
クラビスのプロダクトを支える心臓部。データ化基盤の裏側を大公開します!

こんにちは!クラビスの佐藤です。
本日は、クラビスが提供するプロダクト「STREAMED」の根幹に当たるデータ化について大公開いたします!
AI x OCRを駆使して、会計業務の課題を解決している「STREAMED」。
実際にどのような仕組みで運営されているか技術者の視点から語っていただくべく、データ化の基盤を開発しているDockチームのリーダー、平嶋さんにお話を伺いました!
ーーーー

<プロフィール>
前職では、SIerにて仕様作成や顧客との折衝など上流工程を担当。クラビスではデータ化システムを開発するdockチームにジョインし社会人になってはじめて大規模なサービスでコードを書くことにチャレンジ。以後、上流の知見を活かしつつ開発スキルを伸ばし、現在はデータ化に関わるシステムを開発しているdockチームのリーダーとして活躍。既に公開済みキャリアについてのインタビュー記事もぜひご覧ください)
ーーーー
佐藤:年始のエンジニアインタビュー第一弾でお話しいただいて以来、ご無沙汰しております!
平嶋:ご無沙汰しております(笑)
佐藤:前回は、クラビスに入社した思いとプロダクトの可能性、今後の展望についてお話を伺ったのですが、今回は一歩踏み込んで、dockチームが手がけるデータ化についてお話を聞かせてください!
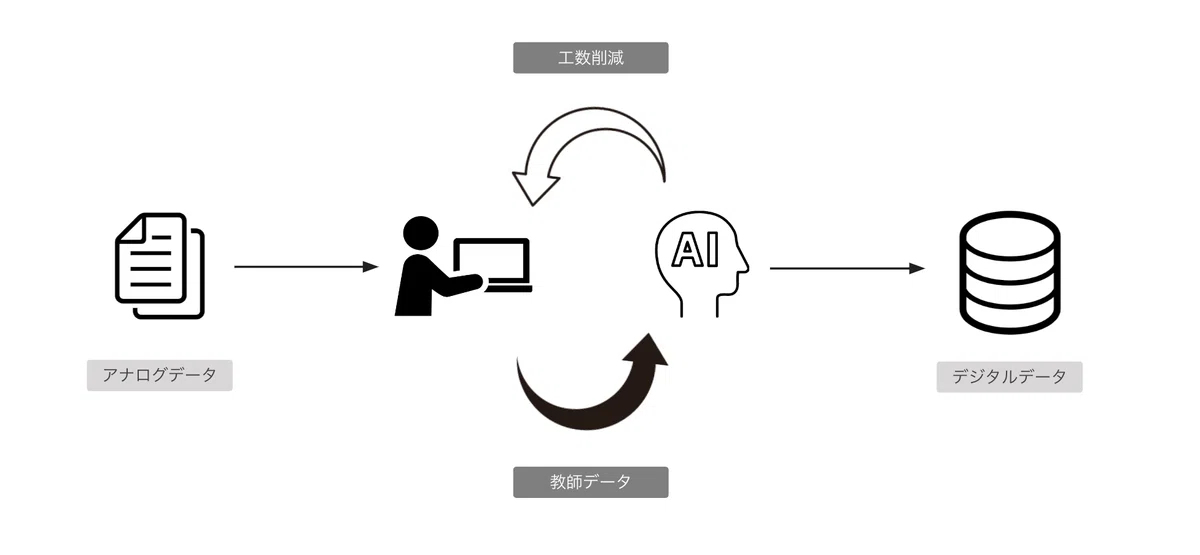
平嶋:わかりました。まずは開発しているプロダクトの全体像を話すと、クラビスでは現在、STREAMEDとクラウドインボイスという2つのプロダクトを提供しています。このプロダクトはどちらも会計に関わる紙などのアナログデータを、AIやオペレータが中身を読み取り会計に使えるデジタルデータへ変換(データ化と呼んでいます)することをコア機能にしています。データ化は、AIだけでなくオペレータという人力を組み合わせることで非常に高い正確性を実現しつつスピードも早いことが特徴です。
少し古いですがマネーフォワードのIR資料に載せているSTREAMEDの売上を抜粋すると、18年11月期では2.5億円でしたが21年11月期では8.8億円となっており、短期間で実に3.5倍になりました。もちろんデータ化量もそれに比例して伸びています。急速に増えるデータ化を毎日納期通りにデータ化するためにはシステムの安定性はもちろんのこと、いかに効率的にデータ化をするかなど、色んなことを考慮する必要があります。
そんな二つのプロダクトのコアであるデータ化のシステムを開発しているのがdockチームです。データ化は止められないコア機能という意味でまさにプロダクトの心臓と呼べます。そんな心臓を守るdockチームはクラビスでも非常に重要な役割を担っています。

<プロダクトのコアを支えるデータ化>
佐藤:まさに心臓部ということですが、データ化と聞くと色々な方法があるのかなと感じるのですが、dockチームが手がけるデータ化はどのように作られてきたんですか?
平嶋:そうですね、データ化は、元々紙を1枚1枚オペレータが単純に手入力することから始めました。ただ、それだと何を改善することで生産性向上につながるのかの判断がつかないことや日々増えるデータ化に対して比例して人を増やし続ける必要がありました。
そこで、それらのネックを解消するためにデータ化工程を分解し、各工程に対してオペレータを適切にアサインする仕組みを作り上げ、AIの導入も進めました。
工程を分解することで、どの工程でどれくらい時間がかかっているのか生産性を可視化し改善することができるようになりました。それに加えて、各工程で見ると誰にでも作業しやすい単位になっているためオペレータの人数確保がしやすくなりました。そして、AIの導入によりオペレータの工数自体を減らすことができました。

佐藤:人の手とAIの両軸で効率化していったんですね。
平嶋:そうですね。課題に対して解決策を考え、技術を用いるということはプロダクト開発当初から続けています。AIの導入についても紹介したいんですが別の機会にゆずり、ここではオペレータの入力に焦点をあてて説明をしますね。
佐藤:お願いします!
平嶋:では、ここからはどのように入力工程を分解しているのか簡単にご紹介していきます。すごくざっくり説明すると種別の判定、入力箇所のマーク、入力に分解しています。
種別の判定では、例えば領収書と一括りに言っても印字や手書き、いわゆるレシートのような形もあればコンビニで公共料金を支払う特殊な形のものなど様々あり、それらをシステムで定めたカテゴリに振り分ける作業をしています。振り分けることで後工程を変えており、適切なオペレータをアサインすることにつながっています。
入力箇所のマークでは、領収書の画像から日付、金額、取引先などの入力に必要な部分だけをマークしています。AIでは全ての文字の読み取りをする精度は上がってきましたが、そこから適切な部分を抜き出すことがまだまだ難しいです。そのため、オペレータが補助することでデータ化の精度を高めることができています。
最後の入力では、1つ前の工程でマークされた入力箇所をひたすら入力をしています。入力箇所を探すことが不要になるため、オペレータは入力だけに集中して作業をすることができます。
こういった各工程でどれくらい入力に時間がかかっているのかを分析し日々改善をしています。システムによる効率化だけではなく、オペレータをマネジメントするチームとも連携しながらマニュアル化や教育などのアプローチもとっています。
<人が活躍できる仕組み>
佐藤:オペレーターが働きやすい仕組みがデータ化に寄与しているとのことですが、なぜこだわって開発したのでしょうか?
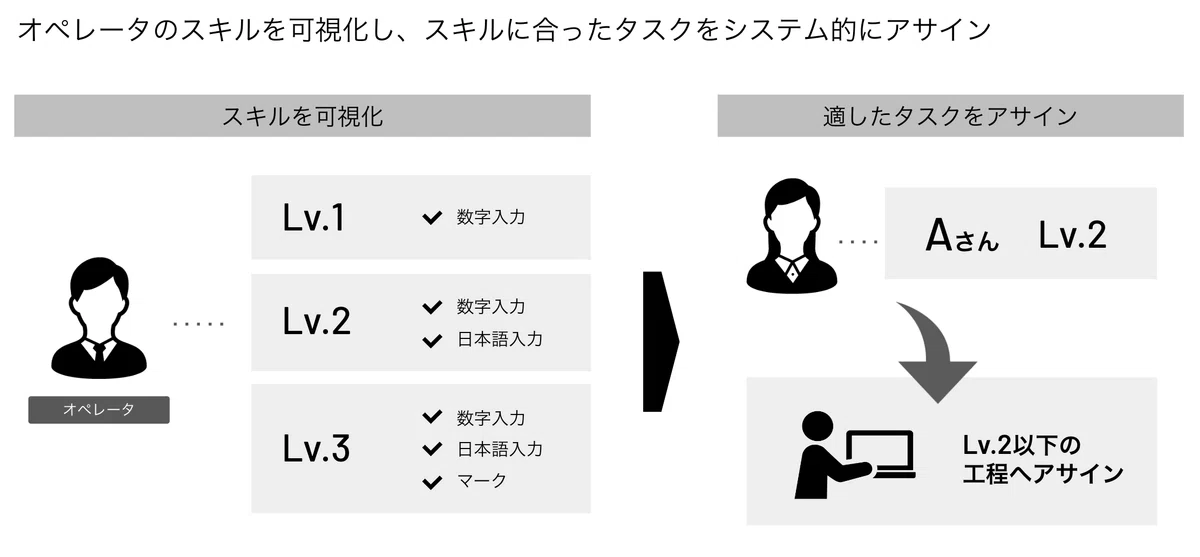
平嶋:そうですね、オペレータは実はほとんどがベトナムや中国など海外の方で構成されております。そのため、オペレータによって日本語の理解度が大きく異なります。そんな異なるスキルのオペレータに合った工程にアサインをすることが必要です。
そこで、dockチームでは各オペレータのスキルを可視化し適切な工程に自動でアサインする仕組みを作りました。簡単な例としては日本語が苦手だけど数字の入力ができるオペレータは数字入力できるというスキルの保持が可視化されていて、数字の入力工程だけアサインされるようにしています。以前は、各工程でオペレータのリソースが不足しているときに各入力拠点とチャット等でコミュニケーションをとりながら手動でアサインをしていたので、かなり工数を削減することができました。

よくオペレータでデータ化をしていますとだけ話すと、ただ画像を見ながら1人の人が単純に入力をし続けていると思われがちです。実は1つのデータ化が完了するまでに色んな工夫をこらしています。
これらは、業務を細分化することで、働き方や働く場所の自由度が上がり、生産性に直結する仕組みだと思っています。

<dockチームが目指す次のステップ>
佐藤:クラビスの業務を支えるdockチームは今後どのような開発をされる予定ですか?
平嶋:dockチームの開発で重要なことは、クラビスの行動指針の1つでもある「課題の本質を理解する」ことです。
例えば、日々のデータ化において、オペレーターはひたすら単純入力をしているわけではないですし、スキルを可視化し適切にアサインすることで、スキルに応じた仕事が可能になりました。これは、増え続けるデータ化をどうやって早く正確にユーザーにお返しできるのかを考え抜いた結果、実現できたことです。各オペレータの入力の早さを追求する、オペレータを大量に確保するなど課題の解決方法はいくつかありましたが、それを選びませんでした。というのも、目の前のデータ化をこなし続けるのではなく、中長期的にサービスが発展し続けることを妨げないことが課題の本質だと考えたためです。
人のアサインを自動化させるロジックは、早く正確なものを返すことに繋がりました。そのロジックを作った背景には、日本に限らずオフショアを含めたデータ化拠点の可能性を広げていく狙いもありました。
これからも今のアプローチを疑い続け、正しく課題を理解することに向き合い続けていきたいと考えています。
今回の記事では、dockチームが手がける「STREAMED」の裏側についてお話を伺いました。普段、表には出てこないプロダクトのコアな部分がイメージできましたでしょうか?
実は、オープンにできない技術的な部分も語っていただいていますので、ご興味ある方はカジュアル面談などお気軽にきてくださいね。
クラビスはこれからも大きく価値を拡大していくフェーズです。ユーザーに向き合い、本当に価値のあるプロダクトを生み出す技術を追求できる仲間を募集しています。
ここまで読んでいただいて、少しでも話を聞いてみたい、もっと働く人の顔をみてみたいという方はぜひ一度カジュアル面談をしませんか?
ご応募お待ちしております。
この記事が気に入ったらサポートをしてみませんか?