
Text Generation WebUI とおしゃべりする設定の覚え書き

たまたまYoutubeのお勧めに出てきた動画が役に立ちました。
TextGeneration WebUIのインストール方法から、音声出力・入力・画像認識の設定が簡潔に書かれていました。
動画にそって、音声出力・入力をためしてみました。
モデルをロード・パラメーターを設定したあと、セッションタブに移動して、TTSとSSTの項目にチェックを入れるだけの説明でした。
TTSにはふたつあって、ひとつはすぐに動きましたが、もうひとつはエラーがでました。すぐ動いたほうは声の質はいいようですが、発声量にリミットがあるみたいなので、フリーのほうを使おうと試みました。また音声入力もうまくいかなかったので、そのエラーを直すところからです。
とにかくエラーがでていたので、ドキュメントを見ました。
セッションで使うextensionに関してのところを確認したところ、TextGen WebUI を 1クリックのインストール方法でした場合は、対応する"cmd_"バッチを走らせて出てきたターミナルに、使うextension-nameを入れて下記のコードを走らせてインストールしてくださいとのことでした。
pip install -r extensions/extension-name/requirements.txt自分の場合は2つがエラーを起こしてたようなので、下記を実行。
pip install -r extensions/silero_tts/requirements.txt>pip install -r extensions/whisper_stt/requirements.txtターミナルをみる限り、うまくインストールされたようなので、再度トライしたら、うまく動きました。
chat画面の一番下に、下記の画像がでます。
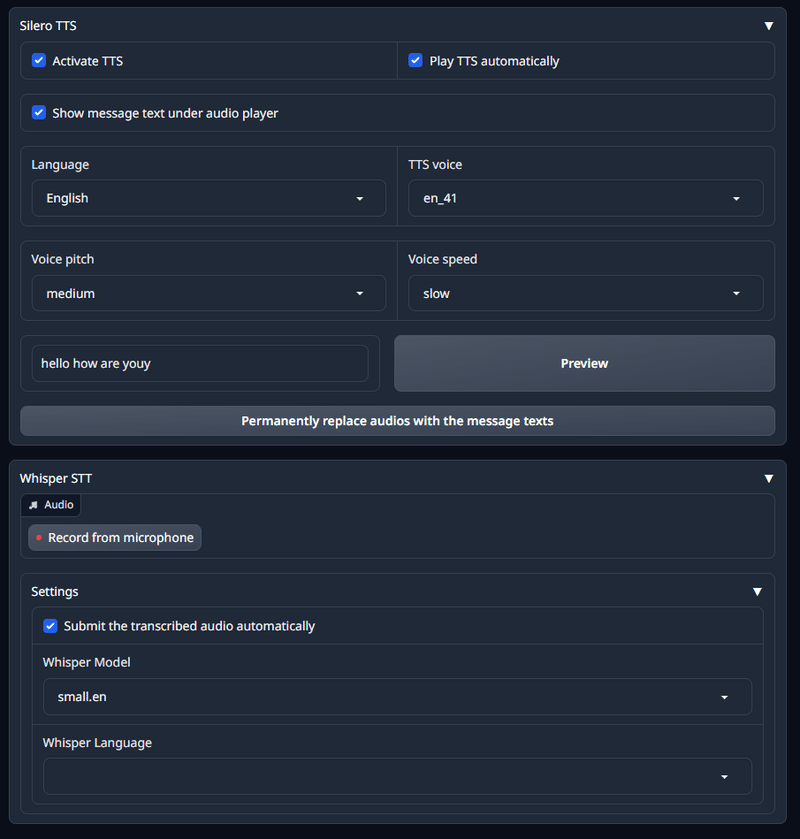
言語はさすがに日本語がなかったのは残念ですが、英語でやります。
上からみていくと
・Activate TTS
・Play TTS automatically
・Show message text under audio player
これらはすべてチェック。
言語は英語のまま、TTS voiceはめちゃくちゃたくさんあったので、動画でたまたま出してた en_41 を選びました。これは女性の声ですが、男性の声もあるようです。 pitch や speedはご自由に、その下に欄に文をいれて右側のPreviewで、設定の音声が確認できます。
STTは whisper を使っています。settingsとしては、自動で送るにチェックをいれておくぐらいです。
あとは、赤ポッチのところを押してしゃべって、しゃべり終わったらもう一度おしてストップすれば、書き起こして自動で入力欄にはいって、送られます。
あと、ChatBotのほうからの応答が長い時は、TTSが取り扱えないようで、エラーがでました。どれぐらい長いとダメなのかはよくわかりませんが、応答の長さを調節する max-tokenをうまく決めれば、その問題はなくなると思います。
今回の言語モデルは、下記を使いました。ちゃんとキャラクター設定のプロンプトに、chatGPT用に使ったプロンプトがそのまま使える感じで、応答もいい感じです。dolphinシリーズは検閲を外したモデルですので、気になる人は他を使ってください。mistral-7b系は軽量でいい感じです。
ローダーはtransfomers で、チェックをいれたのは、auto-devices と use_fast です。
あと、今回のモデルの対話のテンプレートは、解説にしたがって、chatML を選択しました。それでうまくchatができました。
日本語でおしゃべりできないのと、こちらの発声開始と終了のたびにボタンをクリックしなければいけないのが残念ですが、英語会話の練習にもなっていいんじゃないかと思います。
画像認識はまた今度の課題にしておきます。
この記事を最後までご覧いただき、ありがとうございます!もしも私の活動を応援していただけるなら、大変嬉しく思います。