
スギ花粉飛散量のデータ分析@データ読み取り編

こんにちは!Aidemyのデータ分析講座を受講してから2か月も経ちます!今日は修了課題の成果物作成について、ブログを書きました!
めちゃくちゃ苦戦したので、何回かにわけて書きますw
素人の苦戦を、とくとお楽しみくださいwww
データの場所
まず、スギ花粉の飛散量ってどんな影響に左右されるんだろう。。。
とりあえず、日付と気温のデータから始めるか…
ということで以下のサイトからデータを読み取りました。
平均気温
https://www.data.jma.go.jp/gmd/risk/obsdl/
スギ花粉飛散量
ここから.csvデータでダウンロードができるのでひとまずここでダウンロードします。
データをGoogle coravoratory上にインポート
もうね、まず素人はここでつまづくわけですよw
Aidemyさんは、カウンセリングができますので、丁寧に方法を教えてくださいました。
まずは、Google Driveに保存する
自分でDrive上に先ほどの.csv上のファイルを置きます。
今回は平成17年のスギ花粉データを例に報告します。
その後、google colaboratoryで
左側にあるファイルを選択して、googleドライブをマウントします。
すると…

このようなコードが出てくるので実行します。
出てきました!
そして、以下のコードを書きます。
読み取りたいデータを右クリックしてパスコードをコピーしてください。
(パスコードは'/content/drive/MyDrive/ブログ用/h17_cedar_data.csv'です)
import pandas as pd
df = pd.read_csv('/content/drive/MyDrive/ブログ用/h17_cedar_data.csv')
display(df.head())でもこれだけじゃ、エラーになっちゃうんです……
そうです。エンコーディングがUTF-8ではない場合はエラーが出ちゃうんです。(エンコーディングについては、調べれば出てきます)
そこで、
import pandas as pd
df = pd.read_csv('/content/drive/MyDrive/ブログ用/h17_cedar_data.csv', encoding='shift_jis')
# データの先頭5行を表示df.head()
これでできました!
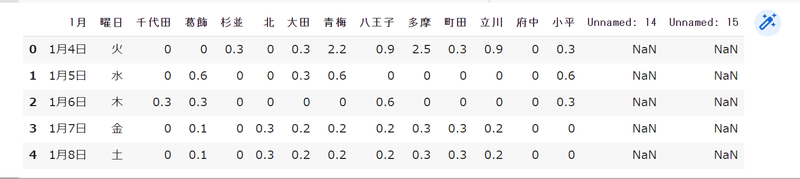
変な列とか追加されてますが、それは後で消しましょう。
エンコーディングがわからないときは??
エンコーディングがわからないときは、以下を試してみてください。
#chardetライブラリをインストール
!pip install chardet
import chardet
with open('/content/drive/MyDrive/ブログ用/h17_cedar_data.csv', 'rb') as f:
result = chardet.detect(f.read())
df = pd.read_csv('/content/drive/MyDrive/ブログ用/h17_cedar_data.csv', encoding=result['encoding'])
わからないときは、これで読み取ることができます。
プログラミングってすごいです!!
年代別のcsvデータを一気にダウンロードしましょう
ここまでやってきて、頭の良い方は気が付いたと思います。
え?この作業を10年分以上やるの???しかも花粉量だけで?気温とかのデータもやるのに??
そんな方はプログラマーに向いているのかもしれません。
楽しましょ!楽を!
パスコードに注目!
もう一度パスコードを見てみましょう!
/content/drive/MyDrive/ブログ用/h17_cedar_data.csv
h17は容易に、平成17年と予測できますよね!
なら、h18は平成18年, h30は平成30年と予測できます。
(ちなみに令和2年はr2なので、令和も同様です)
さぁ、そこでfor構文を使ってダウンロードしましょう。
import requests
from pathlib import Path
url_base = "https://www.fukushihoken.metro.tokyo.lg.jp/allergy/pollen/archive/csv"
file_suffix = "_cedar_archive.csv.zip"
for i in range(17, 28):
url = f"{url_base}/h{i}{file_suffix}"
response = requests.get(url)
if response.status_code == 200:
file_path = Path(f"h{i}{file_suffix}")
with file_path.open("wb") as f:
f.write(response.content)
print(f"ダウンロード完了:{file_path}")
else:
print(f"エラー:{url} のダウンロードに失敗しました。HTTPステータスコード: {response.status_code}")
import zipfile
import pandas as pd
# 上記ダウンロードコードの続き
# 全てのzipファイルを解凍してCSVファイルを読み取る
for i in range(17, 28):
zip_file_path = Path(f"h{i}{file_suffix}")
if zip_file_path.exists():
# zipファイルを解凍
with zipfile.ZipFile(zip_file_path, 'r') as zip_ref:
zip_ref.extractall()
# 解凍されたCSVファイルを読み取る
csv_file_path = Path(f"h{i}_cedar_data.csv")
if csv_file_path.exists():
df = pd.read_csv(csv_file_path, encoding='shift_jis')
print(f"CSVファイル読み取り完了:{csv_file_path}")
display(df.head())
else:
print(f"CSVファイルが見つかりません:{csv_file_path}")
else:
print(f"zipファイルが見つかりません:{zip_file_path}")url_baseとfile_suffixの情報は、csvファイルダウンロードというところにマウスを置くと、左下に表示されます。

そうすると全てダウンロードし、解凍され、データフレームとして出力できます。
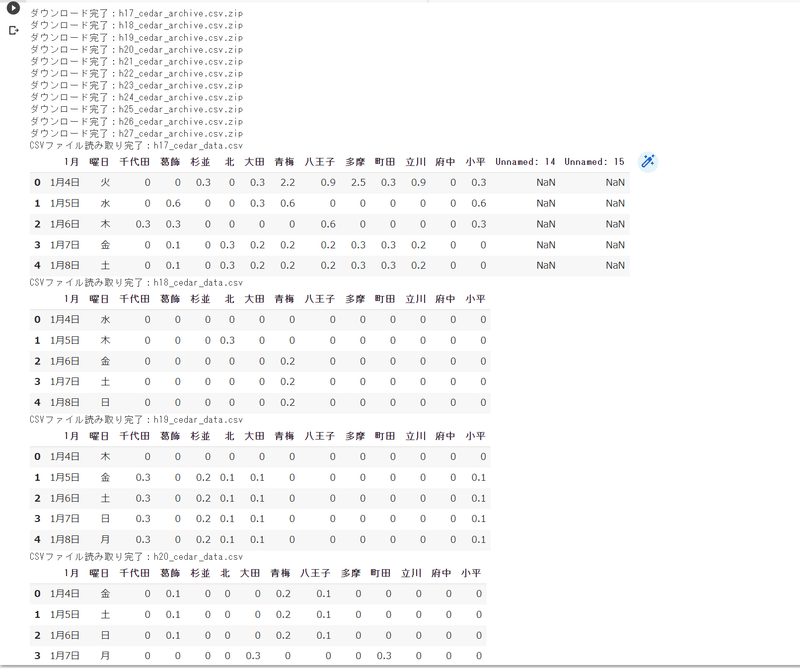
最後に
いかがでしたでしょうか。
データを読み取るだけでもかなり時間がかかりました……
ちなみにこれと同じように平均気温なども読み取っていきます……
しかし、まだ私は素人同然。このやり方よりも、もっと良い方法があるかもしれません。
プロの方、ツッコミ箇所がありましたら、どんどん指摘しちゃってください!!
これだけでは、わからない方
コメントいただければ、回答します!
最後までお読みいただきありがとうございました!
次はデータの前処理について説明します!
この記事が気に入ったらサポートをしてみませんか?