
【W7】活性予測のための機械学習モデル_18_Step4_Scorer_and_ROC_Curve

【W7の目的】
ターゲット分子(EGFR)に対して新規な化合物の活性を予測するために、様々な教師あり機械学習(supervised ML)アルゴリズムを使用する方法について学習します。
W7を勉強し始めたのは2022年元旦でしたが既に春過ぎて夏来にけらし。

上図のW7のメタノード内を3ヶ月以上かけて体験してきて、
ようやく機械学習アルゴリズムについての最終パートに来ています。
前回までで各種アルゴリズムでの機械学習部分を体験したので、その性能を比較することにします。

W7のKNIME workflow (WF)ではこの部分もStep3とされているのですが、工程としては分かれているのでStep4と呼んだ方が良いと思います。
アルゴリズムごとに結果を見たいときはここを使いますが、上図のMetanodeの外にある下図のコンポーネントを利用したアルゴリズム間比較用のダッシュボードも紹介します。

【アルゴリズムごとの評価画面をちょっと編集】
各アルゴリズムの予測結果を解析し、予測精度を可視化するのが下図のコンポーネントです。
ただし、実はダッシュボードの設定を修正しないとまとめて見られません。
中に含まれているそれぞれのノード別なら閲覧は出来ます。
理由は画面表示の設定が正しくなされていなかったからのようです。
上記のコンポーネントを開いた状態で下図のアイコンをクリックすると画面表示のレイアウトを編集できます。


そこで、今回デモデータでは上記のようになっていたコンポーネントの画面表示設定を下図のように変えてみました。
clear layoutボタンで下図のように初期化し、

Viewsからドラッグアンドドロップで編集しました。

結果はコンポーネントを実行して閲覧できます。


【混同行列と正解率】
分類モデルの評価については下記記事を紹介しておきます
物事は常に1つの基準で評価できるわけではありません。機械学習による分類問題も例外ではなく、その分類の目的に応じて、評価指標を使い分ける必要があります。
とのことで学ぶべきことはまた多くありそうなのですが、記事の引用に留めます。

上記の記事より混同行列の図を示します。
そして、指標は数あれど今回は正解率のみ使って話します。
正解率とは、その名の通り「全ての予測のうち、正解した予測の割合」を指します。非常にシンプルで直感的にも解釈しやすい指標です。
先ほどコンポーネントで視覚化したランダムフォレストでの結果を計算してみると、4511化合物を予測し、正解したすべての化合物すなわちTNとTPの和が1392+2325=3717なので正解率は82.40%と算出されています。

まあ別に関数電卓の図はいらんやろとお思いでしょうが、自分でも検算すると何となくわかった感が出たので。
正解率を機械学習モデルの性能評価に使うのには注意点があるそうです。
しかし、例えば機械の異常検知など、ほとんどがNegativeで稀にPositiveが出現するような、偏りが大きいデータを扱う場合にはあまり有効な評価指標とは言えません。
今回の真偽の分布は不均衡というほど偏ってはいないことを確認してあるので良しとしました。
【ROC Curve】
ROC曲線は、横軸に偽陽性率(false positive rate,FPR)を、縦軸に再現率(Recall, true positive rate, TPR)をとる曲線です。
AUC(Area Under the Curve)は
曲線の下側の面積の大きさで分類予測を評価する指標です。面積は0から1の範囲で変動し、AUCが大きいほど優れた予測だと言うことができます。
上図を見ていただければ、よりオレンジの線に近づくとAUCが大きくなる、すなわち1に近づくことが直観的に理解できると思います。

https://www.codexa.net/ml-evaluation-cls/
ROC曲線は、横軸に偽陽性率(false positive rate,FPR)を、縦軸に再現率(Recall, true positive rate, TPR)をとる曲線です。
AUC(Area Under the Curve)は
曲線の下側の面積の大きさで分類予測を評価する指標です。面積は0から1の範囲で変動し、AUCが大きいほど優れた予測だと言うことができます。
上図を見ていただければ、よりオレンジの線に近づくとAUCが大きくなる、すなわち1に近づくことが直観的に理解できると思います。
先ほどのランダムフォレストの結果を見てみます。

ちなみに緑で丸を付けた十字矢印のアイコンで各ウィンドウを最大化したりできます。
以上で大まかに見方を紹介したところで、アルゴリズム間の比較用画面に移ります。
【比較用コンポーネント】
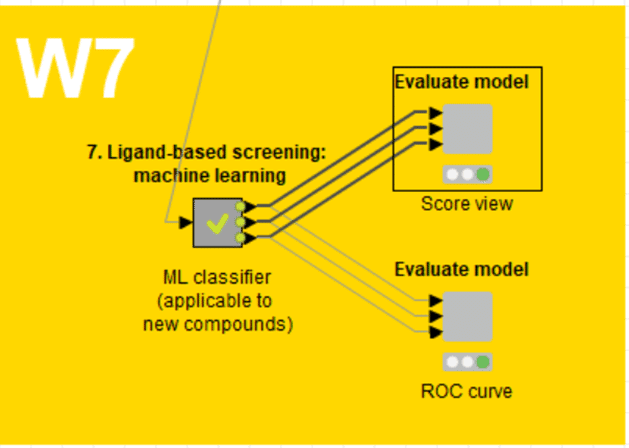
数か月ぶりにW7のメタノードの外へ出てきました。
まずはScore Viewと書かれたコンポーネントを閲覧しましょう。



SVMの混同行列の特異さが見て取れると思います。
もう一つのコンポーネントでROC曲線も並べてみましょう。
順番をそろえるため並べ替えますので混乱しないでくださいね。
ANNより

SVMは

RFは

一見すると大きく違って見えませんね。ところがSVMだけ描画条件が異なっています。
そこで条件をそろえて書き直してみました。


ROC曲線はアルゴリズム間で一見して違いが分かりにくい印象でした。
ただし私が何にもわかってないだけかもしれないです。
しかも本来は下記の記事の通りAUCの差の検定を行うことになるようで、私がなにかコメントできるレベルの話ではないようでしたのでここまでに。
おまけ:
【SVMの予測精度改善に向けて】
上記の結果でW7のWFについて全ての体験を終えはしたのですが、SVMについてはこのままでいいのかなぁと思いました。このようにただ結果をうのみにするのではなく自分で何かしてみたいと思わせてくれると言う意味でなかなかにひねった教材になっていると思います。
そこで次回はWFの改作をして、SVMのハイパーパラメータチューニングに挑もうと思います。
幸い先人たちの貴重な情報提供があるので、まねっこしてみます。
アナタは先の方
ずっと先の方
追いつきたいなら今はTRY
https://www.uta-net.com/song/268027/
記事を読んでいただきありがとうございます。 先人の智慧をお借りしつつ、みなさんに役立つ情報が届けられたらと願っています。 もしサポートいただけるなら、そのお金はKNIMEの無料勉強会の開催資金に充てようと思います。