Pythonでやってみた7: データ自動取得(Webスクレイピング) ①noteのダッシュボードデータ取得

1.概要
自分が欲しい情報を自動で取得する技術としてWebスクレイピングがあります。本記事ではnoteのダッシュボードから各記事のビュー回数、コメント、スキ回数を自動で取得します。
なお別記事ではAPI(非公式)を実施しておりますのでご参考までに
2.参考資料
3.完成品の説明
まとめとして完成品を説明します。ファイル内にはnote_selenium.ipynbとwebドライバを入れております。

3-1.完成コード
完成コード及び注意点は下記の通りです。
●ログインはTwitterアカウントから実施しています。
●安定性を考慮してdriver.implicitly_wait(10)と長めに設定しました。
[In]
import time
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.common.exceptions import NoSuchElementException
import pandas as pd
url = 'https://note.com/sitesettings/stats'
driver = webdriver.Chrome('chromedriver.exe') #chrome webdriverを起動、パスを指定
driver.implicitly_wait(10)
driver.get(url) #URLにアクセス
time.sleep(1)
driver.find_element_by_css_selector('#__layout > div > div:nth-child(1) > main > div > div.o-login__auth > div > button').click() #ログインボタンをクリック
driver.find_element_by_id('username_or_email').send_keys('Twitterのユーザー名') #ユーザー名
driver.find_element_by_id('password').send_keys('Twitterのパスワード') #ユーザー名
driver.find_element_by_id('allow').click()#ログインボタンをクリック
driver.find_element_by_css_selector('#__layout > div > div:nth-child(1) > div.t-siteSettings > div > main > div > div.t-settings__center > div > div > div > div.o-statsContent__nav > div.o-statsContent__navSort > ul > li:nth-child(4) > button').click() #全期間ボタンを押す
from selenium.common.exceptions import NoSuchElementException
while True:
try:
button_more = driver.find_element_by_css_selector('#__layout > div > div:nth-child(1) > div.t-siteSettings > div > main > div > div.t-settings__center > div > div > div > div:nth-child(6) > button') #もっと見るボタン
button_more.click()
except (NoSuchElementException) as e:
print('全ての「もっと見る」ボタンをクリックしました')
break
tabletag = driver.find_element_by_css_selector('#__layout > div > div:nth-child(1) > div.t-siteSettings > div > main > div > div.t-settings__center > div > div > div > div.o-statsContent__notesList') #テーブルタグの親要素を取得
df = pd.read_html(tabletag.get_attribute('innerHTML'))[0]
df.columns = ['記事', '全体ビュー', 'コメント', 'スキ']
df.to_excel('note_dashboard.xlsx', index=False) #Excelに保存
driver.quit()
3-2.完成品のアウトプット
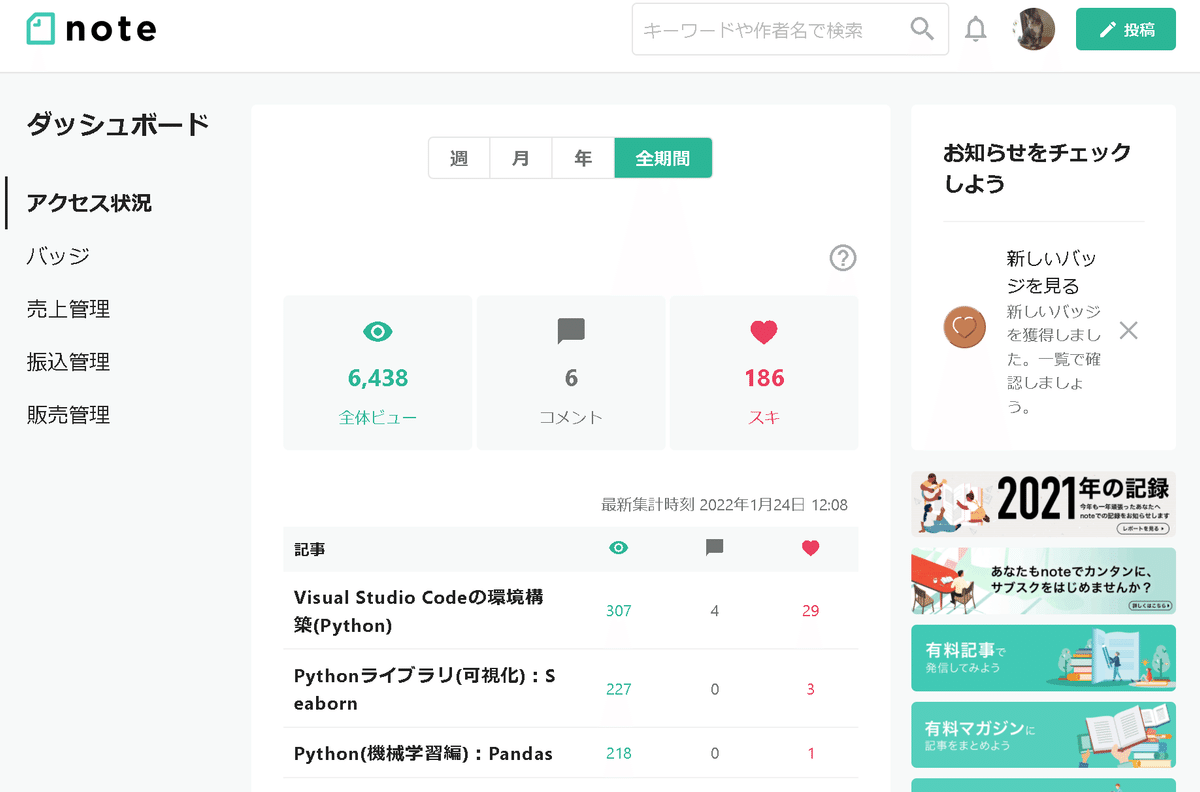
スクリプトを実行するとWebドライバが立ち上がり下記動作がすべて自動で処理されます。

上記完了後にフォルダ内に「note_dashboard.xlsx」ができ、下記のようなExcelファイルが作成されます。

4.動作説明
4-1.Webドライバの立ち上げ
まずはSeleniumでWebドライバを立ち上げます。
[In]
import time
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.common.exceptions import NoSuchElementException
import pandas as pd
url = 'https://note.com/sitesettings/stats'
driver = webdriver.Chrome('chromedriver.exe') #chrome webdriverを起動、パスを指定
driver.implicitly_wait(10)
driver.get(url) #URLにアクセス
time.sleep(1) #動作安定用4-2.noteにログイン
Twitterログインボタンからユーザー名とパスワードを入れてログインボタンを押します。
[In]
driver.find_element_by_css_selector('#__layout > div > div:nth-child(1) > main > div > div.o-login__auth > div > button').click() #ログインボタンをクリック
driver.find_element_by_id('username_or_email').send_keys('Twitterのユーザー名') #ユーザー名
driver.find_element_by_id('password').send_keys('Twitterのパスワード') #ユーザー名
driver.find_element_by_id('allow').click()#ログインボタンをクリック
4-3.全期間へ移動
ダッシュボード画面の「全期間」ボタンを押します。
[In]
driver.find_element_by_css_selector('#__layout > div > div:nth-child(1) > div.t-siteSettings > div > main > div > div.t-settings__center > div > div > div > div.o-statsContent__nav > div.o-statsContent__navSort > ul > li:nth-child(4) > button').click() #全期間ボタンを押す
4-4.「もっと見る」ボタンを押してデータを全表示★
現時点ではブラウザに十分な情報が表示されていないため「もっと見る」ボタンを押す必要があります。そこで「もっと見るボタンがなくなる」==「NoSuchElementExceptionエラーが発生したらループを抜ける」処理を追加して「もっと見る」ボタンがなくなるまで処理をかけました。
[In]
from selenium.common.exceptions import NoSuchElementException
while True:
try:
button_more = driver.find_element_by_css_selector('#__layout > div > div:nth-child(1) > div.t-siteSettings > div > main > div > div.t-settings__center > div > div > div > div:nth-child(6) > button') #もっと見るボタン
button_more.click()
except (NoSuchElementException) as e:
print('全ての「もっと見る」ボタンをクリックしました')
break要素がないことを確認してからループを抜けるため最後の処理ではdriver.implicitly_wait()の引数秒だけ要素を探すことになります。
4-5.データの抽出
ダッシュボードはTableタグで構成されているためTableタグを含む要素を取得して"pd.read_html()"に入れることでDataFrame型データを取得できます。
[In]
tabletag = driver.find_element_by_css_selector('#__layout > div > div:nth-child(1) > div.t-siteSettings > div > main > div > div.t-settings__center > div > div > div > div.o-statsContent__notesList') #テーブルタグの親要素を取得
df = pd.read_html(tabletag.get_attribute('innerHTML'))[0]【参考】4-5-1.Tableタグの取得
タグ要素はelem.get_attribute('innerHTML')で取得しました。参考までに中身をbs4で示します。
[In]
from bs4 import BeautifulSoup
soup = BeautifulSoup(tabletag.get_attribute('innerHTML'), 'html.parser')
soup.prettify()
【参考】4-5-2.pd.read_html()の動作
pd.read_html()はTableタグを含む要素を解析してDataFrame型に変換してくれます。参考までに上記では"tabletag.get_attribute('innerHTML')"を入れましたがTableタグを含むURLを入れるとWebサイトから情報抽出も可能です。

4-6.Excelファイルに出力/ドライバの立ち下げ
最後に取得したデータ(df型)をExcelに出力してドライバを立ち下げます。
[In]
df.columns = ['記事', '全体ビュー', 'コメント', 'スキ']
df.to_excel('note_dashboard.xlsx', index=False) #Excelに保存
driver.quit() あとがき
本当はここから下記のようなことをしてみたいけどWebスクレイピングをメインにした記事のため今回は避けました。
●記事で使用したハッシュタグワードや数も取得(どこにあるか知らんけど)
●記事の文字の形態素解析
●上記も含めて全データで機械学習をしてどのような記事が伸びるのか
この記事が気に入ったらサポートをしてみませんか?