各説明変数の分布の確認
ここまでに含めた説明変数の分布を棒グラフで可視化し、外れ値や分布の偏りを見ました。
#各説明変数の外れ値を確認。
fig=plt.figure(figsize=(18,20))
list=SLS_res.columns
for i in range(len(list)):
plt.subplot(6,5,i+1)
plt.hist(data_1[list[i]])
plt.title(list[i])
plt.show()満足度、不安度の項目に明らかな外れ値はなかった
男女の人数はほぼ1:1
各居住地(都道府県)の人数もほぼ同数
14段階ある年代は分布に偏りがある
年代の分布のばらつきが顕著でした。年齢によって家族構成や関心事も異なるでしょうし、人数の多い年代に傾向が引っ張られるということも十分に考えられます。何か影響がありそうです。
次に、直観で残しておいた性別、居住地、年代と全体への満足度の分布を可視化してみました。
fig=plt.figure(figsize=(10,5))
ax1=fig.add_subplot(1,2,1)
ax2=fig.add_subplot(1,2,2)
sns.countplot(x="NAGE",hue="Q1.1",data=SLS_res,ax=ax1)
sns.countplot(x="SEX",hue="Q1.1",data=SLS_res,ax=ax2)
fig=plt.figure(figsize=(15,5))
sns.countplot(x="Q39.1",hue="Q1.1",data=SLS_res)
plt.show()

満足度の低い人の割合が中年層は高く見える
女性の方が満足度の高い人の割合が高い
居住地によって点数の分布は様々
中年層といえば介護や結婚、子育てに携わる年代かと思いますので、その影響を調べてみようと思います。男女で満足度の分布に差が見られるのも、子育てにおける男女の役割の違いや、働き方の違いに因るかもしれません。
最後に居住地に関してですが、県によって満足度の分布に差があることが分かりました。何か共通する傾向があるならば説明変数となり得るかと思います。
説明変数の候補たち
ここまでに得られた説明変数の候補たちを整理します。
個別満足度、将来への不安 → 家計、WLB、人生の楽しさ
中年層の分布に特徴あり → 結婚、子供の有無・人数、介護
年代の人数差、満足度の感じ方の違い → 年代毎の満足度への影響
居住地毎の満足度の分布の違い → 居住地の分類
いざ、同定開始!
①家計、WLB、人生の楽しさ
各項目の詳細質問をピックアップし、全体への満足度との相関を調べました。この詳細項目は「〇〇に関する現在の満足や不満に影響あるものを選べ」という形式です。
#家計、WLB、人生の楽しさを深堀りする
#それぞれの詳細項目への満足度をヒートマップで表す
data_2=Original_data[["Q1.1","Q2S1-1","Q2S1-2","Q2S1-3","Q2S1-4","Q2S1-5","Q2S1-6","Q2S1-7","Q2S1-8","Q2S4-1","Q2S4-2","Q2S4-3","Q2S4-4","Q2S4-5","Q2S4-6","Q2S4-7",
"Q2S13-1","Q2S13-2","Q2S13-3","Q2S13-4","Q2S13-5","Q2S13-6","Q2S13-7","Q2S13-8","Q2S13-9","Q2S13-10","Q2S13-11"]]
import seaborn as sns
fig=plt.figure(figsize=(20,15))
sns.heatmap(data_2.corr(), vmax=1, vmin=-1, annot=True)
拍子抜けです。見ての通り、どの項目にも強い相関は見られませんでした。絶対値の大きいものを選ぶと、負の相関が見られるものが多いようです。満足度の高い人が選ぶ項目はばらばらで、低い人が選ぶ項目は少しの共通が見られるということでしょうか。面白いですね。
この中では、「現在の収入("Q2S1-1")」「将来の収入見込み("Q2S1-6")」「税金などの将来の負担("Q2S1-7")」「労働環境("Q2S13-10")」の相関が比較的強めだと分かりました。精度を計算した結果、これらのうち、「将来の収入見込み」を足した場合に精度が僅かに向上しました。
#将来の収入見込み("Q2S1-6")への満足度を追加する。
SLS_res=pd.concat([SLS_res,Original_data["Q2S1-6"]],axis=1)
Model_score(SLS_res)best model:Ridge()
best score:0.6456326883912893
説明変数計:30項目
なお、相関のあった上記の4項目は主にお金に関わるものばかりです。そのため試しに、「現在の世帯収入額」、「個人年収」、「世帯資産」、「世帯借金」についても調べてみましたが、やはりほとんど数値は変わりませんでした。
これらの結果から、お金はもっと欲しいものですが、それぞれの資産状況に見合う範囲で満足する生活を送っているのかも、と推測しました。
②結婚、子供、介護
「家族の人数("Q6.1")」「親の有無("Q7S1-2")」「配偶者の有無("Q7S1-3")」「子供の有無("Q7S1-5")」を追加して精度を比較した結果、「配偶者の有無」のみを追加した場合に精度が向上しました。
#配偶者("Q7S1-3")を追加。
SLS_res=pd.concat([SLS_res,Original_data["Q7S1-3"]],axis=1)
Model_score(SLS_res)best model:Ridge()
best score:0.6494891668421183
説明変数計:31項目
ちなみに配偶者は正の相関があるようでした。(負の相関だったらどうしようかと調べるときドキドキしました。)
「子供の有無」も僅かに精度を向上させたので、試しに子供の人数を追加してみることにしました。子供の人数を直接答える設問がなかったので、子供の年齢の設問を足し合わせて新しいカラムを作成しました。10人目の子供まで回答できるように設問が用意されていましたが、エクセルのフィルター機能で見てみると5人目までした回答が無いようでしたので、5人目までの回答を人数に置き換えて足し合わせました。
#子供の人数を追加する。
#子供の人数のカラムを子供の年齢のデータから作成する。
#欠損値(NaN)は子供0人ということなので、0で置換する。
data_3=Original_data[["nQ8S2.1","nQ8S2.2","nQ8S2.3","nQ8S2.4","nQ8S2.5"]].fillna(0)
data_3=data_3.replace({1:1,2:1,3:1,4:1,5:0})
p1=SLS_res.copy()
p1["Child"]=data_3["nQ8S2.1"]+data_3["nQ8S2.2"]+data_3["nQ8S2.3"]+data_3["nQ8S2.4"]+data_3["nQ8S2.5"]
Model_score(p1)best model:Ridge()
best score:0.6503070449755272
説明変数計:32項目
やはりというか、ほぼ全く数値は変わりませんでした。
以上の結果より、「配偶者の有無」は全体としての満足度の説明変数と言えるようです。私の予想とは異なり、「子供の有無」「子供の人数」は満足度に全く寄与しないことも分かりました。
③年代について深堀り
今回使用している調査では5歳幅で年齢を選択するようになっています。最終目標が仕事に携わることなので、今回は年齢を20歳~64歳の間に絞ることにしました。高卒で働く方も入れたかったですが、19歳以下がひとまとまりになっているので断念しました。
#20歳~64歳に限定する。
SLS_res=SLS_res.query('2<=NAGE<=10')
Model_score(SLS_res)best model:LinearRegression()
best score:0.6552475318858082
説明変数計:31項目
早速数値が向上しました!10代・定年退職後の世代と中間世代とでは生活の違いが大きいのかもしれませんね。他にも世代を2段階や3段階に減らしてしてみたり、分け方を工夫してみましたが、大きく変わることはありませんでした。
④居住地について深堀り
居住地によっても満足度の分布に違いが見られました。エクセルで標準化した各項目の満足度をグラフ化すると、全ての項目が平均以上・平均以下となる県がありました。これは地域性なのか近隣の件の影響なのか、はたまた点数のつけ方に県民性があるのか・・・。以下の区分に分類し直して精度を出してみました。
8地域に分ける
東西日本に分ける
人口順に分ける(100万人単位)
地方税順に分ける(偏差値10単位)
平均寿命で分ける(0.5歳単位)
残念ながら、試した区分では精度は向上しませんでした。
結論と考察
ここまで取り組みましたが精度は65%で頭打ちです。良いとは言えませんが悪くもない、と思います。結果を信頼するとして、全体としての満足度に寄与する説明変数は以下と分かりました。
家計、WLB、人生の楽しさ、特に将来の収入見込み
配偶者の有無
この結果から、私生活を重視する傾向にあるというのは確からしいことが分かります。「現在の収入」は満足度に寄与しないのに、「将来の収入見込み」が寄与するというのも、現代の老後の漠然とした不安が表れていますね。面白いのは「配偶者の有無」が寄与しているということです。正の相関が見られたので、配偶者がいる方が満足度が高いということになります。「子供の有無」は関与していないと分かったので、子育て系の支援はあまり効果がないのでしょうか・・・私はあると嬉しいですけどね。
最近福利厚生の中に『マッチングアプリ』が組み込まれている会社があると小耳に挟みましたが、もしかしたら社員満足度を上げるとても良い手なのかもしれません!ただ新卒採用の目線では、「うちの会社は福利厚生にマッチングアプリがあるよ!」とのアピールはなかなかしづらいので悩ましい結論となってしまいました。
結論、社員満足度を上げるなら、
『社員の結婚を後押しすると良い、かも?』
ご拝読下さりありがとうございました。