
【データの集め方講座】Webデータの収集方法-PythonとSeleniumで最短環境構築-

はじめに
ごあいさつ
ご高覧いただきありがとうございます.
ソフトウェアエンジニアのKitaharaです.
本日はPythonとSeleniumを使ったWebデータの収集方法を解説します!
この記事でやること
PythonとSelenium(version 4以降)でWebデータを収集するための環境を構築し, 動作のテストをします
この記事を読むことでWeb上にあるデータを収集することができるようになります. コードもすべて記載してありますので, 是非ご活用ください.
この記事ではやらないこと
Webデータを使ってアプリケーションを作ること
Webデータをデータ分析すること
いずれも今後記事にしていく予定です!
公開までお待ちください!
使うものの説明
Python(3.7.12)
プログラミング言語のひとつです.
型宣言等が無く, 初心者にも扱いやすい言語だと言われています
近年Deep Learningのライブラリが豊富であることから注目を集めている人気の言語です
Selenium
Webブラウザの操作を自動で行うためのフレームワークです
もともとはWebアプリケーションのテスト等で使うことを目的に開発されましたが, 現在ではWebスクレイピング(Webサイトからデータを取得すること)を目的に利用されることも多いです
Google Coraboratory
Googleが提供するPythonの実行環境
主要なライブラリがインストールされている状態で使うことができる
Chromeでアクセスするだけで利用することができる
環境構築が不要
無料で使うことができる
環境構築
Google Colabにアクセスしてください.
左上の[ファイル]から[ノートブックを新規作成]を押すと, 新しいipnb(IPython notebook)を作成することができます.
新しいipnbを作成することができましたら早速環境構築に入っていきます
Seleniumをインストールする
まずは, seleniumをインストールしましょう
!pip install selenium # seleniumをインストールする
# !pip freeze # seleniumが入っているか確認することができますchromedriverを使えるようにする
次に, linuxコマンドを使ってchromedriver(データを取得するときに使用する)の準備をしていきます. なお, linuxコマンドは逐一解説しておりますのでそちらを参考にしてください
# apt-get updateはインストール可能なパッケージの一覧を更新します
!apt-get update
# chromedriverを後ほど利用するのでインストールします
!apt install chromium-chromedriver
# cpコマンドはファイルやディレクトリのコピーに使うコマンドです
# コピーする「ファイルのパス(original_file_path)」と「コピーする場所(target_file_path)」を記述することで簡単にコピーをすることができます
!cp /usr/lib/chromium-browser/chromedriver /usr/bin
# 最後にPythonのバージョンを確認しましょう
!python --version # Python 3.7.12以上で環境構築は終了です!
お疲れさまでした!
動作テスト
早速動作のテストをしてみましょう.
今回は以下のサイトから料理記事タイトルとURLの取得を試みます.
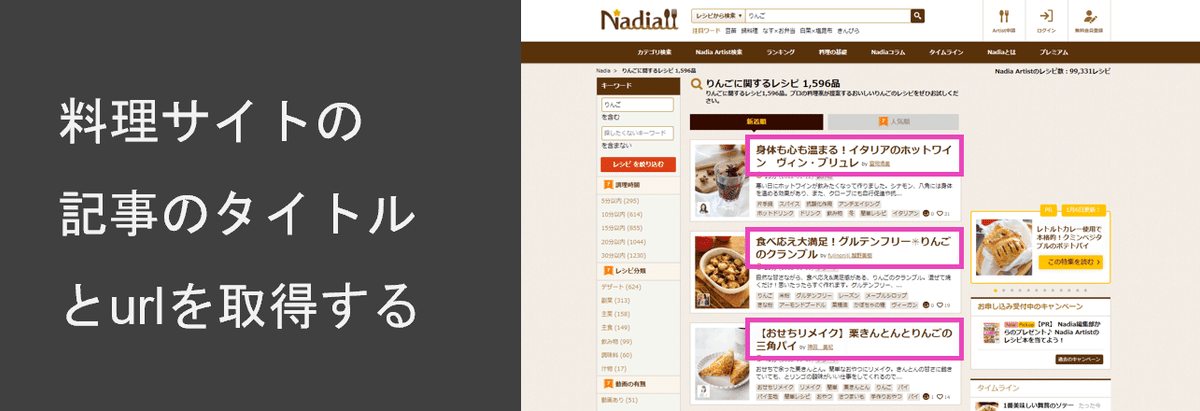
今回はCSS セレクターというものを使って取得をします.
WebサイトはHTMLとCSSという言語で書かれています.
CSSセレクターを使うとそのHTMLのブロックとCSSのクラスを記述し, ほしい要素を指定することができます.
欲しい要素のHTMLとCSSは欲しい要素の上でマウスを右クリックすることで出現する[検証]を押すことによりみることができます
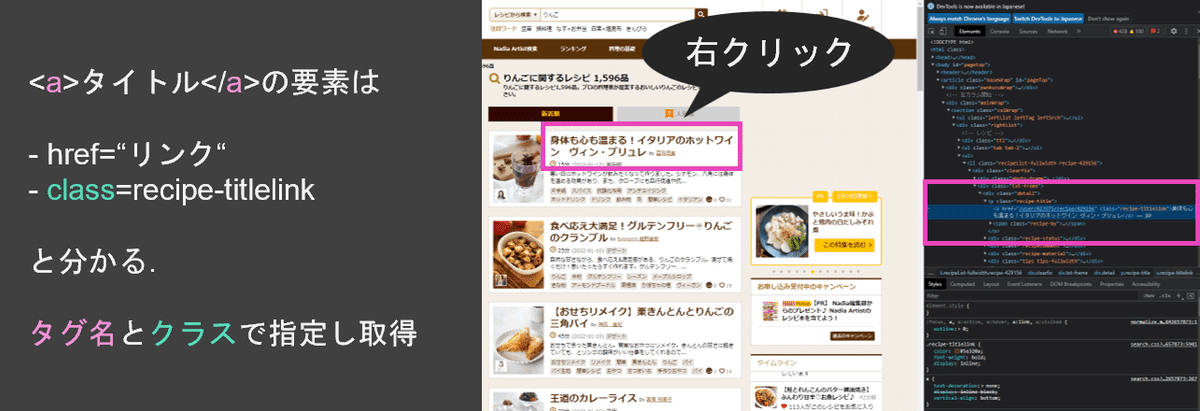
今回はCSSセレクターは"a.recipe-titlelink"と記述します.
意味はrecipe-titlelinkクラスのaタグです.
以下が今回使用するコードになります
from selenium import webdriver
from selenium.webdriver.common.by import By
options = webdriver.ChromeOptions()
options.add_argument('--headless') # headlessモードを使用する
options.add_argument('--no-sandbox') # sandboxモードを解除する(クラッシュの回避)
options.add_argument('--disable-dev-shm-usage') # /dev/shmパーティションの使用を禁止にする(クラッシュの回避)
options.add_argument('--disable-extensions') # 拡張機能を無効にする
query = 'りんご'
driver = webdriver.Chrome('chromedriver', options=options) # Driverを起動
driver.get('https://oceans-nadia.com/search?type=&q='+query) # データを取得
# CSS セレクターを用いてクラスがrecipe-titlelinkのaタグを取得
# seleniumのversionが3以下だとfind_elements_by_css_selector(selector)なので注意
selector = 'a.recipe-titlelink'
elms = driver.find_elements(by=By.CSS_SELECTOR, value=selector)
# データを格納するリストを作成
recipe_titles = []
recipe_urls = []
for elm in elms:
# 記事のタイトルの取得
title = elm.text
# 記事のurlを取得
url = elm.get_attribute('href')
# URLとセットで取得したいのでURLが無い(調べたところ''でした)ものはリストに追加しない
if url == '':
continue
recipe_titles.append(title)
recipe_urls.append(url)これでうまくいっていれば「りんご」の料理記事のタイトル・URLのリストが出来上がっているはずです. 確認してみましょう
# 取得したデータの確認
print(recipe_titles[0])
print(recipe_urls[0])
# RETRURN
# ['身体も心も温まる!イタリアのホットワイン\u3000ヴィン・ブリュレ']
# ['https://oceans-nadia.com/user/423375/recipe/429156']無事取得することができました!
おわりに
今回はPythonとSeleniumを使って環境構築をする方法を解説しました!
参考になったという方はぜひハートボタンを押していってください!
参考文献
実装済みのGoogle Colabへのリンク
記事内で不明な点等ございましたら気軽にご連絡ください.
Twitter: @kitahara_dev
email: kitahara.main1@gmail.com