機械学習の最適化ツール(Pytorch):Early Stopping(早期終了)

1.概要
本記事ではPytorchでEarly Stoppingが実行できるようにします。
AIモデルを学習時にデータを”学習用(train)”と”検証用(val)”に分割して、学習用で学習させたモデルを検証用データで確認することで特定データへ過剰なフィッティング(過学習)をしていないか確認します。
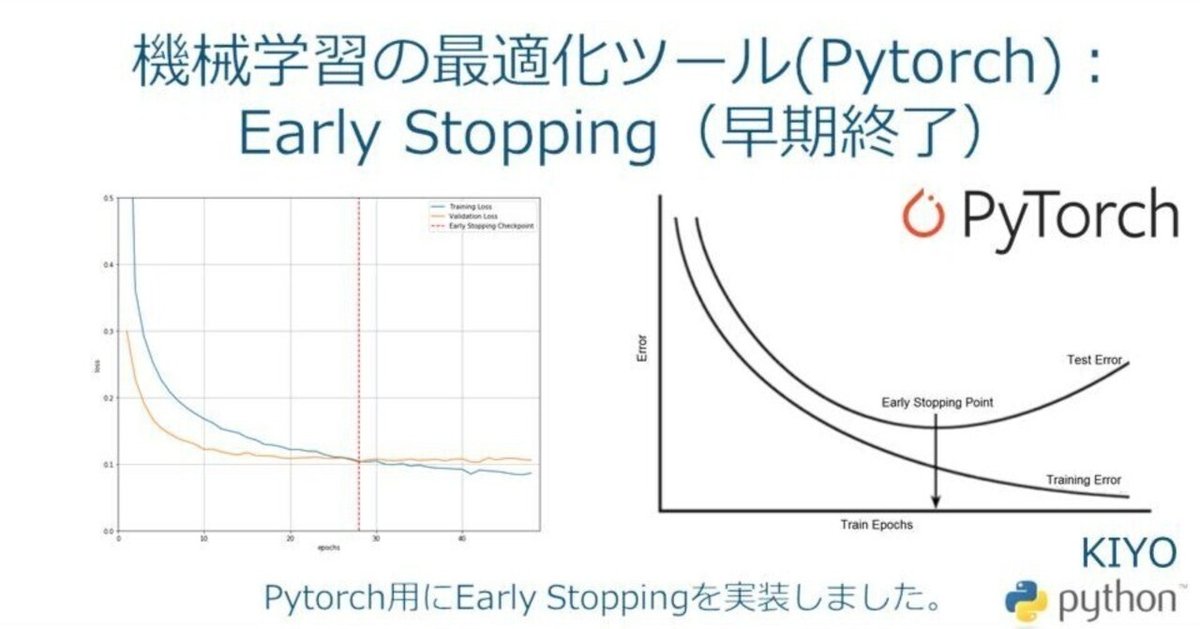
一般的には「学習用(train)の精度は上昇しても検証用(val)がどこかで頭打ち(または低下)していく」傾向があります(下図参照:OREILLY)。
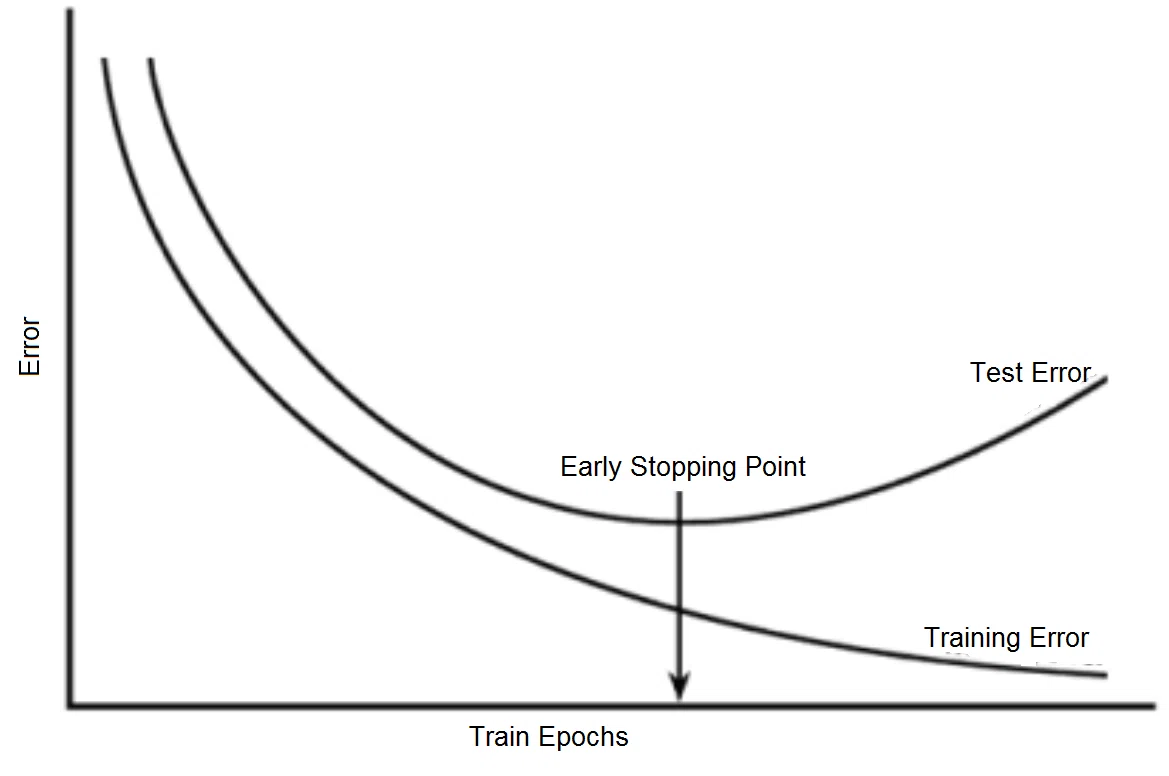
Early Stoppint(早終終了)とは過学習を避けるために行う正則化の一種であり学習用(train)に過剰適合して検証用(val)のエラーが大きくなる前に学習を中断する手法です。
2.自作Early Stoppingの実装
PytorchにはEarly Stoppingが実装されていません。次章では有志が作成した「GitHubに公開されたEarly Stopping」を使用しますが、まずは自作で理解を深めます。
2-1.サンプル用データの作成
Early Stoppingの動作が確認できるデータを作成します。Early Stoppingの設定は3回にするため下記サンプルではindex=8の箇所で終了します。
[IN]
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(1)
nums_random = [int(np.random.randint(0, 8, 1)) for _ in range(12)]
print(nums_random)
plt.plot(nums_random), plt.xticks(range(12))
plt.grid()
[OUT]
[5, 3, 4, 0, 7, 1, 3, 5, 7, 0, 0, 1]
2-2.Early Stoppingのコード
基本的な実装の思想は下記の通りです。
クラスとして作成してクラス内の変数に前回の値(機械学習ならloss値)や前の値から連続で超過した回数などを保持させる
出力はTrue/False:値が指定回数より連続で増加したらTrue
verbose(詳細)を設定して”print('early stopping')”を実行させるか調整
(簡易モデルのため)最大性能時のパラメータは記憶できない
機械学習の学習時(for文による学習ループ)における検証(val)のloss※を監視して"if early_stopping(loss_val): break"とすることで早期終了できます。
※訓練(train)データではないことに注意
[IN]
class EarlyStopping:
def __init__(self, patience=10, verbose=0):
'''
Parameters:
patience(int): 監視するエポック数(デフォルトは10)
verbose(int): 早期終了の出力フラグ
出力(1),出力しない(0)
'''
self.epoch = 0 # 監視中のエポック数のカウンターを初期
self.pre_loss = float('inf') # 比較対象の損失を無限大'inf'で初期化
self.patience = patience # 監視対象のエポック数をパラメーターで初期化
self.verbose = verbose # 早期終了メッセージの出力フラグをパラメーターで初期化
def __call__(self, current_loss):
'''
Parameters:
current_loss(float): 1エポック終了後の検証データの損失
Return:
True:監視回数の上限までに前エポックの損失を超えた場合
False:監視回数の上限までに前エポックの損失を超えない場合
'''
if self.pre_loss < current_loss: # 前エポックの損失より大きくなった場合
self.epoch += 1 # カウンターを1増やす
if self.epoch > self.patience: # 監視回数の上限に達した場合
if self.verbose: # 早期終了のフラグが1の場合
print('early stopping')
return True # 学習を終了するTrueを返す
else: # 前エポックの損失以下の場合
self.epoch = 0 # カウンターを0に戻す
self.pre_loss = current_loss # 損失の値を更新す
return False[IN]
early_stopping = EarlyStopping(patience=3,
verbose=1)
for idx, num in enumerate(nums_random):
print(f'Index:{idx}, count:{early_stopping.epoch}, 前の値:{early_stopping.pre_loss}, 現在の値:{num}')
num_pre = num
if early_stopping(num):
print(f'count:{early_stopping.epoch}, 前の値:{early_stopping.pre_loss}, 現在の値:{num}')
break
[OUT]
Index:0, count:0, 前の値:inf, 現在の値:5
Index:1, count:0, 前の値:5, 現在の値:3
Index:2, count:0, 前の値:3, 現在の値:4
Index:3, count:1, 前の値:3, 現在の値:0
Index:4, count:0, 前の値:0, 現在の値:7
Index:5, count:1, 前の値:0, 現在の値:1
Index:6, count:2, 前の値:0, 現在の値:3
Index:7, count:3, 前の値:0, 現在の値:5
early stopping
count:4, 前の値:0, 現在の値:53.PytorchによるEarly stoppingの実装
他の方が既に使いやすい形でPytorch用のEarly Stoppingを実装されているため、私は自作ではなくこちらを使用します。特徴は下記の通りです。
Pytorch向けで作成されたモジュール(事前にPytorchの環境構築が必要)
GitHubに公開している”pytorchtool.py”モジュールのみで実行可能
ベストのモデルパラメータはearly_stopping.pathに保存されるため読み込みが可能(※検証データ(訓練時)のベストであるためテストデータで必ず最高性能がでる保証はない)
3-1.モジュールのコード確認
なお”pytorchtool.py”モジュールの中身は下記の通りであり、こちらをコピペしても使用可能です。
【pytorchtool.pyの引数】
●patience (int: defalt=7): val lossが上がり続ける(改善されない)回数
●verbose (bool:default=False): Trueなら各val lossを表示
●delta (float: default=0): 変化があると判断する最小値
●path (str:defalut=checkpoint.pt): 保存するcheckpointのパス
->デフォルトならval_lossが最も低い(最高性能)時のパラメータのデータを含む"checkpoint.pt"ファイルが作成される。
●trace_func (function:default=print): trace print function.
[pytorchtools.py]
import numpy as np
import torch
class EarlyStopping:
"""Early stops the training if validation loss doesn't improve after a given patience."""
def __init__(self, patience=7, verbose=False, delta=0, path='checkpoint.pt', trace_func=print):
"""
Args:
patience (int): How long to wait after last time validation loss improved.
Default: 7
verbose (bool): If True, prints a message for each validation loss improvement.
Default: False
delta (float): Minimum change in the monitored quantity to qualify as an improvement.
Default: 0
path (str): Path for the checkpoint to be saved to.
Default: 'checkpoint.pt'
trace_func (function): trace print function.
Default: print
"""
self.patience = patience
self.verbose = verbose
self.counter = 0
self.best_score = None
self.early_stop = False
self.val_loss_min = np.Inf
self.delta = delta
self.path = path
self.trace_func = trace_func
def __call__(self, val_loss, model):
score = -val_loss
if self.best_score is None:
self.best_score = score
self.save_checkpoint(val_loss, model)
elif score < self.best_score + self.delta:
self.counter += 1
self.trace_func(f'EarlyStopping counter: {self.counter} out of {self.patience}')
if self.counter >= self.patience:
self.early_stop = True
else:
self.best_score = score
self.save_checkpoint(val_loss, model)
self.counter = 0
def save_checkpoint(self, val_loss, model):
'''Saves model when validation loss decrease.'''
if self.verbose:
self.trace_func(f'Validation loss decreased ({self.val_loss_min:.6f} --> {val_loss:.6f}). Saving model ...')
torch.save(model.state_dict(), self.path)
self.val_loss_min = val_loss3-2.環境構築
下記コードを実行すると”early-stopping-pytorch”フォルダが作成されます。ハイフンがあるモジュールはPythonでimportできないため、”early-stopping-pytorch”フォルダから"pytorchtools.py"だけ抜き出します。
[Terminal]
git clone https://github.com/Bjarten/early-stopping-pytorch.git
3-3.Early Stoppingの使用方法:pytorchtools.py
流れとしては下記の通りです。
モジュールのimport:from pytorchtools import EarlyStopping
インスタンス化:early_stopping = EarlyStopping()
Loss値を計算後に"early_stopping(val_loss, model)"を実行
学習ループの最後に”if early_stopping.early_stop: break”を実行
サンプルとして上記を拝借しました。
[Sample]
from pytorchtools import EarlyStopping
early_stopping = EarlyStopping(patience=10, verbose=True)
# モデルの定義など割愛 以下学習部分の簡易コード
model.train()
for e in epochs:
# ここで学習
...
# トレーニングデータの使用終了
model.eval()
...
val_loss = xxxx
early_stopping(val_loss, model) # 最良モデルならモデルパラメータ保存
if early_stopping.early_stop:
# 一定epochだけval_lossが最低値を更新しなかった場合、ここに入り学習を終了
break3-4.最適モデルの読み込み:model.load_state_dict(torch.load(early_stopping.path))
Early Stoppingクラスを実行すると"checkpoint.pt"ファイルが作成され、最もval_lossが低い(最高スコア)時のパラメータを保存しております。
"torch.load(<model/paramのpath>)"で学習済みモデル(パラメータ)を読み込み"model.load_state_dict()"でモデルにパラメータを上書きします。
model.load_state_dict(torch.load(early_stopping.path))4.実装サンプル:Digit Recognizer
"pytorchtools.py"はPytorchのモデルを保存させるためモデルの作成が必要です。サンプルとして下記記事のコードにEarly stoppingを実装しました。
細かいコードは記事に記載しているため実装部分だけ紹介します。
[IN]
from pytorchtools import EarlyStopping #EarlyStoppingの実装
early_stopping = EarlyStopping(patience=10,
verbose=True) #EarlyStoppingの設定
for epoch in tqdm(range(epochs)):
train_loss, train_acc = 0, 0
val_loss, val_acc = 0, 0
#訓練フェーズ
net.train()
count = 0
for imgs, labels in zip(x_train_minibatch, y_train_minibatch):
count += len(labels) #データ数をカウント
#学習フェーズ
optimizer.zero_grad() #勾配の初期化
outputs = net(imgs) #順伝播(出力の計算)
loss = criterion(outputs, labels) #損失関数の計算
loss.backward()
optimizer.step() #パラメータ更新
#ロギングデータの更新
train_loss += loss.item() #損失関数の合計を計算
y_pred = torch.max(outputs, 1)[1]
train_acc += (y_pred == labels).sum().item() #正解数を計算
loss_train_avg = train_loss / count #損失関数の平均を計算
loss_acc_avg = train_acc / count #正解率の平均を計算
#検証フェーズ
net.eval()
count = 0
for imgs, labels in zip(x_val_minibatch, y_val_minibatch):
count += len(labels) #データ数をカウント
#推論フェーズ
outputs = net(imgs) #順伝播(出力の計算)
loss = criterion(outputs, labels) #損失関数の計算
#ロギングデータの更新
val_loss += loss.item() #損失関数の合計を計算
y_pred = torch.max(outputs, 1)[1]
val_acc += (y_pred == labels).sum().item() #正解数を計算
loss_val_avg = val_loss / count #損失関数の平均を計算
loss_acc_avg = val_acc / count #正解率の平均を計算
#学習結果の表示/ロギング
if epoch % 10 == 0:
print(f'epoch: {epoch}, loss_train: {loss_train_avg:.4f}, loss_val: {loss_val_avg:.4f}, acc_train: {loss_acc_avg:.4f}, acc_val: {loss_acc_avg:.4f}')
logging_epoch(logs['train'], epoch=epoch, loss=loss_train_avg, accuracy=loss_acc_avg)
logging_epoch(logs['val'], epoch=epoch, loss=loss_val_avg, accuracy=loss_acc_avg)
#EarlyStoppingの実装
early_stopping(loss_val_avg, net)
if early_stopping.early_stop:
break
[OUT]
checkpoint.pt が作成される
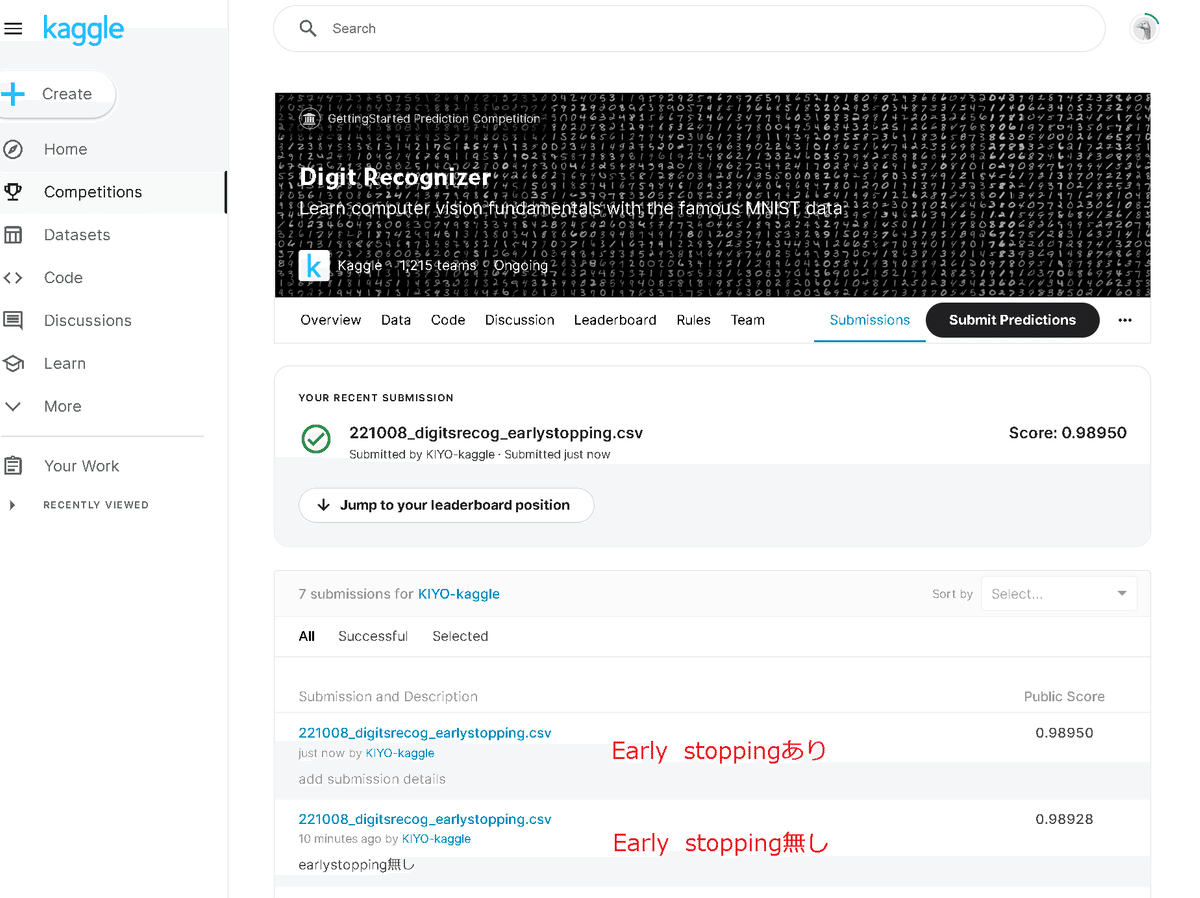
(モデルのインスタンスをnetとしたため)下記を実行すると訓練時のベストモデルを読み込めます。下記を実行前後で性能を比較しました。
net.load_state_dict(torch.load(early_stopping.path))今回の結果ではEarly Stoppingをかけた方がよい性能がでました。なお必ずEarly Stoppingの結果の方がよいわけでもないためストレージがたんまりあるならEarly Stopping前後でデータを保存しておく方が便利です。
参考資料
あとがき
特になし
この記事が気に入ったらサポートをしてみませんか?