【W7】活性予測のための機械学習モデル_03_Step aside

【W7の目的】
ターゲット分子(EGFR)に対して新規な化合物の活性を予測するために、様々な教師あり機械学習(supervised ML)アルゴリズムを使用する方法について学習します。
(参照)
【二値分類を始める前に】
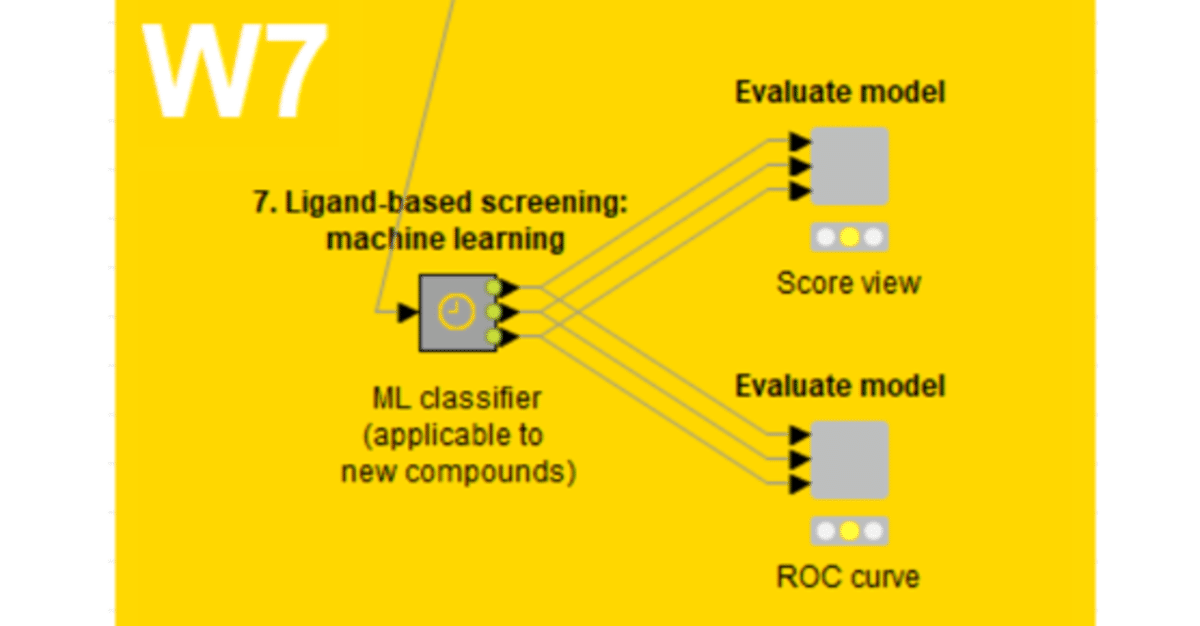
Ligand-based screening: machine learningメタノード

のStep1まで見てきました。1ノードだけですが。

二値分類を教師あり機械学習アルゴリズムで実施する前に、データの分布なども見ておこうと思います。データが不均衡だと十分な性能が得難いこともあるためです。
【Value Counter】
今回活性のあるなしをpIC50 = 6.3で判定した真偽値activityの分布を見てみましょう。
こういう目的にはValue Counterがお手軽です。
このNodeは、確認用によく使います。設定はほぼいらないのでパッと使えるのがいいところです。
Value Counterノードを繋いで、


数を数えるカラムを指定して「OK」
実行結果は

お手軽ですね。
不均衡というほど偏ってはいないです。
ひとまず安心して次のStep2へ進められそうです。
これがもしクライテリアをpIC50 = 9 (IC50 = 1nM)にしちゃったら
(Math Formulaノードで$pIC50$ > 9として実行した結果)

まさに不均衡なので、活性あり化合物を精度高く分類しようと思うと機械学習モデルを作る前にデータを前処理しておく必要が生じると思います。
今回Step1ではおそらくクライテリア設定時に程よい設定に工夫されたのかなと推測しています。
【不均衡データとその対策について】
不均衡データを扱うときの工夫などはこちらが参考になりそうでした。
世にあふれる情報を活用して学習を進めるなら、Pythonが基本言語になっている気がします。
SMOTE(Synthetic Minority Oversampling Technique) のKNIMEでの実装例もありました。丁寧な説明に感謝しつつ紹介します。
この記事もいつか体験記を書いてみたいと思いました。
さて寄り道が過ぎたのでそろそろ次へ進めます。
次回はStep2を体験します。
おまけ:
【課題設定時に結果は定まる】
このW7の課題を選んだ理由については詳しく語られてはいないです。
以下は素人の全くの私見ですが、
今回W7の課題をEGFR阻害活性に関してカットオフ6.3で活性と不活性に分類して、その判別をすると設定したのは、このモデルが機械学習初心者へのデモデータとしてわかりやすい結果が得られるように考えられているのではないかと推測しています。
上記の「機械学習における問題設定の重要性」という記事を読むと
適切な問題設定をするためには?
1. 分類問題、もしくは回帰問題に帰着させられるか?
2. 問題を解決した場合、デメリットよりもメリットの方が大きいか?
3. 問題の解決に必要なデータセットは揃っているか?
を考えるべきとのことでした。
創薬化学者は活性予測と聞いたらpIC50を当てて欲しいと期待しがちです。ところがその問題はかなり難易度が高いです。
予測手法としては例えば、
理論ベースの量子シミュレーションと、データから学習させる機械学習の二 つの方法が存在する。量子シミュレーションでは、正確性は担保されるが膨大な計算コストが必要である。 機械学習では、比較的計算コストが低いが精度に難がある。両者は目的に応じて使い分けられている。
<参考>
https://www.jst.go.jp/crds/pdf/2020/FR/CRDS-FY2020-FR-04/CRDS-FY2020-FR-04_20104.pdf
今でも計算化学者が自分たちの提供する予測手法のScope & Limitationを確認しつつ最前線で活用している技術なので入門教材には不向きかもしれません。
一方で、今回EGFR阻害活性を活性/不活性に分類する問題は適切なクライテリア設定ができれば比較的扱いやすい題材です。
問題を解くための機械学習アルゴリズムは既存のKNIMEノードで実装できるし、比較的短時間で実行できます。そして4511化合物ものデータを入手できるアッセイ結果が公開されています。創薬研究の現場で数千データも使って学習できる活性予測は少ないので、恵まれた条件での良い結果(予測精度)を体験できる点で入門教材としてよさそうです。TeachOpenCADDの設計初期からここまで見通していたのかもしれないですね。知らんけど。
<参考>
機械学習アプリケーションを効率的に構築するためには、複数のフレームを検討し、最も簡単だと判断したものから始めることが重要。
さて連想はさらに膨らみます。
もう5年ほど前になりますが、あるAI創薬の研究者の方から、「機械学習モデル構築を研究する時には、まず問題を定め、その評価方法を決めます。そして各種検討を行う際、その問題と評価方法を変えてはいけません」と最初に教えられました。
実際には意外に途中でうまく行かないからそのモデルの利用目的や評価方法を変えてしまうってことがある気がします。敢えて最初に強調されたのではと今になって思い返しているところです。以上よもやま話でした。
記事を読んでいただきありがとうございます。 先人の智慧をお借りしつつ、みなさんに役立つ情報が届けられたらと願っています。 もしサポートいただけるなら、そのお金はKNIMEの無料勉強会の開催資金に充てようと思います。