
スギ花粉飛散量のデータ分析@データ前処理②

特徴量をまとめる
さぁ、データ結合まで終わらせたところで、特徴量をまとめていきたいと思います。まず、列同士の関連性を見ていきたいと思います。
import matplotlib.pyplot as plt
import japanize_matplotlib
import numpy as np
import seaborn as sns
plt.figure(figsize=(8, 8))
corr = merged_df4.drop("日付", axis=1).corr()
corr.columns = np.arange(len(corr.columns))
corr.index = np.arange(len(corr.columns))
mask = np.triu(corr)
sns.heatmap(corr, mask=mask, cmap='coolwarm', annot=True, fmt='.2f')このコードは、相関行列のヒートマップを作成します。
前回の記事で、飛散量のデータと平均気温のデータをくっつけましたが、
今回は別々に分析します。

こんな感じになりました!
予想してた通りですが、
["千代田", "葛飾", 杉並", "北", "太田"]が比較的相関性が高いです。
["青梅", "多摩", "町田", "立川", "府中","小平"]も相関性が高いですね。
ということで、これらを2つの列にできそうなので
#関係性が違い列同士を平均して東京23区として統一する
merged_df5["東京23区"] = merged_df5[["千代田", "葛飾", "杉並", "北", "大田"]].mean(axis=1)
merged_df5["東京23区外"] = merged_df5[["青梅", "多摩", "町田", "立川", "府中", "小平"]].mean(axis=1)
merged_df5こんな感じで平均化した新しい列["東京23区"]と["東京23区外"]という列を作成しました。
同様に平均気温でもやってみました。

もう、ほとんど同じですね(笑)
これも一つにしちゃってよいのか不明ですが………平均気温(℃)_tという列を作ります。
とりあえず列を追加しただけなので、おかしくなったら、使わなければ良いだけなので。
外れ値の検出
外れ値を検出するために、以下の散布図を作成しました。


東京23区外は、外れ値が少しあるようです。東京23区は外れ値がなさそうです。
これらの散布図は以下のコードでかけました。
#1月4日から5月11日までをベースとした散布図(横軸平均気温)
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
plt.scatter(merged_df5["平均気温(℃)_東京"], merged_df5["東京23区"], label="東京23区", alpha=0.5, color='blue')
plt.scatter(merged_df5["平均気温(℃)_東京"], merged_df5["東京23区外"], label="東京23区外", alpha=0.5, color='red')
plt.xlabel("平均気温(℃)_t")
plt.ylabel("花粉飛散量")
plt.legend()
plt.show()
#1月4日から5月11日までをベースとした散布図(横軸日付)
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(15, 5)) # 横幅を調整
plt.scatter(merged_df5["日付"], merged_df5["東京23区"], label="東京23区", alpha=0.5, color='blue')
plt.scatter(merged_df5["日付"], merged_df5["東京23区外"], label="東京23区外", alpha=0.5, color='red')
plt.xlabel("日付")
plt.ylabel("花粉飛散量")
plt.legend()
plt.xticks(rotation=45) # x軸ラベルの回転角度を設定
plt.show()このコードは覚えておいた方がよさそうです。めちゃくちゃ使います。
日付の数値化
実は私、平均気温とスギ花粉量は結構比例するのでは?と思ってましたが
全然違いました。。。。そうです。日付の要素があるのです。
だって夏にはスギ花粉ないでしょ?(笑)
こんな簡単なことを忘れているなんて(笑)
ということで日付を機械要素に入れたいのですが、、、、、
はて、どうやってやればよいのでしょうか。。。。
日付を数値化??でも2005年とか2010年とか年形式を含んでいるからなぁ。。
なんとか〇月〇日のところだけピックアップして、数値化できないのだろうか。。。
そこで
merged_df5['日付'] = merged_df5['日付'].apply(lambda x: x.timetuple().tm_yday)このコードで、数値化した後の散布図が以下になります。

うんうん、なんかいい感じ!外れ値もわかる!!!
しかし、機械学習精度を上げるために、さらに週ごとにまとめていきます。
import pandas as pd
# まず、datetime型の"日付"列から"週番号"を計算します。
merged_df5['週番号'] = merged_df5['日付'].dt.weekofyear
# ただし、年が変わる直前の週は、新しい年の最初の週(1週目)として扱われることがあるため、
# 週番号が最大週番号(52または53)である場合は、週番号を1に設定します。
merged_df5.loc[merged_df5['週番号'] > 51, '週番号'] = 1
# 最後に、年の情報を削除します。
merged_df5.drop('日付', axis=1, inplace=True)こちらは1月1日から7日は1, 8日から14日は2….になるようなコードです。
外れ値の削除
散布図を見ると、花粉飛散量が600以上のものは外れ値に該当するのかなと思います。
そこで、飛散量600以上のものは全て600にするようなコードを書いていきます。(色々変更してますので、変数がmerged_df7になってます)
merged_df7["東京23区"] = merged_df7["東京23区"].apply(lambda x: min(x, 600))
merged_df7["東京23区外"] = merged_df7["東京23区外"].apply(lambda x: min(x, 600))上記のコードを書くと、以下の散布図になります。

うん、機械学習できそうな散布図になりましたね。
.shift()と.rolling()
上記コードを使うと以下のような列を作ることができます。

まず、
.shift(1)を使った列は"東京23区_lag1
.shift(2)を使った列は"東京23区_lag2
.shift(3)を使った列は"東京23区_lag3
このコードは東京23区を1, 2, 3個ずつずらしてくれるコードです。
(NaNは0で埋めてます)
例えば、東京23区の花粉飛散量を予測する際、前日や前々日の飛散量も学習データに使いたい場合に役立ちます。
また、.rolling()について
merged_df7["東京23区_lag1"].rolling(3).moean()にすると3日前までの平均をデータにできる列です。
この列も、直近3日間の平均値を学習データに使えるようになります。
これらを使用して、作った表が以下になります!
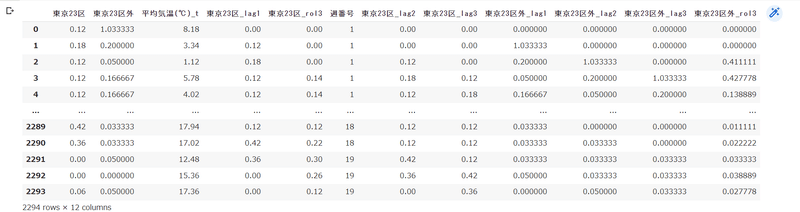
上記表より、東京23区と東京23区外の花粉飛散量の予測モデルを作成していきたいと思います。そちらは次回の記事に書きます。
いかがでしょうか。次回はいよいよ機械学習編に入ります!
この記事が気に入ったらサポートをしてみませんか?