
『ゼロから作るDeep Learning ❺ 』 まえがき公開

ここでは、『ゼロから作るDeep Learning ❺ ―生成モデル編』の「まえがき」を公開しています。どういう本か気になる方は、参考にしていただけると幸いです。
まえがき
2022年——新型コロナウイルスが猛威を振るう中、この年はAIの分野において大きな進展が見られました。私たちの想像を遥かに超える画像をAIが生み出すようになったのです。有名どころではStable Diffusion、Midjourney、DALL·Eなどが挙げられます。そのような画像生成AIは様々な分野で注目を集め、多岐にわたる用途に活用されています。特筆すべきは、これらAIの背後において、ディープラーニングによる「生成モデル」の技術が使われていることです。2022年は、言うなれば、生成モデルで培われた技術が一気に花開いた年とも言えるでしょう。
本書のテーマは生成モデルです。生成モデルとは新しいデータを生み出す技術のことです。本書は生成モデルをテーマとして、古典的なものから最先端の技術までを幅広く扱います。本書で学ぶ内容は、正規分布や最尤(さいゆう)推定といった基本的な内容からスタートします。そして、混合ガウスモデルやEMアルゴリズムを学び、その後にディープラーニングを使った手法へと進みます。具体的には、変分オートエンコーダ(VAE)、階層型VAE、拡散モデルを順に作り、その理論と実装の両面を学びます。
本書で最終的に作り上げる拡散モデルは、その優れた性能から生成AIの分野に革命をもたらしました。本書では拡散モデルという頂を目指します。そして、その過程を「10のステップ」に分けて進みます。この10のステップは連続したストーリーとして展開され、ステップごとに生成モデルに関する重要な技術を学びます。
面白さは細部に宿る
本書は一切の手抜きをせずに、生成モデルの仕組みを解き明かします。イメージや結果だけを伝えるのではなく、「なぜそうなるのか」「どのようにその結果が得られるのか」ということについて省略せずに説明します。そのためには数式を丁寧に扱いながら、細かい点にまで注意を払う必要があります。結局のところ技術の細部まで学ぶことが、技術を深く理解する上では欠かせません。そして、技術の細部にこそ面白さは詰まっています。
本書の前提知識としては、微積分や線形代数などの数学に加えて、Pythonの基礎知識が必要になります。ただし、それらは基礎的な内容で十分です。数学に関しては本書でも復習をしながら、着実に進む構成になっています。また本書では難解な数式が一部登場しますが、それらを読み飛ばしても本書全体の理解に影響がないように工夫しています。
節や章(ステップ)の見出しに✪が付いているページは、高度な数式を扱っていることを示します。ただし✪ページは読み飛ばしても全体の理解に影響がないように配慮してあります。
本書のストーリー
「正規分布」から始まる旅は、10のステップを経て「拡散モデル」へ。
これが本書の全体像であり、骨格を成すストーリーです。このストーリーにも本書の特徴があり、面白さを詰め込んでいます。そこで先にその流れを把握してもらうため、ここでは本書の内容をダイジェストで話します。細部については、本書を通してじっくりと学びます(細部にも面白さがあるので、ご期待ください)。なお以降の内容は、本書の大きな流れだけを掴んでもらえれば問題ありません。途中で不明な箇所が出てくるかもしれませんが、本書を読み進めるうちに明らかになるでしょう。
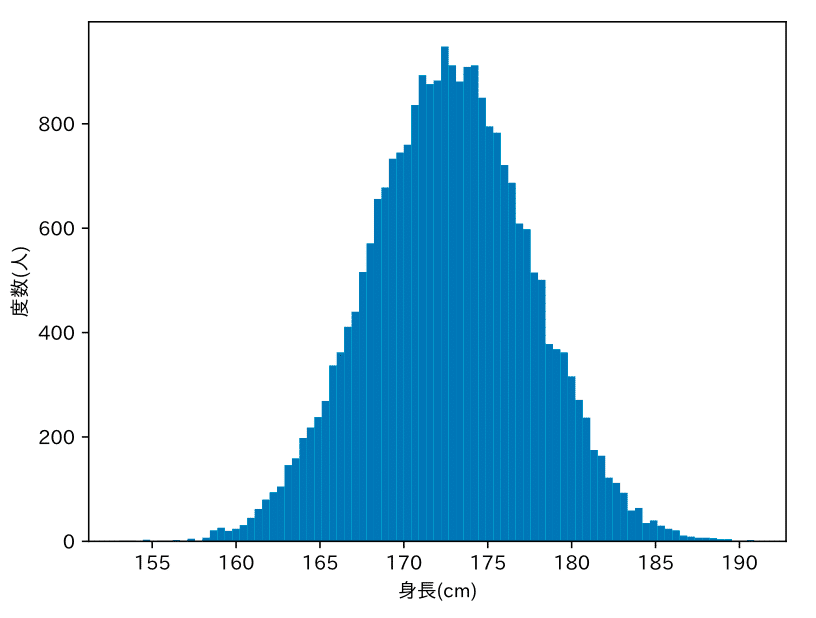
人の身長の分布
ここに同年齢の男性の集団がいます。この図はその集団の身長の分布です。左右対称の山の形をしています。このような形は「釣り鐘型」とも呼びます。生成モデルの目標は、この身長の分布を数学的に表現することです。
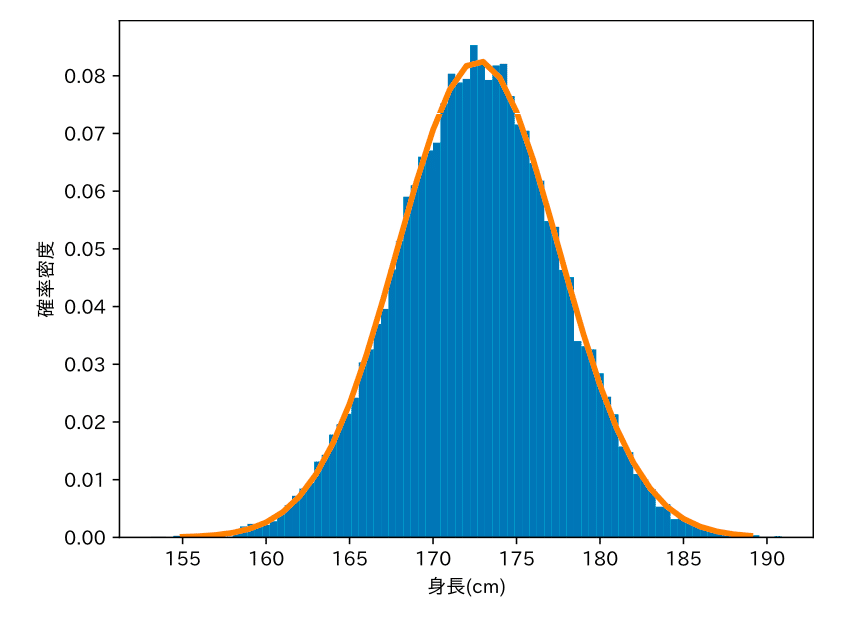
まずは正規分布から
正規分布は釣り鐘型のカーブで表される確率分布です。世の中には、正規分布で表せる分布が多く存在します。身長の分布も正規分布で表すことができます。正規分布は2つのパラメータ(平均 μ と標準偏差 σ )によって、その形が決まります。

最も尤(もっと)もらしい推定
正規分布のパラメータを調整して、データにフィットさせる(=適合させる)必要があります。そのための方法が「最尤(さいゆう)推定」です。最尤推定は、観測データ x の出現確率 p(x) が最も高くなるようにパラメータを推定する手法です。正規分布の最尤推定の解は、数式を解くことで簡単に求められます。
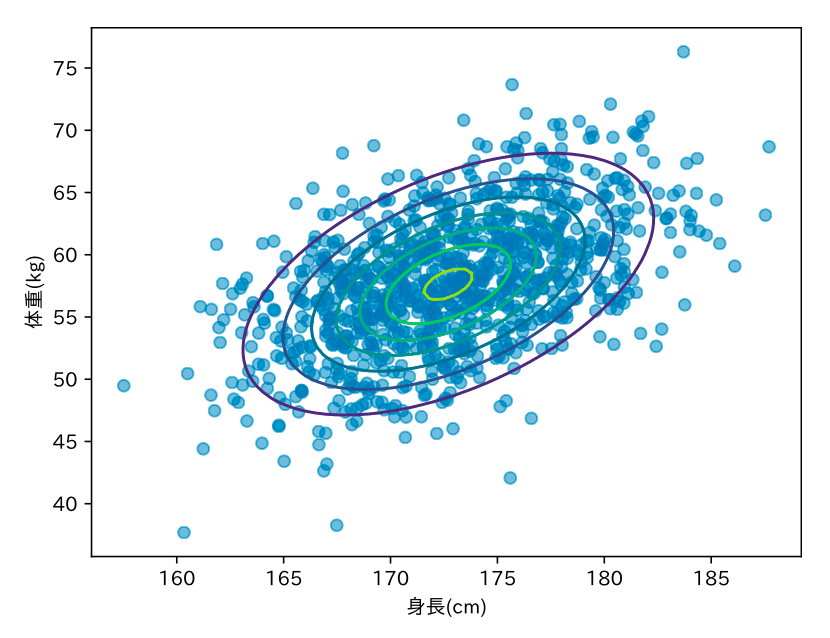
1次元から多次元へ
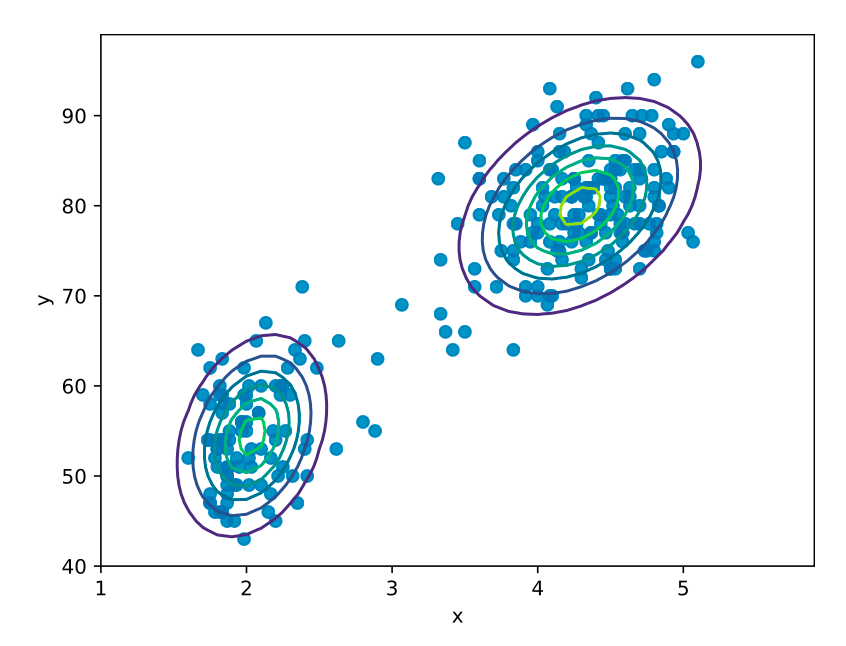
身長は1次元のデータでした。次に「身長」と「体重」の2次元のデータを考えます。これを可視化したものが次の図です。2次元データの場合も最尤推定により最適なパラメータを推定できます。図中の等高線は最尤推定後の2次元正規分布を表します。
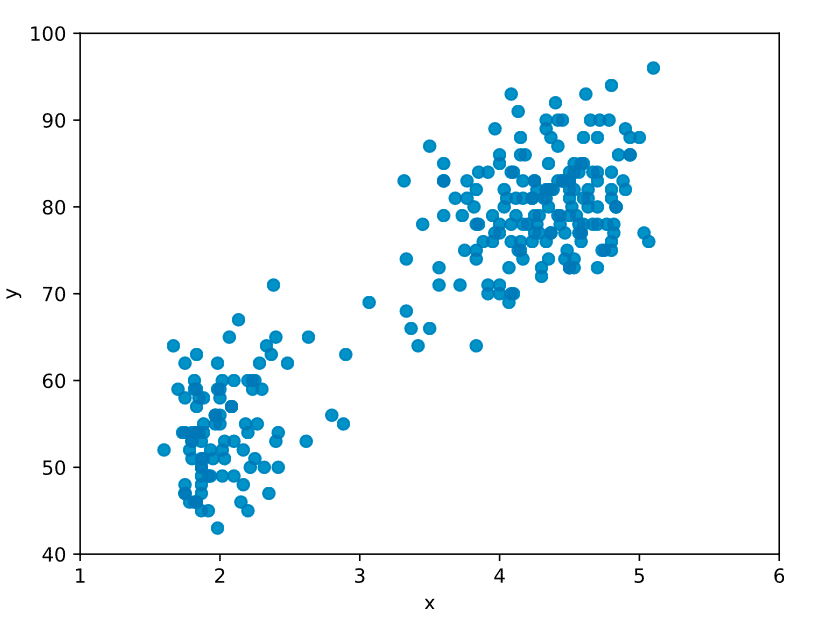
山が2つ
次の問題は、“2つの山”があるサンプルデータです。これを1つの正規分布で表すことは不適切です。そこで登場するのが「混合ガウスモデル」です。混合ガウスモデルは、複数の正規分布を組み合わせた手法です。2つの山も表現することができます。
見えないもの
2つの山を表現するには、データがどちらの山に属するかを表すために「潜在変数」を使います。潜在変数は直接的には観測できない変数です。一方、観測できるデータは観測変数と言います。次の図は、潜在変数 z から観測変数 x が生成される関係を表します。

潜在変数の代償
混合ガウスモデルは潜在変数があることでモデル(数式)が複雑になります。そのため、1つの正規分布のときのように、数式を解くだけで最尤推定の解を得ることができません。ここで登場するのが「EMアルゴリズム(Expectation-Maximization Algorithm)」です。EMアルゴリズムにより、最適なパラメータを推定でき、2つの山にもガウス分布をフィットさせることができます。
偉大なるニューラルネットワーク
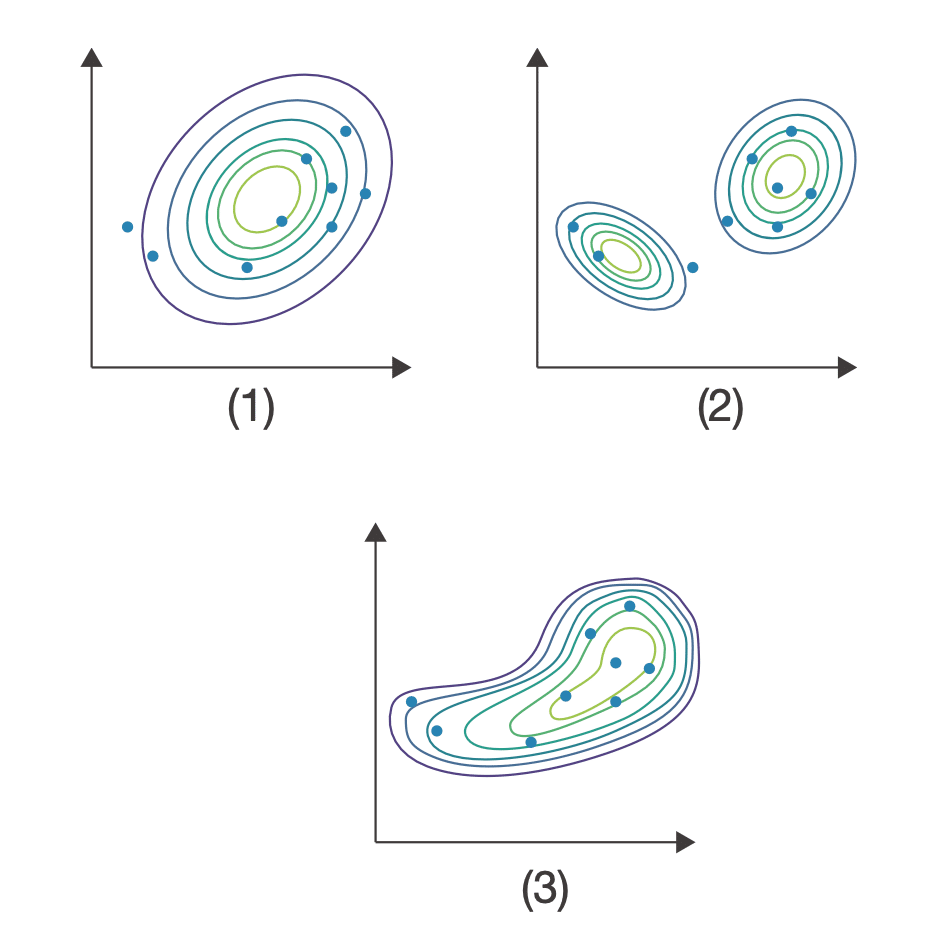
さらに先に進むために、ここでニューラルネットワークを登場させましょう。ニューラルネットワークを使うことで、よりサンプルデータにフィットした分布を学習させることができます。どのようなことが実現できるのかを図に示します。(1)は1つの正規分布、(2)は混合ガウスモデル、(3)はニューラルネットワークを取り入れた「VAE(Variational AutoEncoder:変分オートエンコーダ)」というモデルです。ニューラルネットワークを取り入れることで、(3)のようなデータに合わせて柔軟に形を変えることが期待できます。
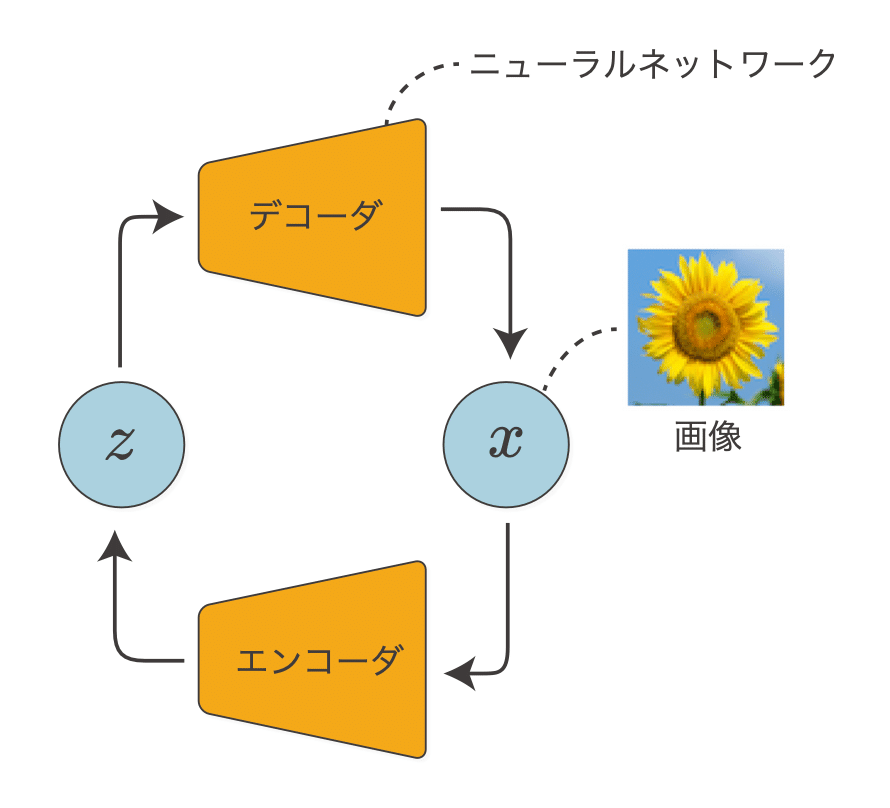
VAEで画像生成
VAEも、混合ガウスモデルと同じく潜在変数があるモデルです。潜在変数から観測変数への変換にニューラルネットワーク(=デコーダ)を使い、その逆の変換に別のニューラルネットワーク(=エンコーダ)を使います。VAEの学習アルゴリズムは、EMアルゴリズムを発展させる形で導くことができます。
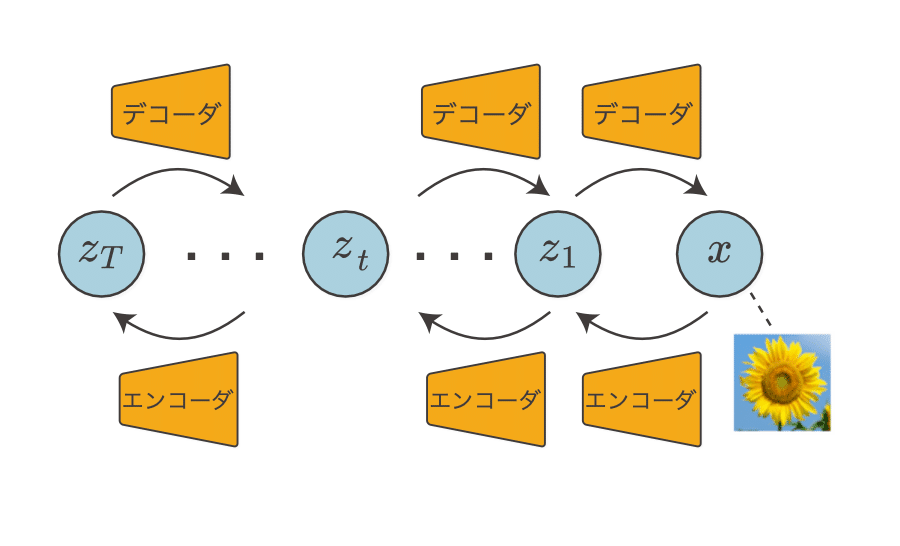
潜在変数の階層化
VAEは優れた表現力を持ちますが、潜在変数を階層化することにより、さらにVAEを進化させることができます。それが「階層型VAE」です。階層型VAEは、VAEの潜在変数が複数あるモデルです。潜在変数は、隣の潜在変数からのみ影響を受けます。この階層化によって、より複雑な表現が可能になります。
ノイズでデータを壊す
階層型VAEは潜在変数が増えるため、その分だけニューラルネットワークによる処理も増えます。そのため、処理時間の問題やパラメータ推定が困難になる問題などが生じえます。この問題を解消するため、観測変数から潜在変数への変換を、単にノイズ(正規分布から生成されるノイズ)を追加する処理に置き換えます。このアイデアを起点として「拡散モデル」を導くことができます。ノイズを足しながらデータを“壊す”過程を「拡散過程」と呼びます。
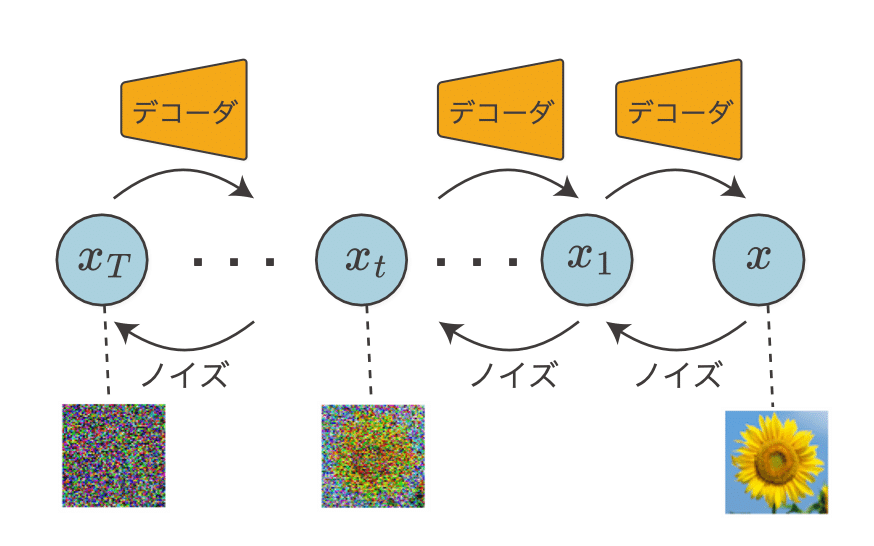
条件を入れる
ここまではデータ x の確率分布 p(x) をモデル化することがテーマでした。しかし実用的には、ある条件 y を与えたときの x の確率——数式では条件付き確率 p(x | y) で表されます——をモデル化することが望まれます。たとえば、数字の画像を生成する場合、条件なしの拡散モデルだとランダムに数字を生成します。一方、条件付き拡散モデルでは、“8”のようなクラスを条件 y として与えることで“8”の画像を生成することができます。

現代の画像生成AI
Stable Diffusionのような画像生成AIも、「条件付き拡散モデル」と原理は同じです。そこにいくつかの工夫が加えられ、図のような高精細な画像が生成されます。本書では、Stable Diffusionを始めとした現代の画像生成AIで使われる技術を概観します。

* * * * * * *
以上が本書のダイジェストです。最初から最後まで繋がりのあるストーリーで、重要な技術を関連付け、改善しながら前へ前へと進みます。このストーリーについても楽しんでもらえれば幸いです。さあ、準備は整いました。これから生成モデルの世界へと旅立ちます。本書によって、生成モデルの興味深さ、可能性、そしてその細部に詰まった面白さを堪能してもらえることを願っています。
本書では、拡散モデルや画像生成AIに焦点を当てています。ChatGPTに代表される大規模言語モデル(Large Language Model:LLM)に関しては、本シリーズの次回作で詳しく解説する予定です。
本書で使用するコード
本書で使用するコードは、次のGitHubリポジトリから入手できます。
https://github.com/oreilly-japan/deep-learning-from-scratch-5
ファイル構成は表 1 のとおりです。

プログラミング言語はPython(バージョン3.x)を使います。使用するライブラリは下記のとおりです。
NumPy
SciPy
Matplotlib
PyTorch(バージョン:2.x)
torchvision
tqdm
PyTorchはバージョン2.xを使用します。それ以外のライブラリについては、バージョンに依存せずに実行できると思われます。参考までに、本書で使用した各ライブラリのバージョンについては、上記GitHubリポジトリにあるrequirements.txtに記載してあります。
また、本書GitHubのトップページには図1の表があります。該当するボタンをクリックすることで、即座にGoogle ColabやKaggle Notebookなどのクラウドサービス上でNotebookを実行することができます。
以上が、『ゼロから作るDeep Learning ❺』の「まえがき」です。良かったら続きも読んでみてください。面白いですよ、生成モデル!
この記事が気に入ったらサポートをしてみませんか?