
【W7】活性予測のための機械学習モデル_14_Step3_08_ANN_WF実行

【W7の目的】
ターゲット分子(EGFR)に対して新規な化合物の活性を予測するために、様々な教師あり機械学習(supervised ML)アルゴリズムを使用する方法について学習します。
前回でRProp MLP Learnerノードのおかげでニューラルネットワークが簡便に体験できるのだと話してきました。
ではいよいよ実行結果を見てみましょう。
【WFの流れをおさらい】
ニューラルネットワーク(NN)で、k分割交差検証しつつ予測するワークフロー(WF)をおさらいしましょう。

ランダムフォレスト(RF)での同様のWFを詳しめに説明したので、その記事を参考にしつつ以下各ノードの設定など見ていきます。
【X-Partitioner】
RF用のX-Partitionerと完全に設定が同じです。
Random seedまで一致していますので、10回に分けるデータセットも完全に一致します。
例えばですがデモデータで10回目の分割時のTest dataを見比べてみましょう。下の出力ポートを見てみると
RF: X-Partitioner (#246)
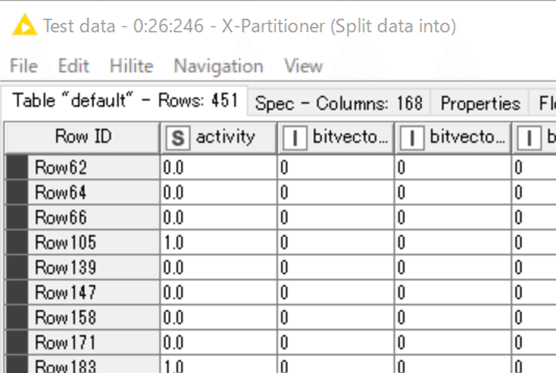
NN: X-Partitioner (#263)

選ばれた化合物群は一緒ですね。RFとNNは同じ学習データで学んで、同じTest dataを予測した結果を返しています。
【余談: ノードのID番号表示】
#の後の番号はノードのID番号です
メニューの目玉のアイコンをクリックして表示をオン・オフできます。
その右のアイコンだとノード名表示をオン・オフできるんですけど、オフしたいときってどういう時ですか?
「さあ、このWFのこの絵のノードでは何をしてるでしょうか!」みたいなクイズでもするんかな。
【RProp MLP Learner】
機能説明で2章に分けたのはこのノードが初めてでしたね。
設定:

ご覧の通りこのノード、本来は設定を工夫すべき(ハイパー)パラメータがあります。
でも今回はデモデータの設定のままです。
Number of hidden layersの数などを増やしていけば深層学習ですから底なしですよー。今回は意図的にさらっと流します。
些細な疑問なんですが、Random seedに-416818657を選ぶのはどんな気持ちの時だろう。
【MultiLayerPerception Predictor】
Learnerで作られたモデルの実行ノードです。日本語化されたディスクリプションを引用します。
インポートで与えられたトレーニング済みのMultiLayerPerceptionモデルに基づいて、期待される出力値が計算されます。
今回の設定はこちら

今回はクラス判別モデルなので
各ニューロンの出力と勝者ニューロンのクラスが生成されます
とのこと。
Append columns with class probabilitiesにチェックが入れてあるので、クラス別の確率が予測されて出力されます。そして最も高い確率すなわち勝者ニューロンのクラス名が文字列データとして出力されます。
結果:デモデータで10回目の分割時のTest data予測結果

【X-Aggregator】
上記のデータを含め、10回ループしたすべての予測結果を集計します。
設定:

RFの場合と設定は同じでした。
【実行時間を計ってみた】
まだ3層ですし、4511化合物のデータ数ですからそんなに計算時間はかからないです。
下図のようにTimer Infoノードをくっつけて、X-PartitionerをリセットしてからTimer Infoノードを実行してみました。

結果は下表の通り。PCの仕様や状態に左右されてしまうのですが、今回は

RProp MLP Learnerも77秒ほどでモデル作成を完了できました。かわいい感じです。伝わらんか。
予測精度はRFの際と同じく今のところはOverall Accuracyのみ取り上げておきます。

デフォルト設定でも0.809となかなかの好成績でした。
以上でANNの体験学習は終わりです。次回からはこれまたディープなサポートベクターマシンです。
おまけ:
【深層学習は玄人の御業】
NNを多層化すればディープニューラルネットワークすなわち深層学習となるはずなので、今回は深層学習も本当に浅ーいところをちょっとだけ勉強したことになると思います。
RProp MLP Learnerは下記の3つの設定を変えることが可能です。
① Maximum number of iterations
学習の反復回数です。
② Number of hidden layers
ニューラルネットワークのアーキテクチャにおける隠れ層の数を指定します。
③ Number of hidden neurons per layer
各隠れ層に含まれるニューロンの数を指定します。
TeachOpenCADDのW7では
①は100回,②は3層,③は5個との設定でした。
それぞれどれぐらいの幅でスクリーニングするものなのかが知りたいです。きっと入力データの数や分布、モデルの目的などで工夫されるのでしょうね。実際のMLPモデルのトレーニングはどのあたりを工夫するものなのか、藤さんから一例を挙げていただきました。
これらのハイパーパラメータの最適化がポイントで、色々と試行錯誤する部分です。
考え方としては一応、隠れ層を増やせばニューラルネットワークのパフォーマンスは向上しますが、メモリや演算量も増えてしまいます。
ニューロンの数は、画像解析ですと良く層が深くなるごとに徐々に減らしたりしています(512 -> 256 -> 128のように)。
隠れ層のノード数が一定なものもよくやられているように思います(512 -> 512 -> 512のように)。
ただ、これもノード数が多い程、メモリや演算量が増えていきますので、計算時間や予測精度、メモリの量などとのバランスになってきます。
学習の反復数については、損失関数の値や、予測精度が収束する(プラトーに達する)のに十分な数を設定出来れば良いので、学習過程でこれらの値をモニタリングして、反復数が足りなければ増やして学習をし直せば良いと思います。
上記の3つだけでも最適化を目指せば大変であることは推察されました。
アドバンストな内容で難しそうではありますが、基本やることは変わらず、誤差(損失関数)を小さく出来れば良いです。
まずはデフォルト値で試して、満足いく精度が得られなければ、ハイパーパラメータを調整していくことになります。
どれを変えれば良いのかよくわからないので、これらを最適化するツールとしてPreferred Networksが開発したOptunaなどが出てきています。
変えたい数値の範囲などを指定して、あとは自動で最適なハイパーパラメータの組み合わせを探索させるツールになります。
とはいえ、これはこれで結構大変な作業なので、デフォルトのハイパーパラメータで上手く行かない場合には、パラメータの調整は専門家に任せたいところですね。
さらにscikit-learnのMLP classifierの記事を見つけて、「あ、素人は手を出してはいけないのでは」と気づいたのでここまでとします。玄人の皆さん、頑張ってください!
パラメータ最適化の話ではないですが、最近見かけた下記のtwitterも印象深かった。
機械学習初心者から良くある質問で「モデルのアーキテクチャをどう考えて決めたらいいですか?」というのがある。本当に高い精度を出したい時、素人がイチから考えたアーキテクチャが勝つことなどまずない。
— Shinya Yuki (@shinya_elix) February 5, 2022
それと同じで組織づくりも素人イチから考えたアイディアが勝つことなどまずないんだと思う。
機械学習初心者から良くある質問で「モデルのアーキテクチャをどう考えて決めたらいいですか?」というのがある。本当に高い精度を出したい時、素人がイチから考えたアーキテクチャが勝つことなどまずない。
生兵法は大怪我の基。失礼しました。
記事を読んでいただきありがとうございます。 先人の智慧をお借りしつつ、みなさんに役立つ情報が届けられたらと願っています。 もしサポートいただけるなら、そのお金はKNIMEの無料勉強会の開催資金に充てようと思います。