
【W7】活性予測のための機械学習モデル_09_Step3_03_ランダムフォレスト

【W7の目的】
ターゲット分子(EGFR)に対して新規な化合物の活性を予測するために、様々な教師あり機械学習(supervised ML)アルゴリズムを使用する方法について学習します。
さて機械学習概要はすでに話題にしました。
今日は機械学習のスタンダード手法とも思えるランダムフォレスト(RF)を体験します。
【KNIMEのRF教材決定版】
RFをKNIMEで学ぶならこの記事を最初に紹介すべきかと思います。
以前,ブログで「Bootstrap」と「Decision Tree」についてそれぞれ紹介しました.
Bootstrap SamplingとDecision Treeを組み合わせた機械学習の手法が「Random Forest」です.
ということで、ブログの連作記事でKNIMEのworkflow(WF)をつかって丁寧にRFの仕組みを教えてくださっています。必読!
上記の素晴らしい3記事を読んでおられる想定ですと、私から新たに足せる技術情報はないと思います。割愛しますね(笑)
さらにRFをより学びたい場合もmagattacaさんの記事にしっかりフォローされてます。
今回のトピックに関連して日本語で読める記事をいくつかご紹介いたします。
ぬかりなし!さすがにまるっと引用は憚られたので原典をご覧ください。
【ランダムフォレストでの交差検証WF】

入力データはStep2の4511行全てです。
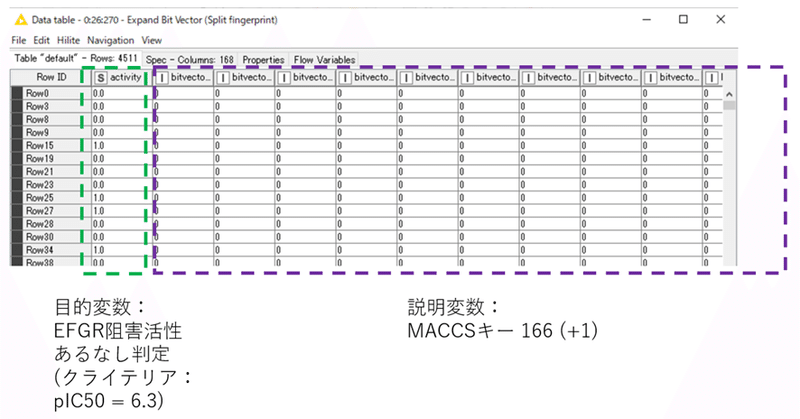
【X-Partitioner】
t-kahiさんの説明記事を引用させていただきます。
「X-Partitioner」の設定においては,"Number of validations"でK-分割交差検証のkを設定します.続いてサンプルの取得の方法ですが,今回は"Species"で均等になるようにサンプル取得を行います.
また,"Random seed"を設定しておくことで,同じ乱数設定で何度も実験をすることができます.
最後の"leave-one-out"にチェックを入れれば,leave-one-out 交差検証となります.

W7でも同様に下図の設定となっています。
設定:

Random Seedってなんだろうと言う方にはこちらをおすすめしておきます。
実行結果は4ノードまとめて後で。
【Random Forest Learner】
t-kahiさんの説明の丁寧さには感服です。
<再掲>https://www.t-kahi.com/entry/2019/07/18/202710
日本語化したノードディスクリプションも引用しておきます。
任意の数の決定木からなるランダムフォレスト*を学習します。
各決定木モデルは、異なる行(レコード)のセットで構築され、木の中の各分割には、ランダムに選択された列(属性を表す)のセットが使用されます。
各決定木の行セットはブートストラップにより作成され、元の入力テーブルと同じサイズになります。
設定:
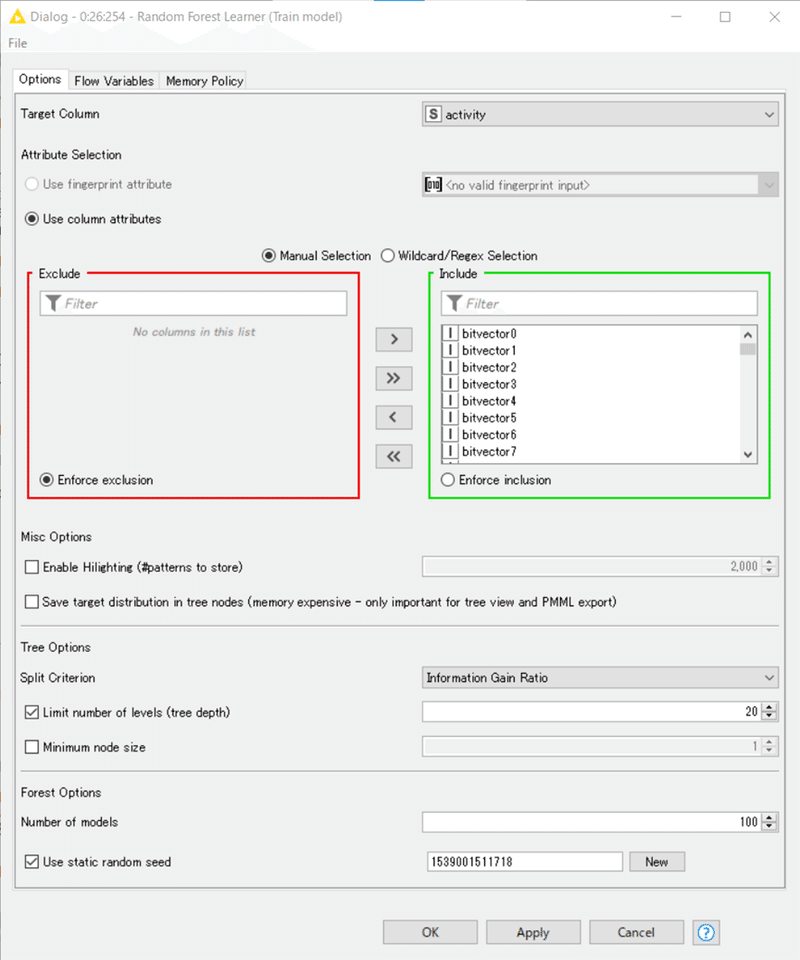
t-kahiさんとハイパーパラメーター設定が結構異なっています。予測したい対象の性質に合わせて適切に設定するのが望ましいそうです。
例えば
Limit number of levels (tree depth)
学習する木のレベルの数。
例えば、値が1の場合、ルートノード(1つ)のみを分割し、結果的に判断の切り札となる。
「深さ」と呼ばれることが多いと思います。今回は20を最深としています。実際に20まで行ったら深めな印象です。
Number of models
学習される決定木の数。
ほとんどのデータセットでは、100から500の間の値で良い結果が得られますが、最適な数はデータに依存するため、パラメータのチューニングが必要です。
「決定木の数」ですね。今回は100。デフォルト設定から変えていないようです。
ハイパーパラメーターチューニングに関しては後日また。
【Random Forest Predictor】
t-kahiさんの説明通りで、設定変更は特に必要ないです。
設定:

日本語化されたディスクリプションよりメニューの説明を抜粋します。
Append overall prediction confidence
予測されたクラスの信頼度です。
すべての信頼値の最大値です(別々に付記することも可能です)。
Append individual class probabilities
各クラスについて、予測の信頼度。
これは、現在のクラスを予測する木の数(列名による)を、木の総数で割ったものです。
「Random Forest Predictor」は先ほどのLearnerと比べるとシンプルな設定で,モデルのノードとテストデータを繋げて実行します.
得られた結果は以下のように,元データに予測カラムが追加された形で出力されます.
X-Partitionerの上のポートから学習データ(デモデータだと全体の9割)を受け取りRandom Forest Learnerノードがモデルを構築し、そのモデルの情報をグレー色の四角のポート間でRandom Forest Predictorが受け取ります。

X-Partitionerの下のポートからテストデータ(デモデータだと全体の1割)を受け取って、そのMACCSフィンガープリントのデータ群を説明変数として、Random Forest Predictorが目的変数である「activity」のある(=1.0)なし(=0.0)を予測判定して出力します。
結果:(activityカラムは並べ替えてあります)
全体(4511行)の1割にあたる451行の予測結果です。10回分割した10回目の予測結果がデモデータには記録されていますね。1~9回までのデータとは次のX-Aggregatorでまとめられます。

予測精度の成績評価は次のStepで実施します(私の投稿ペースだと数か月先に書くと思いますが)。
【X-Aggregator】
X-Partitionerで設定した分割回数分のループ処理を実施し、集計するためのノードです。デモデータは10分割交差検証ですから10回ループが回ります。
設定:

結果:
今回は10回分まとめた結果を見ます。

カラフルなBar表示に驚きましたが、入っているデータは先ほどと同じく実数値(0から1の予測されたクラスの信頼度の値)なので、下図のようにカラム名のところを右クリックして、Standard Doubleに変えるのもいいかと思います。

上記の例だとConfidence(信頼度)も0.8以上と高めなのに判別ミスがいくつかあります。そんなこともあります。
以下感想ですが結構自信満々に間違えていて「潔いな!」と感じました、科学的でない表現ですみません。
Step3のRF部分は完了です。
さて、次回の内容ですが、折角のKNIMEで簡便にRFの10分割交差検証を体験できるのですから、次回はあえてループの途中で止めてデータの流れを追ってみます。
おまけ:
元旦から始めたのにもう春がすぐそこですね…
結城浩さんの下記のnoteは心に残っています。
私は今機械学習の学習記録をnoteに書いているわけですが、投稿を1週間に1回程度と決めて、1回に1000~2000字程度、数週先の分まで書き溜められるペースを維持しています。週末などに前に書いた文章を読み返し、思い出し、間違いに気付き、足りない部分を学び直し、先へと進めます。
今、この文章を書く前に、結城浩さんのnoteを読み返しました。
「お、私は焦りがちな状況であっても、ゆっくり落ち着いた対処ができているな。私は状況をコントロールしているぞ」
それはとても大切な気づきだなぁと思いました。あやかりたいものです。
W7の説明を始めたけど、一体いつまで時間をかけるつもりだ!?と思っている方が10人中9人以上と推測しています(読者が10人いると自信があるわけではないです)。
一方で、書いている私の方は、内容理解が追い付いてないけど先に進んでしまっているなぁと思いながら毎週投稿しています。それでも、ゆっくりと自分が学びたいことを学ぶことができることを愉しみながら続けます。よろしければ引き続きまた。
ところで、
「わざとゆっくり書く」と言う言葉で、小早川隆景を思い出す方って現代の日本人の何%なんだろう。1%いるかなぁ。
記事を読んでいただきありがとうございます。 先人の智慧をお借りしつつ、みなさんに役立つ情報が届けられたらと願っています。 もしサポートいただけるなら、そのお金はKNIMEの無料勉強会の開催資金に充てようと思います。