
Pythonライブラリ(Webスクレイピング):Selenium

1.概要
WebスクレイピングライブラリのSeleniumを紹介します。WebスクレイピングはWebページから情報を抽出する技術のことです。
スクレイピングのライブラリは複数ありますが個人の意見としては下記の通りです。

2.Seleniumについて
2-1.Seleniumの基礎知識
Seleniumとはブラウザ操作を自動化するツールです。つまりブラウザ操作でやること(Webページ操作・情報取得)を自動化できます。最近のWebページはJavaScriptにより動的にページが作成されますがSeleniumはこれらにも対応可能です。
Seleniumを使うためには最低限のHTML構造の理解が必須+CSSセレクタの理解がある方が便利ですが、本記事はライブラリ説明用のため説明は割愛します。
2-2.WebブラウザでHTML確認:デベロッパーツール
HTMLからデータを抽出するためにWebページのHTMLを確認する必要があります。HTMLの確認は「デベロッパーツール」を使用して行いますが、ツールはブラウザ上で「F12」ボタンを押したら下記の通り確認できます。
Seleniumではデベロッパーツールは必ず使用することになります。
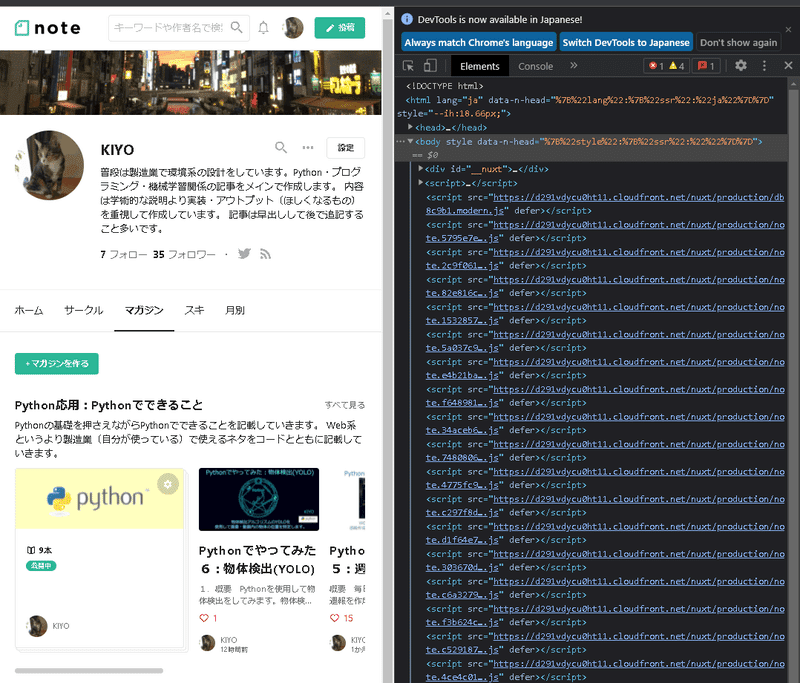
Progateの記事は比較的わかりやすかったです。
2-3.Webスクレイピング実施時の注意事項
高速でアクセスできるため連続処理をするとサーバーへ負荷がかかる(例:人気チケットやワクチン予約)ためスクレイピングを禁止しているサイトもあります。
また禁止されていなくても連続処理する場合はサーバーへの負荷を考慮して待機時間を設けるのが一般的です。
[In] ※for文の処理をループごとに1秒待機
import time
for i in range(5):
print(i)
time.sleep(1)
3.環境構築
Seleniumを使用するためには環境構築が必要となります。
3-1.ライブラリのインストール
外部ライブラリのseleniumをインストールします。また念のためにWebドライバとのVersionエラー防止のためにwebdriver_managerもインストールしておきます。
[ターミナル]
pip install selenium
pip install webdriver_manager3-2.Webドライバのインストール
Seleniumで操作するためのWebドライバをインストールします。今回はChromeを使用しますがドライバと使用ブラウザのVersionを合わせる必要があるため「設定(右上の・・・)」->「Chromeについて」からバージョンを確認します。
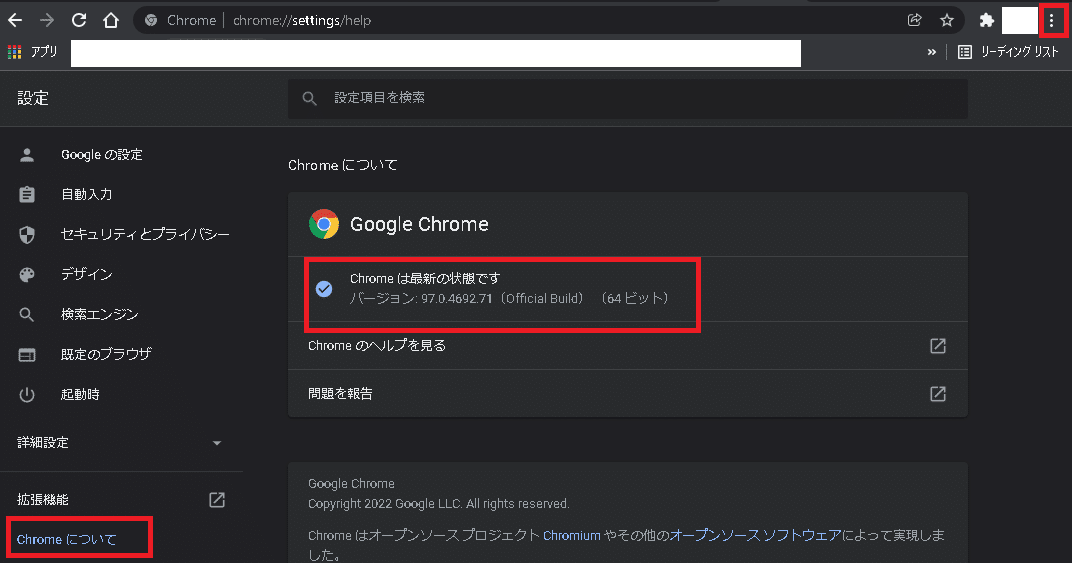
続いて下記サイトから同じVersionのドライバをDLしてフォルダ内にが"chromedriver.exe"があることを確認します。

3-3.Webドライバを所定の場所に配置
"chromedriver.exe"をパスが通ったフォルダに保存します。作業ディレクトリは自動でパスが通るため、私は下記のようにPythonスクリプトと同じフォルダに入れました。

4.Selenium基礎1:コマンド・ブラウザ操作
Seleniumの基礎的な操作を紹介します。
4-1.ブラウザの起動・URL移動・立ち下げ
下記コードはブラウザ起動->URL移動->スクショ->1秒待機->ブラウザ立ち下げとなります。動作は出力でご確認ください。
[In]
import time
from selenium import webdriver
url = 'https://note.com/kiyo_ai_note/magazines'
driver = webdriver.Chrome('chromedriver.exe') #chrome webdriverを起動、パスを指定
driver.get(url) #URLにアクセス
driver.save_screenshot('kiyo_ai_note.png') #スクリーンショットを保存
time.sleep(1) #1秒待機
driver.quit() #driverを終了する
【"chromedriver.exe"を用意しない方法:webdriver_manager】
上は"chromedriver.exe"を用意してwebdriver.Chrome('chromedriver.exe')のようにwebドライバのパスを指定しましたがVersion違いによるエラーが発生する可能性もあります。
実行速度は遅くなりますがwebdriver_managerを使用すると処理ごとに適切なドライバをインストールしてブラウザを起動するため便利です。
[In]
from webdriver_manager.chrome import ChromeDriverManager
from selenium import webdriver
url = 'https://note.com/kiyo_ai_note/magazines'
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get(url) #URLにアクセス
driver.save_screenshot('kiyo_ai_note.png') #スクリーンショットを保存
time.sleep(1) #1秒待機
driver.quit() #driverを終了する4-2.ページ情報取得:current_url, title, page_source
下記以降の説明ではドライバは立ち上がった状態とします。
下記コードでドライバが開いているページのURL、タイトルを取得します。
[In]
driver.current_url #現在のURLを取得
driver.title #現在のタイトルを取得[Out]
'https://note.com/kiyo_ai_note/magazines'
'KIYOのマガジン一覧|note'また"driver.page_source"でページのHTML情報が取得できます。
[In]
driver.page_source
[Out]
'<html lang="ja" data-n-head="%7B%22lang%22:%7B%22ssr%22:%22ja%22%7D%7D" style="--ih:17.23px;"><head>\n <title>KIYOのマガジン一覧|note</title><meta data-n-head="ssr" charset="utf-8"><meta data-n-head="ssr" name="viewport" content="width=device-width, initial-scale=1.0"><meta data-n-head="ssr" http-equiv="X-UA-Compatible" content="IE=10"><meta data-n-head="ssr" data-hid="description" name="description" content="KIYOさんの編集するマガジンです。"><meta data-n-head="ssr" data-hid="og:site_name" property="og:site_name" content="note(ノート)"><meta data-n-head="ssr" data-hid="og:url" property="og:url" content="https://note.com/kiyo_ai_note/magazines"><meta data-n-head="ssr" data-hid="og:title" property="og:title" content="KIYOのマガジン一覧|note"><meta data-n-head="ssr" data-hid="og:description" property="og:description" content="KIYOさんの編集するマガジンです。"><meta data-n-head="ssr" data-hid="og:image" property="og:image" content="https://assets.st-4-3.コマンド操作
ボタンクリック、戻る/進む、更新は下記の通りです(1行目のログインボタンの要素取得は追って説明)。
[In]
loginbottun = driver.find_element_by_css_selector('#__layout > div > div:nth-child(1) > header > span > div > nav > div.o-navbarPrimaryGuest__navItem.login.svelte-13wwcyh > a')
loginbottun.click() #要素をクリックする
driver.back() #ひとつ前のページに戻る
driver.forward() #ひとつ先のページに進む
driver.refresh() #ページを更新する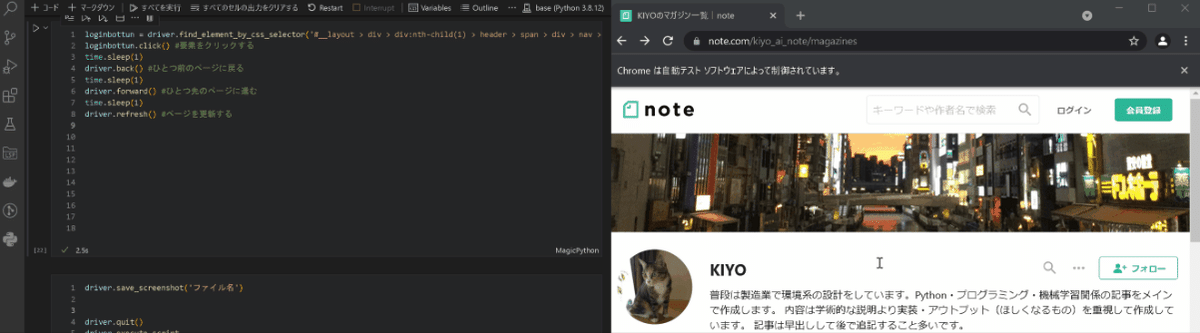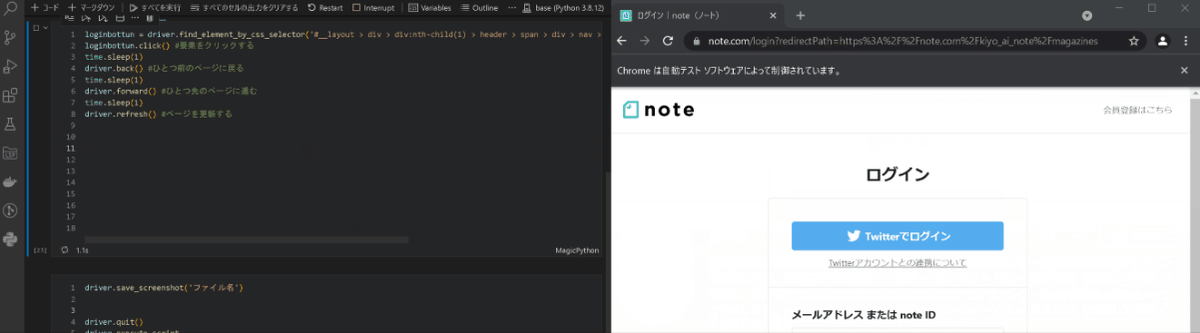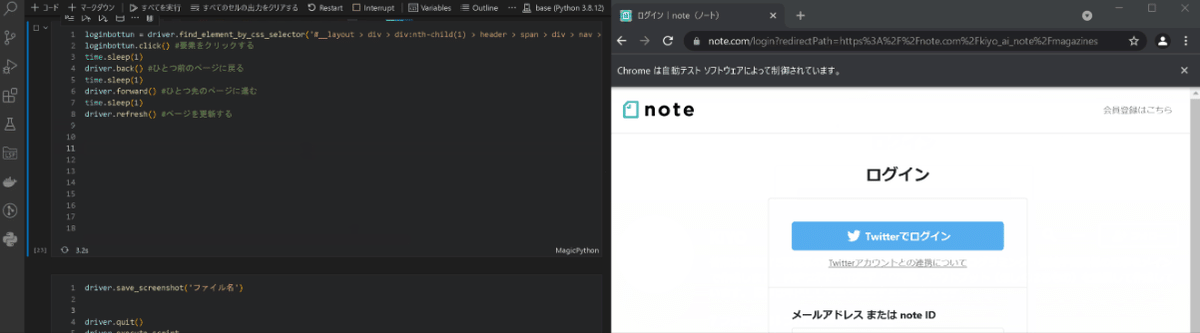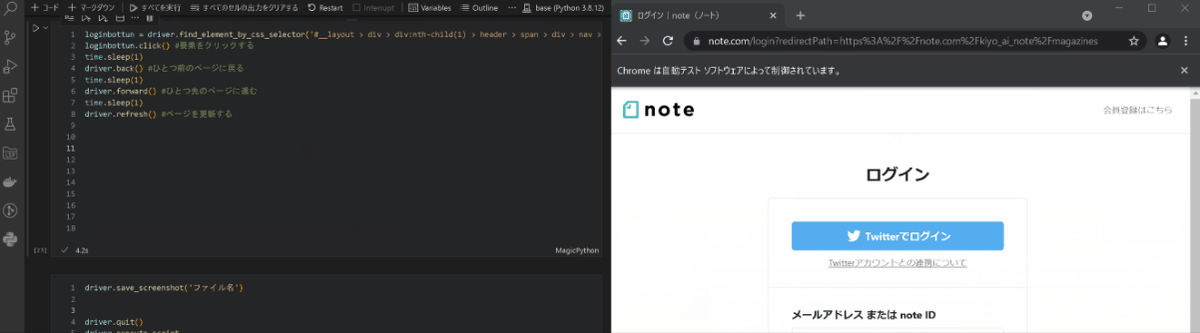
4-4.テキストの記載・削除:send_keys, clear()
要素に記載したい文字を送付したり空にしたりできます。
[In]
#文字列を送付
driver.find_element_by_id('email').send_keys('seleniumで記載email')
driver.find_element_by_id('password').send_keys('seleniumで記載password')
#文字列を削除
driver.find_element_by_id('email').clear()
driver.find_element_by_id('password').clear()
4-5.スクリーンショット:save_screenshot
現在開いているページのスクリーンショットを取得します。
[In]
driver.save_screenshot('保存用filepath.png')5.Selenium基礎2:要素の取得
Seleniumを使用してページ内の要素を取得します。
5-1.要素の確認:デベロッパーツール
id名やクラス名などを知るためにはHTMLの中身を確認する必要があります。そのために使用するのが2-2.で紹介したデベロッパーツールです。
使用方法はカーソル部分を選択して取得したい要素の上に近づけると要素構造がわかります。

通常はHTML構造を見ながら要素を分解して自分が欲しい情報を抽出しますが、これが死ぬほど手間です。所定部分(今回はログインボタン)の要素だけ欲しいのであれば「要素を右クリック」->「Copy」->「Copy selector」or 「Copy XPath」として、取得した値をfind_elementに入れれば簡単に要素を取得できます(実例は4-3.)。

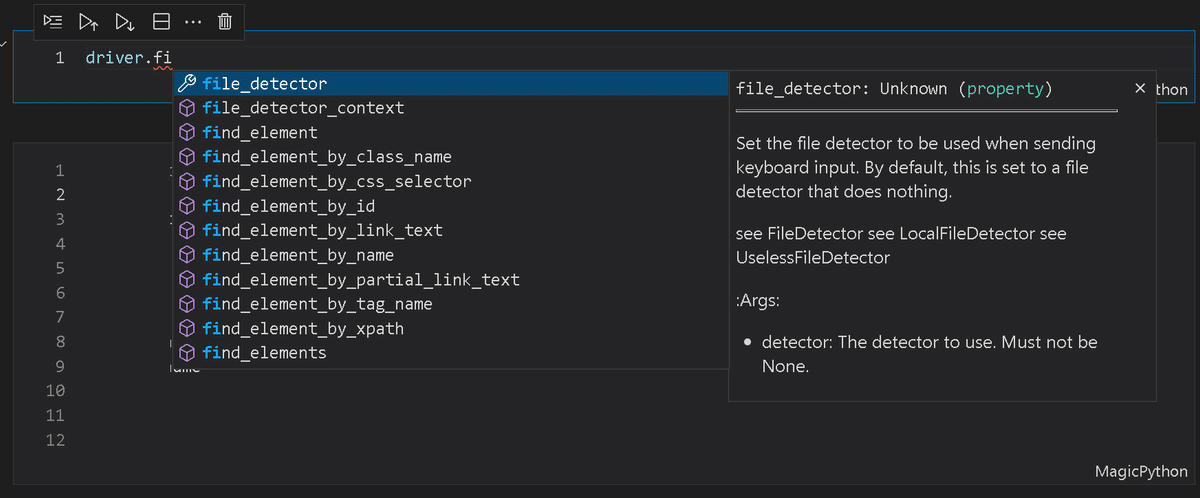
5-2.要素の取得:find_element_by_method
要素一覧は下記の通りです。メソッドはIDEの自動補完機能を使用すれば忘れれても何とかなります。

5-3.要素情報:text, tag_name, get_attribute('属性')
抽出した要素の情報はelem.textなどで取得できます。
[In]
tags_p = driver.find_elements_by_tag_name('p')
for tag_p in tags_p:
print('タグ名:', tag_p.tag_name, '要素の属性の値', tag_p.get_attribute('class'))
print(tag_p.text) #テキスト情報[Out] ※出力の一部を抜粋
タグ名: p 要素の属性の値 o-contentMagazine__description
Pythonライブラリの使用方法のご紹介。教科書より参考書よりの内容です。
タグ名: p 要素の属性の値 o-magazineItemWithNotes__avatarName
KIYO
タグ名: p 要素の属性の値 m-noteBody__description m-noteBody__description--TextNote
1.概要 WebスクレイピングライブラリのBeautiful Soup4を紹介します。WebスクレイピングはWebページから情報を抽出する技術のことです。 スクレイピングのライブラリは複数ありますが個人の意見としては下記の通りです。 2.Beautiful Soup4について2-1.Beautiful Soup4の基礎知識 Beautiful Soup4は公式に記載の通りHTMLを解析して簡単に情報を抽出できるライブラリです。 [ターミナル]pip install
タグ名: p 要素の属性の値 m-noteBody__description m-noteBody__description--TextNote
1.概要 StreamlitはWebアプリを簡単に作成できるライブラリです。Webアプリ用ライブラリは他にもありそれぞれ特徴がありますが個人的にはStreamlitが最強でした。 参考用のアウトプットはstreamlit cloudに挙げています。 2.Webアプリ使用の目的 Streamlitの使用目的に関して、私の場合は下記のとおりです。 3.参考資料 Streamlitの参考資料は公式ドキュメントが絶対ベストです。初心者の時はチートシートを見ながらやれば何とかいき
タグ名: p 要素の属性の値 m-noteBody__description m-noteBody__description--TextNote
1.概要 RequestsはHTTPクライアント用ライブラリです。ざっくりしたイメージではWebブラウザにURLを入れてEnterを押した時のような処理をしてくれます(※ブラウザの働きで言うと図は違うのでイメージ専用図です)。 このライブラリを使用することで下記が可能となります。 2.前提知識:HTTPメソッド HTTPクライアントを処理する時に使用するメソッドは計8つあります。ただし上記用途であれば|覚えるのは2つだけで十分です。 下記は参考記事です(CRUDはデ
タグ名: p 要素の属性の値 m-noteBody__description m-noteBody__description--TextNote5-4.タグ要素(HTML):get_attribute('innerHTML')
elem.textだけだとHTMLのタグが外れるためBeautiful Soup4での解析ができなくなります。
タグ付きで情報取得したい場合はget_attribute('innerHTML')を使用します。
[In]※取得要素は適当
container = driver.find_element_by_class_name('o-contentMagazine__container')
container.get_attribute('innerHTML')[Out]
'<section class="o-contentMagazine__section" data-v-4116c80d=""><div class="m-horizontalScrollingList__section" data-v-1a3a27f4="" data-v-4116c80d=""><div class="m-horizontalScrollingList__header" data-v-1a3a27f4=""><div class="m-horizontalScrollingList__title" data-v-1a3a27f4=""><h2 class="o-contentMagazine__title" data-v-1a3a27f4="" data-v-4116c80d="">\n Pythonライブラリ\n <!----></h2></div> <div class="m-horizontalScrollingList__description" data-v-1a3a27f4=""><p class="o-contentMagazine__description" data-v-1a3a27f4="" data-v-4116c80d="">\n Pythonライブラリの使用方法のご紹介。教科書より参考書よりの内容です。\n </p>6.Selenium応用
6-1.例外(エラー)認識:NoSuchElementException
要素が取得できなくなるまで連続して処理したい場合、try文でエラーを認識するまで処理させます。エラーを認識させるためには専用の例外クラスを呼び出す必要があります。
[In]※サンプルコード:Webアプリ上のボタンが出現しなくなるまで押す
from selenium.common.exceptions import NoSuchElementException
while True:
try:
button_more = driver.find_element_by_css_selector('#__layout > div > div:nth-child(1) > div.t-siteSettings > div > main > div > div.t-settings__center > div > div > div > div:nth-child(6) > button') #もっと見るボタン
button_more.click()
except (NoSuchElementException) as e:
print('テスト')
break7.Seleniumのその他機能
7-1.待機機能:implicitly_wait
Seleniumを実行するとテスト時には取得できた要素が取得できないことがあり原因は要素が出現する前にコードが処理されるためです。
結論として要素が現れるまで待機する必要があり、機能的に待機をしてくれるようにするため"driver.implicitly_wait(待機時間)"を追加します。
[In]
driver = webdriver.Chrome('chromedriver.exe')
driver.implicitly_wait(10)なおエラーは出ないけど要素が十分にとれていない場合は、JavaScript処理<<コード処理の可能性があるため"time.sleep()"を追加してあげます。
7-2.オプション設定
Seleniumの実行時に追加したい機能をオプションで設定します。
[Sample code]
#オプション設定
options = webdriver.ChromeOptions() #オプションを作成
options.add_argument('オプション指定1') #オプション1を追加
options.add_argument('オプション指定2') #オプション2を追加
options.add_argument('オプション指定3') #オプション3を追加
driver = webdriver.Chrome('chromedriver.exe', options=options) #オプションを引数に追加オプションには下記があります。
●options.add_argument('--headless')
ヘッドレスモードはブラウザを立ち上げずに裏側で処理してくれます。
●options.add_argument('--hide-scrollbars'):
スクロールバーを隠します(スクショを綺麗にとれる)。
ヘッドレスモードを使用したサンプルは下記の通りです。
[In]※4-1節と同じ処理をヘッドレスモードで実行
import time
from selenium import webdriver
url = 'https://note.com/kiyo_ai_note/magazines'
#オプション設定
options = webdriver.ChromeOptions() #オプションを作成
options.add_argument('--headless') #headlessモードを有効にする
driver = webdriver.Chrome('chromedriver.exe', options=options) #chrome webdriverを起動、パスを指定
driver.get(url) #URLにアクセス
driver.save_screenshot('kiyo_ai_note.png') #スクリーンショットを保存
time.sleep(1) #1秒待機
driver.quit() #driverを終了する
print('処理を完了しました。')
7-3.JavaScriptの利用:execute_script
Seleniumだけで解決できない問題はdriver.execute_script('JavaScriptのコード')によりJavaScriptを使用することで対応できます。
参考コードは下記の通りです。
driver.execute_script('return document.body.scrollWidth') #ページ幅を取得
driver.execute_script('return document.body.scrollHeight') #ページ高さを取得8.Seleniumの実演
実演は下記記事参照のこと
9.エラー事例
Seleniumでよく生じたエラー事例は下記の通りです。
●要素が取れなくなった:Webページの構造や属性名は比較的変わるためいつの間にかエラーがでます。対応として要素を取り直す必要があります。
●ドライバが起動できない:ブラウザが自動で更新されていつの間にかWebドライバとブラウザのVersionがずれてエラーが発生します。対応としてどちらかにVersionを合わせなおす必要があります。
●要素が見つからない:ドライバの動きが遅く次の処理が間に合っていないことがあります。対応としてtime.sleep()を挟んで待機時間を設けます。
●体裁が異なる:ブラウザがIEしか対応していないページをchromeのwebドライバで処理しようとしたためエラーが発生しました。
●要素が取れない:いまだに未解決の問題で意味が分からん。
10.テンプレコード:自分用
selenium使用時のテンプレは下記の通りです(自分用)。
[template]
import time
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.common.exceptions import NoSuchElementException
import pandas as pd
#オプション設定 ※使用する場合はコメントアウトを外して,driverにoptionsを設定
# options = webdriver.ChromeOptions() #オプションを作成
# options.add_argument('--headless') #headlessモードを有効にする
# options.add_argument('--hide-scrollbars') #スクロールバーを非表示にする
#url設定
url = ''
#seleniumを起動
# driver = webdriver.Chrome(ChromeDriverManager().install()) #webdriver managerでchromedriverをインストールして起動
driver = webdriver.Chrome('chromedriver.exe') #chrome webdriverを起動、パスを指定
driver.implicitly_wait(10)
driver.quit() #driverを終了する参考記事
Seleniumラッパー(Seleniumの機能+αで使いやすくしたやつ)のPythonライブラリでheliumがあります。下記がまとまっており私が書く必要がないくらいなので参考までに
あとがき
もう少し書きたいことあるけど力尽きたので後で追記していこう・・・・その前にほったらかしてたWeb領収書の自動化をこれでできるか試してみます。
この記事が気に入ったらサポートをしてみませんか?