
人事データ分析例:可視化による現状把握 (エンゲージメント分析)

先日、人事データ分析の切り口についての記事を投稿しました。こちらの記事では人、組織といった切り口を提示し、その上で例として従業員エンゲージメント分析を取り上げました。今回は、例題データを用いてより実践的に切り口を考えてみたいと思います。自由に使えるデータも準備しましたので、興味のある方は手元で分析してみてください。
分析例をガンガン載せていく内に長い記事になってしまいました。探索的なデータ分析のプロセスをリアルに感じたい方は順にお読みいただくとよいかと思います。
例題: 従業員エンゲージメントの現状を把握
例題のテーマとして従業員エンゲージメントを取り上げます。
ピープル・アナリティクスでは、①現状の把握、②問題の深掘り、③課題解決の仮説構築、④施策実行・監視のサイクルを回しながら施策を打っていくような流れになります。(参考記事:ピープル・アナリティクスと仮説検証とOODA)
今回は、このサイクルの中で起点となる「①現状の把握」にチャレンジします。具体的には、従業員エンゲージメントの状況がどのようになっているのかを把握し、問題点を洗い出すことを試みます。例題とはいえ分析の前提条件があると分かりやすいので、ケース上のストーリーをいくつかあげておきます。(以下、従業員エンゲージメントを単にエンゲージメントと記載します。)
エンゲージメントを高くすることは重点人事施策となっている。
エンゲージメントは従業員に対するアンケート調査により計測されており、最新(2021年)の調査結果を用いて調査することとなった。
エンゲージメントは従業員それぞれに対して1から9までの数値(スコア)で表されており、数字が大きいほどエンゲージメントが高いとされる。
アンケート項目や数値化ツールは専門会社から購入したもので、エンゲージメントの数値は数量的な比較ができるものと言われている(間隔尺度)。ただし、スコアが○○以上だと良好といったような絶対評価はできない。
組織的なKPIがまだ定まっておらず、まずはエンゲージメント調査をやってみたという状態で集計しただけの状態になっている。
営業部門や開発部門の所属長へのヒアリングでは、若い世代の離職が心配だという声があった。そこで、人事部門の施策検討の一環でエンゲージメントの状況を把握する活動がスタートした。
あなたは定量的な観点で調査を行う担当となり、手元にはエンゲージメント調査結果を含む人事データがやってきたという状況とします。
例題データ
今回準備したデータは仮想的な例題データ(トイデータ)です。私個人で自作したデータとなっており、リアリティにかけるかもしれませんがご容赦ください。以下のリンクからダウンロードが可能です。
データの概要
全体で60件、23項目からなる小さなデータです。データのサンプル(2件)を以下に示します。1行目がヘッダのカンマ区切りののCSVファイルです。なお、文字コードはUTF-8となっていますので、Excelで開く場合はご注意ください。(こちらの記事に対処方が掲載されています。)

データは1年度分で、従業員一人につき1レコードの情報となります。今回注目しているエンゲージメントは一番最後の列にあります。
データの項目
データの項目を簡単に解説します。手作りなデータなので無理やり感のある項目もあります。あくまで、例題を通して可視化による分析を示すことが目的ですので、その辺はご容赦くださいませ。
従業員ID: 従業員を一意に識別するID。(カテゴリ変数)
年度: データを記録した年度。他の情報は年度末時点の情報。年度は4月から始まり3月までとする。会計年度も同様。
性別: 従業員の性別。(カテゴリ変数)
年齢: 年度末時点の従業員の年齢。
年代: 年度末時点の従業員の年代。(カテゴリ変数)
最終学歴: 従業員の最終学歴。(カテゴリ変数)
入社時年齢: 入社時の従業員の年齢。
採用種別: 新卒採用か中途採用かの区別。(カテゴリ変数)
入社時年度: 従業員が入社した年度。
勤続年数: 従業員の勤続年数。「入社時年度」と「年度」の差分。
採用時能力評定: 採用時に実施した能力アセスメント結果。本例題上は採用年度を跨って比較可能とする。
所属: 当該年度における従業員の所属を部単位で記載。本例題上は年度内異動はなかったものとする。(カテゴリ変数)
メンバーシップ型のため明確なジョブ定義はなく、所属内の従業員には単一の人事職種が設定される想定。営業部→営業職、開発部→開発職、経理部→経理職、研究部→研究職、総務部→総務職。グループ: 部内のマネジメントの単位を示すもの。一般的には「課」に相当。人事上は部までの組織設計となっておりグループ構成は部長に委任されている。(カテゴリ変数)
グレード: 従業員の等級の概略。M:課長・部長に相当する管理職、L:係長に相当する非管理職のリーダークラス、S:一般社員、E:定年後再雇用スタッフ。(カテゴリ変数)
成績: 目標管理制度に基づく年度末の業績評価結果。評価の高い順にSA, A, B, C, D。人事のガイドラインに基づき管理職が評価する。所属内の相対評価であり絶対評価ではない。賞与に影響。(カテゴリ変数)
コンピテンシー: 年度末時点のコンピテンシー評価に基づく評価結果。1~9で数値が高いほど当該コンピテンシーが高い。人事のガイドラインに基づき管理職のアセスメントで決定する。個々の評価は絶対評価にて実施しており、値の相対比較が可能なものとして運用されている。昇給・昇格に影響。評価観点は以下の通り。
マネジメント: 組織マネジメント力のコンピテンシー。人的マネジメント力、組織牽引・運営力、プロジェクト・プログラムマネジメント力の総合的な評価。
戦略企画: 戦略的な企画構想力のコンピテンシー。先見性、洞察力、構想力など戦略やビジョンの構築に係る能力を総合的に評価。
対人: 対人関係に係るコンピテンシー。コミュニケーション力、折衝力、関係性の構築、サポート力などの総合的な評価。
専門性: 所属部門で期待される専門性に対するコンピテンシーを評価するもの。
チーム: 組織行動としてチーミングに寄与できているか評価するもの。主体的なチーム内コミュニケーション、ノウハウや情報共有、人材育成、新メンバーへのオンボーディング、ダイバーシティの受け入れ。
時間外時間数_月平均: 当該年度における従業員の月別時間外勤務時間数の平均値。
年休消化率: 年度末時点の年次有給休暇の消化率。年次休暇は年度単位で付与されるものとする。
エンゲージメント: 各従業員のエンゲージメントを1~9の数値でスコアリングしたもの。エンゲージメントのスコアが高いほど会社と当該従業員の結びつきが強く、当人および所属組織にとって良い影響をもたらすとされている。
エンゲージメント調査は年1回実施され、専門家の指導の元作成された十数程度のアンケートにより実施される。アンケートは選択式と自由回答で構成されるが、その中の選択式のアンケート結果を定めれた方法で数値化しスコアに集約している。本ケースではこのスコアを間隔尺度として取り扱えるものとする。
エンゲージメントのスコアは組織内で相対的に比較することは可能であるが、例えば6以上がよいという風に絶対的な尺度で測ることはできない状況とする。
分析アプローチの検討
復習になりますが、今回の分析目的は「従業員エンゲージメントの状況がどのようになっているのかを把握し、問題点を洗い出すこと」でした。この目的を達成するための一つの手段として、人事データを活用して定量的な観点で分析してみようというのが例題です。現実的にはデータ分析だけでこの目的を達成することは困難であり、インタビュー等定性的な調査も併用する必要もあるでしょう。
以上を踏まえて、データ分析のアプローチを考えてみます。
初期分析の基本方針
現状把握からということなので、初期分析の方針として、どういう人や組織でエンゲージメントが上下しているのか比較しながら傾向を把握することから始めるのがよさそうです。エンゲージメントのスコアは比較可能と言う設定ではありますが、絶対的なものでなく比較による分析しながら洞察する必要があるからです。
そして、分析の手段としては、データの理解を深めるためにも、シンプルな集計、可視化を用いて統計的な観点で洞察していく方法を採用します。集計や可視化はデータ分析の基本的なツールですが、分析者自身だけでなくクライアント(仕事の依頼元・上司)への説明も分かりやいというメリットもあります。
一方、いざ分析しようとしても、慣れていないとどういったグラフを作ったらよいか分からないこともあるでしょう。そこで、先日投稿した以下の記事で示したように、仮説を考えつつ、人や組織という単位で分析の軸や切り口を考えいくことをお薦めしています。分析の切り口に対してどういった可視化手法を選択すべきか、という点についてはこの記事で取り上げていますので、ぜひご覧ください。
分析のイシュー
分析に入る前に、ドメイン知識や部門内で見聞きした情報をもとに、エンゲージメントについて今組織で起きていそうなことは何か?という疑問に直観で答えながら、仮説や疑問を洗い出してみましょう。ここで洗い出したことが分析で明らかにすべきイシューとなります。先の記事では、以下のような仮説・疑問を例として挙げていました。
どのような年代でエンゲージメントが低下しているか。
新卒採用者と中途採用者で違いはあるだろうか。
従事している仕事によって傾向は異なるだろうか。(職種など)
どのような部門でエンゲージメントが低下しているか。
階層の上下で認識のギャップがおきていないだろうか。部下と上司はどうか。
データの外観を把握する
分析を始める前に、手元にあるデータの全体像を把握していきます。今回は例題データの作成者として私は様々な情報を把握しているわけですが、一般的に分析者はデータの発生源や抽出状況、値の分布から把握する必要があります。
データの外観を調査するための観点としては、以下のようなものが考えられます。
データの取得条件や発生源、項目の意味を調べる。(データ提供元とのコミュニケーション)
データのサイズ、各項目に含まれる値の範囲や基礎統計量を把握する。
年齢、スコア、時間外時間数などの量的変数の場合は平均、四分位数、分散などの基礎統計量を把握。
性別、成績、所属などのカテゴリ変数の場合は変数が持つカテゴリの種類とカテゴリ毎のデータ数(度数)を把握。
欠損や明らかな異常値がないか調べる。
異常値の例:
0以上の値を取るはずなのにマイナスの値が入っている。
年齢なのに200を超える数値が入っている。
すべてのデータで値が同一の変数がある。
カテゴリ変数で度数が1のデータがあり表記揺れの疑いがある。
他の変数と同一の値や動き方をしている変数がないか確認。(量的変数の場合は相関係数が1となるよう変数)
今回の例題データには異常値や欠損は含めていないものになっていますので、2. の基本的な確認をしていきます。
基本的な統計量の確認 (1)量的変数
まず量的変数の統計量を確認していきましょう。以下の表はPythonのpandasを利用して出力したものですが、Excelでも可能です。

平均(mean)や中央値(50%)を見ることで各変数の中心的・代表的な値を知ることができます。例えば、年齢の平均値は約40.3歳となっており、組織全体の平均年齢を知ることができます。
また、最大値(max)と最小値(min)を確認すると、データの範囲を確認できます。年齢を見ると23歳から60歳までの従業員が在籍していることが分かります。また、最大値・最小値を確認することで、異常値を発見できる場合もあります。
今回注目しているエンゲージメントの統計量を確認してみましょう。平均値は4.6で最小値1、最大値7となっています。エンゲージメントは1~9の範囲で算出されることになっていましたので、これだけ見ると下振れしているようにも思われます。一方、中央値が5と平均よりも大きくなっていますので、分布が若干偏っている可能性もあります。
このように、基本統計量だけでもある程度傾向を捉えることができますが、実際のばらつき具合を見るにはグラフを用いて可視化してみるのが有効です。早速年齢からみてみましょう。
まずは棒グラフを使って年齢分布を確認してみました。棒グラフは多くの方が馴染みのあるグラフだと思います。ぱっと見もわかりやすいですね。しかし、横軸を見てみると年齢が飛び飛びになっている個所がいくつか確認できます。軸を整理しないで棒グラフを描くと存在しない値の情報が欠落してしまうので、年齢のように大小関係のある情報を可視化する場合は注意が必要です。

以上のような問題があるので、今回はヒストグラムを用いて年齢の分布を確認してみました。量的変数の分布を確認する際にはヒストグラムを使うと分かりやすい場合が多いです。年齢分布を見てみると、(1)50代以降が少ない、(2)40代後半から50代前半が多い、(3)40代後半が周辺に比べて少ないなどの情報が得られます。

では、今回の調査対象であるエンゲージメントを見てみましょう。ヒストグラムに加えて大まかな傾向を示すための曲線もフィットしてみました。これを見ると分布が右の方に寄っていて、何となく良い印象を持つかもしれません。しかし、エンゲージメントのスコアの定義では値の範囲は1~9までとなっていますので、この図だけで洞察するのはまずそうです。

そこで、横軸を1~9の範囲に合わせてヒストグラムを見てみることにしました。図を見ると高スコアの部分がすっぽり抜けていることが分かります。全体的に見るとスコアの中心付近が盛り上がりを見せるものの、低スコア帯にそれなりに人が分布しています。しかしながら、スコアの大小に絶対的な判断基準はありませんので、相対的に比較していく必要があります。

基本的な統計量の確認 (2)カテゴリ変数
次に、性別、所属といったカテゴリ変数(質的変数)の統計量を確認していきます。
カテゴリ変数は数値ではないので平均や標準偏差といった統計量を用いて確認することができません。そこで、基本的には、(1)変数に含まれるカテゴリの種類を確認し、(2)種類ごとのデータ数を比較するという方法を取ります。データの定義を見れば(1)は明らかかもしれませんが、実際のデータを確認するまでは油断できません。必ずしもデータの説明が正しいとも限らないからです。
それでは性別と所属それぞれについてみていきましょう。下図は、それぞれカテゴリ毎にデータ件数(人数)を集計し棒グラフで表したものです。これを見ると、(1)男性が多く、(2)所属としては開発部が最も人数が多いということが分かります。つまり、従業員が持つ属性に偏りがあることを示唆しています。こうした情報は分析を進めていくうえで重要な情報となります。


上記で出てきた性別と所属をクロスして分析してみましょう。所属毎の男女の在籍傾向を把握していきます。まずは単純なクロス集計表を用いて、各部の在籍人数を出してみました。この表を見ると各部で在籍傾向に違いがありそうな感じがしますね。

次に在籍数でなく男女比率を見てみました。下表で見ると部毎に男女比率が大きく異なっている様子が分かります。

ここまでは表を用いて男女比率を見てきましたが、グラフを使うことも可能です。棒グラフを男女別に示したものと、積み上げ棒グラフで割合を示したものをそれぞれ作ってみました。比率を確認する場合には積み上げ棒グラフの方が分かりやすいですね。


人の属性に基づいたエンゲージメントの傾向分析
データの外観について理解が深まりましたので、いよいよエンゲージメントの傾向分析に着手したいと思います。まずは従業員=人が持つ属性とエンゲージメントとの関係を分析していきます。
ここで取り上げる分析対象は、年齢、性別、採用種別、成績、グレード、所属、時間外時間数、年休消化率とします。性別と採用種別以外は経年で変化し得る情報であることに注意する必要がありますが、今回はデータの都合により単年度での分析に留めます。
俯瞰的な分析(相関係数の把握)
ここで取り上げた項目についてざっと確認する方法があると便利ですね。よくある方法として、量的変数同士の関係を簡易に見る上で相関係数を用いた分析というものがあります。相関係数は量的変数間の線形の関連を分析することに利用できます。
相関係数は-1から1の範囲の値を取り、その絶対値が1に近いほど関係が強いと解釈できます。正の値の場合は正の相関、つまり片方の値が大きいときにもう片方の値も大きいことを意味ます。一方、負の値はこれの逆で、片方の値が大きいときもう片方の値は小さいという関係にあります。
まずはやってみようということで、上にあげた分析対象の中から量的変数である年齢、時間外時間数、年休消化率を取り上げて、エンゲージメントとの相関係数を算出してみました。今回はPythonを利用して計算しましたが、Excelでも相関係数を出すことが可能です。
下表は縦と横の変数同士の相関係数を表したものです。左上から右下にかけて対角線上の項目は同じ変数同士の値になりますので1となっています。この対角線の右上と左下側は同じ変数の組み合わせを含むのでご注意ください。

上の表でエンゲージメントの列を見てみましょう。年齢、時間外時間数_月平均、年休消化率それぞれで強い相関があるとは言えなさそうな結果に見えます。相関係数がズバッとでると分析的に楽なこともあるのですが、リアルな人事データの分析で明確な相関関係が見えることはなかなかありません。
相関係数による分析で関係が見えなかったとしても、がっかりする必要はありません。この場合、仮説として次のようなことが考えられます。
量的変数同士で線形の関係にないが、非線形な関係にある可能性があるかもしれない。
別の質的変数(カテゴリ変数)と関心のある量的変数の間で何らかの関係がある可能性があるかもしれない。
複数の変数の複合的な関係があって、単一変数同士の関係が見えにくくなっている可能性があるかもしれない。
観測範囲外の情報が寄与している可能性があるかもしれない。
統計的な観点ではエンゲージメントと関連する情報がなく、ランダムに決定される可能性があるかもしれない。
上記すべての要因が絡まっている可能性があるかもしれない。
いかがでしょうか。より一層こんがらがってきたような気もしますが、実際の分析実務で直面するのはこのような状況です。ということで、めげずに上記の仮説1.と2.から見ていきましょう。
変数同士の関係を可視化で分析する
先ほど相関係数を出してみましたが、あまりはっきりとした考察を得ることができませんでした。そこで、グラフを用いて可視化して洞察を深めていきます。データをいろいろと解剖しながら洞察していくプロセスを探索的データ分析と呼びます。雲をつかむような気持ちになる作業ですが、私はデータ分析の中で最も面白いフェーズだと考えています。
それでは年齢、性別、採用種別、成績、グレード、所属、時間外時間数、年休消化率それぞれについて、エンゲージメントの関係を分析していきましょう。
◆年齢とエンゲージメントの関係
まずは年齢からみていきます。本例題ケースは、若手の離職への心配を危惧したところから始まりました。現状を確かめるべく、年齢とエンゲージメントの関係を可視化によって分析します。量的変数同士の分析になりますので、散布図を用いて可視化をしてみました。

上の散布図を見てもどうにもはっきりしない状況かと思います。これでは相関係数の絶対値が小さくなることもうなずけますね。この状態で無理やり直線回帰モデルをフィットさせることもできますが、これだけで結論を出すのは危険な感じがします。(下図参照)

このような場合、平均的な傾向よりもばらつきに着目するのも一案です。年齢とエンゲージメントの散布図でばらつきがあるということは、他の変動要因があることを意味しているからです。
この点をもう少し分かりやすく分析するため、年代別のエンゲージメントの状況を箱ひげ図を用いて分析してみました。箱ひげ図はデータの中央値、四分位数、最大値、最小値がぱっと見でわかる便利な図です。カテゴリデータ別にデータの傾向を把握する用途に向いています。

上の箱ひげ図を見てみると、60代を除いて概ね中央値は近しいところにあることがわかります。一方、30代と50代は箱の大きさが長くなっていてばらつきが大きく、それぞれ中央値から下に向かって箱が伸びている傾向もあります。したがって、30代・50代は同世代の中でエンゲージメント的に不満を持っている隠れたクラスターがありそうな雰囲気です。
このように箱ひげ図は便利ではありますが、眺めていると何となく中央値を含む箱の中にデータのボリュームゾーンがあるような気持ちになってしまうのが難点です。例えば、データの分布が二つのピークを持つ場合であった場合には、箱ひげ図ではそれを捉えることができません。
この問題を解消するためには、ヒストグラムやバイオリンプロットなどを利用してより細かな分布の傾向を捉えることがよくあります。一方、データ量が大きくない場合には、素直にデータ点をプロットしてみる方法もあります。今回は一般的にビーズウォーム・プロットと呼ばれる手法を用いて可視化してみました。箱ひげ図と比べて印象が変わったのではないでしょうか。

箱ひげ図とビーズウォーム・プロットを重ねてみるとより顕著になります(下図)。これを見ると、特に30代と60代については箱ひげ図だけで見るのはミスリードを招きそうだと言えますね。

以上、いろいろと年齢とエンゲージメントの関係を分析してきましたが、年代によってばらつきが大きい、ということが分かりました。
◆性別とエンゲージメントの関係
次に、性別とエンゲージメントの関係を探ってみます。先ほどの例と同じようにカテゴリ×量的変数の関係を見ることになるので箱ひげ図を使うことも可能ですが、今回はカテゴリ数が2つだけなのでヒストグラムを利用してみました(下図)。

このヒストグラムでは、性別の男・女それぞれで各階級のデータ密度を表すようにしています。こうするとシンプルに分布の違いを比較することができます。また、ヒストグラムを重ねてもわかるように透過処理をしてみました。これを見てみると性別によってエンゲージメントの分布に大きな違いがあるとは言えなさそうです。
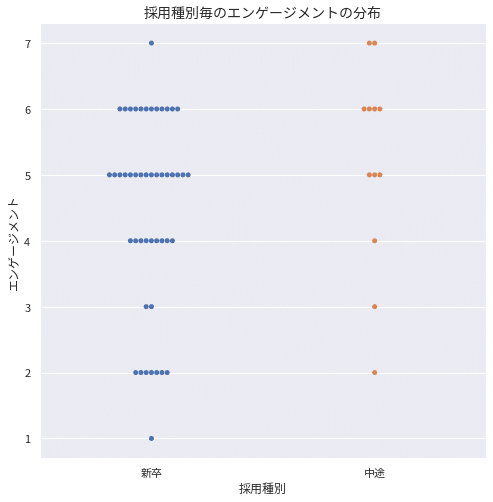
◆採用種別とエンゲージメントの関係
採用種別とエンゲージメントの関係を分析してみましょう。採用種別は新卒と中途の2種類ですので、性別の時と同様にヒストグラムを使って分析してみました。似たような分布をしていますがピークが若干ずれているようにも見えます。

念のため、ビーズウォーム・プロットを用いて詳細を把握しておきましょう。下図を見ると、新卒は2つのクラスターがあることと、中途は新卒よりも若干中央値が高いことが分かります。これらの点は先ほどのヒストグラムでも読み取れますが、データが少ない場合はビーズウォーム・プロットで見る方が実態がつかみやすい場合が多いです。いずれにせよ、採用種別で何か大きな違いがあるとは言えなさそうだと考察できます。
◆成績とエンゲージメントの関係
続いて、業績評価結果である成績とエンゲージメントの関係を分析していきます。成績はSA, A, B, C, Dというカテゴリ値ですが、SAを筆頭とした順序関係があるものです。したがって、可視化するときには並び順を丁寧にケアすると分かりやすくなります。
下図は、ビーズウォーム・プロットを用いて成績とエンゲージメントとの関係を可視化したものです。これを見ると、SAとDは極端な傾向を示していますが、サンプルが極めて小さいため考察するためにはインタビュー等の手法を組み合わせて丁寧にフォローしていく必要がありそうです。
一方、AとCは同じような分布傾向であることが分かります。このため、成績とエンゲージメントの関係については明確ではありません。

ここで取り上げた成績とエンゲージメントの関係については、あくまで相関的な関係について考察していることに注意しましょう。これまでの可視化分析にも共通して言えることですが、データの可視化や相関係数による分析で語れるのは過去のデータ傾向までであって、因果を示すものではありません。
因果関係を考察したい場合には、変数同士の影響の方向性を注意深く捉える必要がありますが、計測済みの観察データから分析することは簡単ではありません。また、相関に基づく予測と因果推論は同義ではない点に注意が必要です。
上の議論をここで持ち出したのは、業績とエンゲージメントの関係を推測したいという潜在的なニーズがあるからです。この場合は、エンゲージメントが高い組織と業績の関係に着目していることになります。
一方、今回の分析テーマは現状把握でした。これら二つのテーマは趣旨とアプローチが大きく異なるものです。これは一見すると当たり前の議論に見えますが、データを探索していじり倒していくうちに目的がすり替わってしまう場合もしばしばあります。
もし分析中に新しい着想が出た場合は一旦メモをしておき、再び元の目的に戻って分析を進めることをお薦めします。新しい分析テーマにはその目的に沿ったアプローチを考える必要があるからです。
◆グレードとエンゲージメントの関係
グレードとエンゲージメントの関係を分析していきます。これまでと同様にビーズウォーム・プロットを使うのがよさそうですが、今回は分布形状を滑らかに見るためバイオリンプロットを使ってみました。これを見ると、Eを除いて管理職・一般社員を問わず同じような傾向であることが分かりました。

バイオリンプロットは箱ひげ図の情報も含みながら、分布形状を滑らかに示してくるで大変便利です。特にカテゴリ毎のデータが多くてビーズウォーム・プロットが適さない状況で分布形状を把握したい場合に役立ちます。
一方、上図のカテゴリEを見ると分布の下限が0を下回る表現がなされていました。このように、バイオリンプロットは滑らかな曲線で表現するがゆえに、上端と下端でミスリードに繋がる表現となる場合もありますのでご注意ください。
◆所属とエンゲージメントの関係
所属とエンゲージメントの関係を見ていきましょう。カテゴリ数がそれなりにありますので、ビーズウォーム・プロットを利用してみました。下図を見ると、これまでの分析よりもくっきりと傾向が出ているように見受けられます。他の所属と比較して営業部と経理部のエンゲージメントが低い傾向があります。

上の図をよく見てみると営業部ではピークが2つあることが分かります。そこで、所属の中の構造を細分化するものとして、グループ(課に相当)別に見てみることにしました。

上図を見ると、営業部のエンゲージメントのピークを形成していたのはグループであることが分かりました。また、ひとかたまりに見えた開発部についても、グループ毎に傾向に違いありそうです。
ここまでの分析結果を総合すると、個人に紐づく属性の中では組織・職場に何かヒントがあるのではないかと洞察できます。
◆労務関連実績とエンゲージメントの関係
最後に時間外勤務や年休消化率とエンゲージメントの関係を分析していきます。俯瞰的な分析のところでこれらは相関係数が明確には出ていませんでしたが、詳細を把握するため散布図を使って分析してみました。


時間外時間数と年休消化率それぞれ散布図で見てみましたが、明示的な関係があるとは言い難いですね。本ケースでは、定量分析だけでは、エンゲージメントの文脈において労務環境上の問題点を見出せないと考えます。
まとめ
初期分析とは言えなかなか長い分析となりました。ここまでの探索的分析で得られた手掛かりは以下の点になります。
30代・50代のエンゲージメントのばらつきが大きく、年齢や年代のみでエンゲージメントが変化しているわけではななさそう。(分析のきっかけとなった仮説の否定)
所属(部)やグループ(課)によって、エンゲージメントの傾向が大きく異なる。
たくさん図を描いて分析してきましたが、得られた手掛かりが意外と少ないことに気づかれたでしょうか。実際の分析実務でもよくあることです。また、その手掛かりもズバッと施策に結びつくようなものではなく、さらなる調査・分析が必要になりそうです。
所属特性とエンゲージメントの傾向分析
ここからは人でなく所属・組織といったマネジメントの単位に着目して分析をしていきます。所属に着目するというアイデアは人事データ分析の切り口(基本戦術)でも取り上げています。
所属によって、組織ミッションや業務特性、管理職のマネジメント力や影響力、労働環境などが異なることが想定されます。こうした情報はその職場で働くひとたちに何らかの影響を与えていると想定され、今回のエンゲージメント分析でも仮説として検討していきます。
一方、所属にまつわる情報は明示されていないことも多く、また組織ミッションのように文章的なものでガチっとした定量分析に利用しにくい状況も多くあります。こうした状況において、分析上どういう手を打っていけばよいでしょうか。
本来であれば、所属長や所属員と対話をしながら状況を捉えていくことが必要でしょう。今回はそうしたアクションが並走していると仮定し、その上で分析者としてできることを考えていきます。
所属毎にデータを集約
まず初手として、所属毎に各種人事情報を集約していくことが考えられます。先ほどの分析で、所属(部)だけでなくグループ(課)に着目した方がよさそうだということが分かりましたので、所属とグループを集約単位として量的変数の平均値をまとめてみました。

こうした集約表を用いて分析していくことも可能です。一方、先ほどまでの分析で利用してきた項目も多く含まれていますので、その平均値のみに着目しても深い分析に至るとは限りません。もう一工夫必要ですね。
所属の文化を作っているのは誰だろうか?
もう一度、所属・グループ別のエンゲージメントの傾向を示す図を見てみましょう。

各グループで傾向が異なるということは、グループに潜む文化やマネジメントスタイルに違いがある可能性があると考えることもできます。しかしながら、こうした情報は深いサーベイを行わないと見えてきません。
そこで、一つのアイデアとして、グループを引っ張っている管理職やリーダークラスの人材の特性を集約してみたいと思います。全データからグレードがMまたはLの人を抽出し、コンピテンシーの平均値を算出したのが下表になります。

数値で見るとグループで傾向が異なっているようにも見えますが、はっきりしません。そこで、ヒートマップを使って可視化してみました。ヒートマップはマトリックスやクロス集計用の値に応じて色付け見やすくしたものです。(下図)

こちらのヒートマップでは値が大きくなるほど青色が濃くなるように表現されています。これを見ると、大まかな傾向として所属の管理職やリーダーが持ち合わせているコンピテンシーの特性に違いがありそうだということが分かります。これは所属やグループを特徴付ける情報として活用できそうですね。
管理職等のコンピテンシーとエンゲージメントの関係
それでは、所属・グループ毎の平均的なエンゲージメントと、管理職・リーダークラスのコンピテンシーの関係を分析していきましょう。
まずは相関係数で大まかな傾向を見てみました。これを見ると、エンゲージメント、コンピテンシーの中のチームワークとの間に正の相関がありそうなことが分かります。

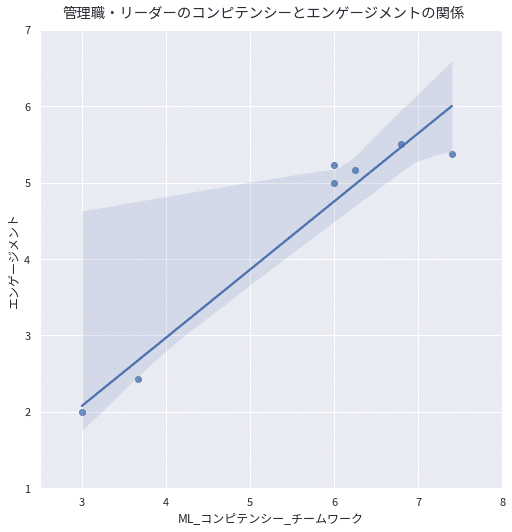
より深く分析するため、チームワークとエンゲージメントの関係を散布図と回帰直線をフィットさせて見てみます。下図を見ると確かに右肩上がりに見えますが、直線から大きく外れている値もあることが分かります。

もう少し分析を深めるために、上記の散布図の各点がどの所属であるかわかるように可視化してみました(下図)。所属を色で、グループをマーカーの形状で区別しています。これを見ると、研究部だけが外れているように見えます。

そこで、研究部を除いた状態で散布図を描き回帰直線をフィットさせてみました。先ほどよりはっきりしてきましたが、何分データ量が少なすぎて信頼区間も大きく広がっており、この結果だけで強く結論付けるのはリスクが高そうです。しかし、大まかな傾向として、研究部を除くと管理職・リーダークラスのコンピテンシー(チームワーク)に着目する意義はありそうです。
分析を深掘りするため、再び従業員毎のデータに戻り、その各行に対して所属するグループの管理職・リーダークラスのコンピテンシーを結合したデータを作成します。

こちらのデータを使って、エンゲージメントとグループの管理職・リーダークラスのコンピテンシーとの関係を分析してみます。ここでは、先ほど高い相関が出たチームワークに着目し、散布図で分析してみました。また、先ほどと同じく研究部を除いたデータに対して散布図と回帰直線をフィットさせています。
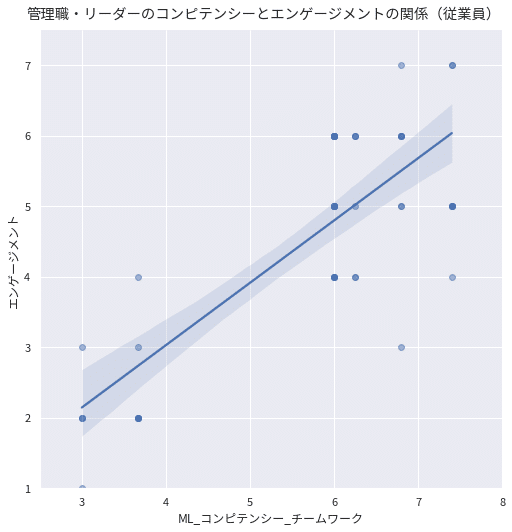
こちらの散布図を見ると所属単位のデータよりもデータが増えているため、ある信頼区間が広がっているようです。しかし、点の重なりも多く、少しモヤモヤしますね。そこで、密度を可視化できる手法を使ってみました。こちらの図を見ると左下から右上に向かって分布している様子が分かります。一方、上の散布図からも考察できるように、エンゲージメントとチームワークが低いクラスターと、高いクラスターに2分している様子も分かります。

そこで、再び研究部のデータも加えて密度による分析を行ってみました。こちらを見ると、全体としては3つのクラスターが形成されていることが分かります。

まとめ
所属特性をデータからわかる範囲で特徴付けし、エンゲージメントとの関係を探っていきました。分析過程と結果からもわかるように、定量的な分析だけでくっきりとした考察に至るのは難しいこともありますが、今回の例題では以下の点が洞察できました。
管理職・リーダークラスのコンピテンシー(チームワーク)とエンゲージメントの間には正の相関がある。ただし、研究部はこの傾向から外れており、別の要素を検討すべきである。
エンゲージメントとチームワークが共に低いクラスターと、共に低い高いクラスターに2分している。これらのクラスターの状況を把握するために、所属長や従業員へのインタビューを行う価値はあるかもしれない。
最後に
ここまで人の属性や所属特性を切り口として、様々な分析を行ってきました。多くのグラフを描きながらなかなか洞察に至らないプロセスにお疲れの方もいらっしゃると思います。こんなとき、相関係数による分析のように、ワンタッチで分析できたら楽ですね。しかし、実務では演習とは違って答えを探すための作業とは異なりますので、一筋縄では行きません。仮にくっきりとした分析結果が出ても、あくまで観測データの範囲内での考察しかできませんので、現実世界を100パーセント捉えることは難しいでしょう。
今回のケースでは私が個人的に作成したデータを利用していますが、作成者である私自信も迷いながら分析していきました。データを作ってから半年以上経過していたので、データ生成のメカニズムの記憶が薄れた状態で分析したからです。その意味で、この長い分析の過程は実務での分析を思い出すようなものでした。
さて、最後に「おまけ」をひとつ。
今回の例題で取り上げたエンゲージメントの値は、「まとめ」に記載した傾向が出るようにいくつかの要素を薄くミックスして生成したものでした。したがって、複雑な要素が絡み合い、変数同士の関連をグラフで一つ一つ見たり相関係数を分析したりするだけでは結論に至らない設計になっていました。
ところが、この記事を作成するために従業員データや所属特徴のマトリックスに対して相関分析をしてみたところ、設計上全く考慮していない変数同士の相関係数が高くなっているところがいくつかありました。これらは記事では取り上げていません。「たまたま」生じた相関関係の怖さを実感した次第です。偶然ではありますが、非常に示唆に満ちた話だと思います。
気が付くと非常に長い記事になってしまいました。記事を分割することも考えたのですが、一旦このままで投稿したいと思います。お付き合いいただきありがとうございました。
参考情報:
記事作成にあたり利用したデータ分析環境はPython, pandas, seabornです。また、トイデータはGoogle スプレッドシート上で悩みながら作成しました。
この記事が気に入ったらサポートをしてみませんか?