
Pythonライブラリ(Word):python-docx

概要
MicrosoftのWordを扱うライブラリを紹介します。
1.インストール/デモ
ライブラリのインストールは"python-docx"で実施します。
pip install python-docx公式ドキュメントをほぼそのまま使用して作成しました。
[In]
from docx import Document
from docx.shared import Inches
document = Document() #新規ドキュメント作成
document.add_heading('Document Title', 0) #文書タイトル
p = document.add_paragraph('A plain paragraph having some ') #段落追加
p.add_run('bold').bold = True
p.add_run(' and some ')
p.add_run('italic.').italic = True
document.add_heading('Heading, level 1', level=1) #見出し追加
document.add_paragraph('Intense quote', style='Intense Quote') #強調引用記号
document.add_paragraph(
'first item in unordered list', style='List Bullet'
)
document.add_paragraph(
'first item in ordered list', style='List Number'
)
document.add_picture('konan.JPG', width=Inches(1.25))
records = (
(3, '101', 'Spam'),
(7, '422', 'Eggs'),
(4, '631', 'Spam, spam, eggs, and spam')
)
table = document.add_table(rows=1, cols=3)
hdr_cells = table.rows[0].cells
hdr_cells[0].text = 'Qty'
hdr_cells[1].text = 'Id'
hdr_cells[2].text = 'Desc'
for qty, id, desc in records:
row_cells = table.add_row().cells
row_cells[0].text = str(qty)
row_cells[1].text = id
row_cells[2].text = desc
document.add_page_break()
document.save('demo.docx') #ファイルを保存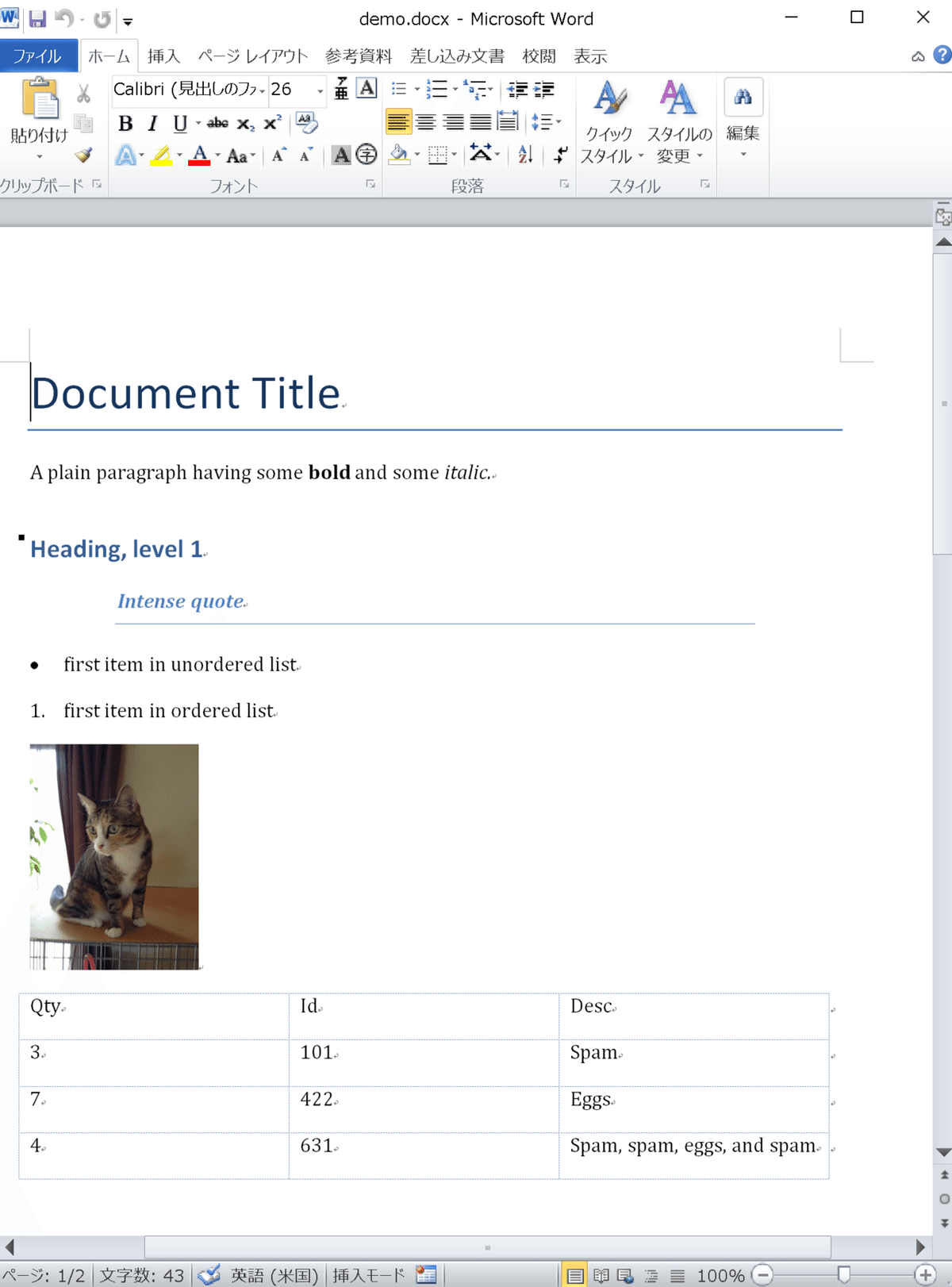
2.新規ファイル作成:docx.Document()
ファイル作成はdocx.Document()で作成したインスタンスに見出しや段落を足していきます。今回は文字列を改行ごとにリスト化して各段の値を段落に追加しました。
[In]
text_title = '自民税調会長「賃上げ税制、控除率拡大」、基本給引き上げ条件。'
text = '''
2021/11/18 日本経済新聞 朝刊 1ページ 390文字
自民党税制調査会の宮沢洋一会長は17日の日本経済新聞のインタビューで、賃上げした企業への優遇税制について税額控除率を現在の15%から拡大する方針を示した。要件は「基本給が軸となる」と述べ、基本給を引き上げた企業を対象にすると強調した。(関連記事5面に)
2022年度の税制改正で対応する。年末の与党税制改正大綱に盛り込む。基本給を優遇の基準にして賃金上昇の傾向を定着させる狙いがある。
現在は大企業で新規採用者への給与支払い分の15%を法人税から税額控除する仕組みなどがある。基本給を変えなくてもボーナスなど一時金を増やせば優遇措置が適用される。
宮沢氏は「基本給が1年に1%ずつでもずっと上がる状況にしたい」と話した。控除率について「効果があるものは引き上げていく」としたうえで引き上げ幅への言及は避けた。「1人あたりの賃金がどう上がっていくかが一番のポイントだ」と指摘した。
'''
import docx
doc = docx.Document() #新規ドキュメント作成
texts = text.split('\n') #改行で分割->リスト
doc.add_heading(text_title, level=0) #タイトルを追加
for text in texts:
doc.add_paragraph(text) #段落(パラグラフ)追加
doc.save('output/211118_article_nikkei.docx') 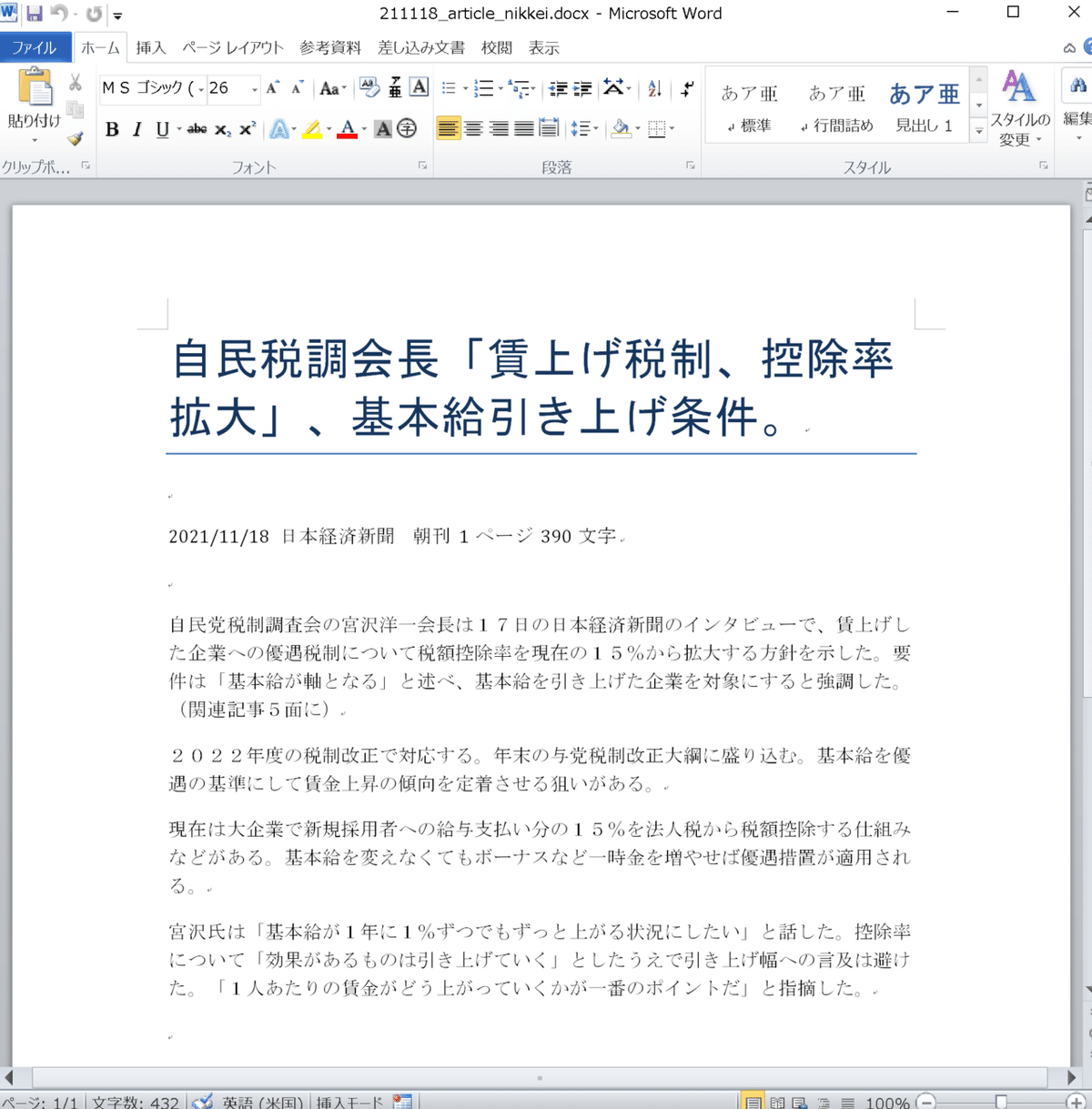
改ページやテーブルの追加なども可能です。
3.ファイルの読み込み:docx.Document(path)
ファイルの読み込みは下記の通りです。
[In]
import docx
filepath = 'output/211118_article_nikkei.docx'
doc = docx.Document(filepath) #ドキュメントを読み込み
for paragraph in doc.paragraphs: #段落ごとにテキストを抽出
print(paragraph.text)[Out]
自民税調会長「賃上げ税制、控除率拡大」、基本給引き上げ条件。
2021/11/18 日本経済新聞 朝刊 1ページ 390文字
自民党税制調査会の宮沢洋一会長は17日の日本経済新聞のインタビューで、賃上げした企業への優遇税制について税額控除率を現在の15%から拡大する方針を示した。要件は「基本給が軸となる」と述べ、基本給を引き上げた企業を対象にすると強調した。(関連記事5面に)
2022年度の税制改正で対応する。年末の与党税制改正大綱に盛り込む。基本給を優遇の基準にして賃金上昇の傾向を定着させる狙いがある。
現在は大企業で新規採用者への給与支払い分の15%を法人税から税額控除する仕組みなどがある。基本給を変えなくてもボーナスなど一時金を増やせば優遇措置が適用される。
宮沢氏は「基本給が1年に1%ずつでもずっと上がる状況にしたい」と話した。控除率について「効果があるものは引き上げていく」としたうえで引き上げ幅への言及は避けた。「1人あたりの賃金がどう上がっていくかが一番のポイントだ」と指摘した。個別の段落を読み込むのであればリストのように扱えます。
[In]
print(doc.paragraphs[0].text)
print(doc.paragraphs[1].text)
print(doc.paragraphs[2].text)
[Out]
自民税調会長「賃上げ税制、控除率拡大」、基本給引き上げ条件。
2021/11/18 日本経済新聞 朝刊 1ページ 390文字 4.書式設定:doc.paragraphs[0].runs[0]
各段落での書式設定は"doc.paragraphs[0].runs[0]"を使用します。
[In]
filepath = 'output/211118_article_nikkei.docx'
doc = docx.Document(filepath) #ドキュメントを読み込み
for idx, paragraph in enumerate(doc.paragraphs): #段落ごとにテキストを抽出
if len(paragraph.text) > 0:
if idx <= 2: #段落3つまで
paragraph.runs[0].font.size = docx.shared.Pt(20) #フォントサイズを変更
paragraph.runs[0].font.name = 'Meiryo' #フォント名を変更
paragraph.runs[0].font.bold = True #太字にする
paragraph.runs[0].font.italic = True #斜体にする
paragraph.runs[0].font.underline = True #斜体にする
paragraph.runs[0].font.color.rgb = docx.shared.RGBColor(255, 0, 0) #文字色を変更
doc.save('output/211118_article_nikkei_mod.docx')
5.ファイルの文字列置換
ファイル内の文字列置換は各段落のテキストを抽出して、指定文字列がある場合に置換処理をします。
※findの動作は下記「3.文字列メソッド3:検索(index, find)・確認」参照
[In]
import docx
import re
filepath = 'output/211118_article_nikkei.docx'
doc = docx.Document(filepath) #ドキュメントを読み込み
subwords = {
'2021/11/18':'2345/6/7',
'朝刊':'夕刊',
'インタビュー':'面会'
}
for paragraph in doc.paragraphs: #段落ごとにテキストを抽出
for key, value in subwords.items(): #置換対象のキーと値を取得
if key in paragraph.text: #キーがテキストに含まれているか
paragraph.text = paragraph.text.replace(key, value) #テキスト内の文字を置換
doc.save('output/211118_article_nikkei_sub.docx') #テキストを置換したファイルを新規で保存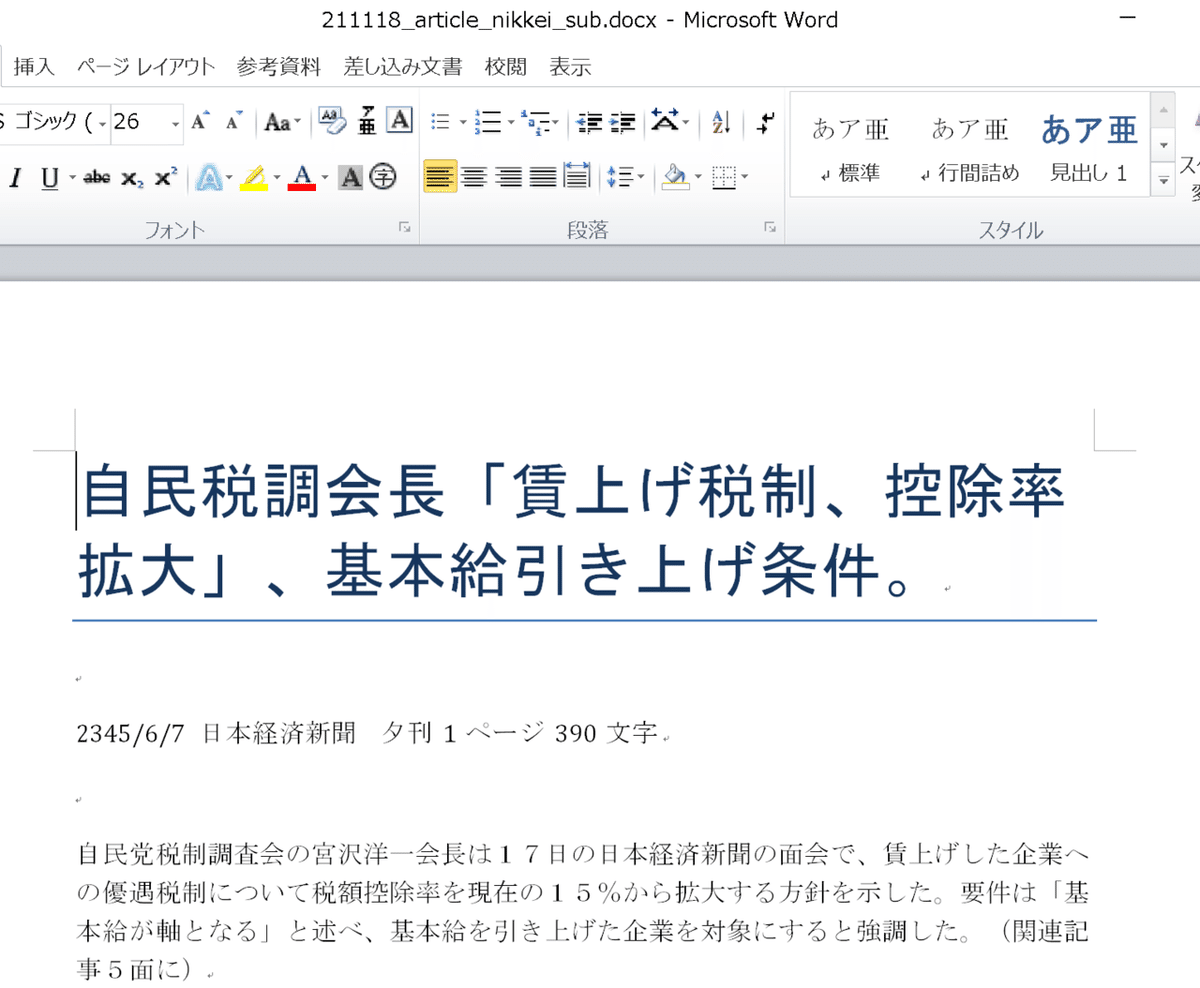
参考資料
あとがき
とりあえず書き出しましたが追加があれば追記します。
この記事が気に入ったらサポートをしてみませんか?