【実習編】生物の分布予測マップの作成 MaxEntの利用とQGISによる分析データの準備、可視化

I. はじめに
地理空間情報が利用可能な分析ツールは、GISのみならず各学問分野で提供されています。たとえばマルチエージェントシミュレーションツールであるNetLogoはShapeファイルを読み込むことができます。計量経済学で利用されてきた汎用統計ソフトのStataも、Shapeファイルを用いて空間計量分析を行うことができます。しかし、このようなツールは、地理空間情報の加工機能が備わっていなかったり乏しかったりすることが多く、分析に用いるデータを用意するために別途GISの力を借りることが少なくありません。
ここで扱うMaxEntもその1つです。MaxEntは、生物種の空間的な分布モデルを推定するソフトウェアです。分析には既知の分布データや地形や植生などの地理空間情報が必要になります。しかし、調査によって得られたデータやウェブサイトから集めたデータが、そのままMaxEntに使えるデータになっているとは限りません。
そこで、今回はQGISを用いてデータフォーマットを変換したり、対象範囲を切り出したりして分析に用いるデータを用意する手順を紹介します。また、MaxEntで分析した結果を、QGISで読み込んで可視化します。
II. 問題設定とデータの選定
1. MaxEntとは
まず、今回使用するMaxEntについて簡単に紹介します。MaxEntは、ある生物の既知の分布情報(在データと呼ばれます)と地形や植生などの環境情報から、その生物の生息適地を推定する手法、およびそれを実装したソフトウェアのことを指します。ここで使われる手法は最大エントロピーモデル(Maximum Entropy model)と呼ばれる一般的なアルゴリズムであり、MaxEntはこの頭文字に由来します。
ソフトウェアとしてのMaxEntは、Phillipsらによって作成されたオープンソースのフリーソフトウェアで、在データのみから生息分布を推定することを目的としたモデルが実装されています(※1)。在データのサンプルサイズが小さくても実行でき、他の分析手法(例えば自己回帰モデルや一般化線形モデルなど)と比較しても精度よく分布を予測できることから、多くの研究で利用されています。
※1 Rのパッケージも公開されていますが、こちらのパッケージ名は「maxnet」となっています。
MaxEntで分析するために必要なデータは2種類あります。1つは在データで、既知の分布を座標値で示したCSVファイルになります。もう1つは環境情報で、こちらはEsri ASCII(拡張子は.asc)と呼ばれるラスター形式で用意します。このとき、データについて次の3つの条件が守られていなければなりません。
1. CSVと各ラスターの座標系が一致していること
2. 各ラスターのセルサイズが一致していること
3. 各ラスターの範囲が一致していること
これら条件に従ってデータの前処理を行うために、QGISが必要になります。
--- --- --- --- --- --- --- ---
2. 問題設定
この記事では、天下り的ですが、四国においてソウシチョウという特定外来種の鳥の生息域を推定します。ソウシチョウは東南アジア原産の小型の鳥です。愛玩鳥として江戸時代のころから輸入されていましたが、野外への定着が進み生息域が拡大しています。
NPO法人四国自然史科学研究センターのウェブサイトでは、ソウシチョウの分布状況調査の結果が公開さています。公開形式は画像ですが、画像をジオリファレンスしてポイントデータ化すれば、座標値を得られそうです。
http://www.lutra.jp/sousityoujyouhoubosyuu.htm
--- --- --- --- --- --- --- ---
3. 使用する環境データの選定
ソウシチョウの分布を推定するために、ソウシチョウの生態と関連しそうな環境情報を検討します。環境省のリーフレット(PDF)によれば、ソウシチョウはササ類の繁茂する広葉樹林を好み、標高1000m付近に生息するそうです。したがって、標高や植生のデータは推測に有用だと考えられます。このように、先行研究などを参考にソウシチョウの分布と関連しそうな事柄を検討し、それを示すデータを収集します。
また、MaxEntは使用するデータの解像度を統一しなければならないので、データの解像度もここで決めておきます。今回は四国全域を対象とするので3次メッシュ(1平方km)をベースとします。3次メッシュならば、国土数値情報で様々な環境データが公開されており、比較的容易な前処理だけで分析に利用できます。ここでは以下のデータを用意します。
・植生調査3次メッシュデータ(生物多様性センター)
http://gis.biodic.go.jp/webgis/sc-023.html
https://www.biodic.go.jp/dload/mesh_vg.htm
・標高・傾斜度3次メッシュデータ(国土数値情報)
https://nlftp.mlit.go.jp/ksj/gml/datalist/KsjTmplt-G04-a.html
・平年値(気候)メッシュデータ(国土数値情報)
https://nlftp.mlit.go.jp/ksj/gml/datalist/KsjTmplt-G02.html
・道路密度・道路延長メッシュデータ(国土数値情報
https://nlftp.mlit.go.jp/ksj/gml/datalist/KsjTmplt-N04.html
・土地利用細分メッシュ(ラスタ版)データ(国土数値情報)
https://nlftp.mlit.go.jp/ksj/gml/datalist/KsjTmplt-L03-b_r.html
III. 分析データの取得と前処理(分析領域レイヤの作成)
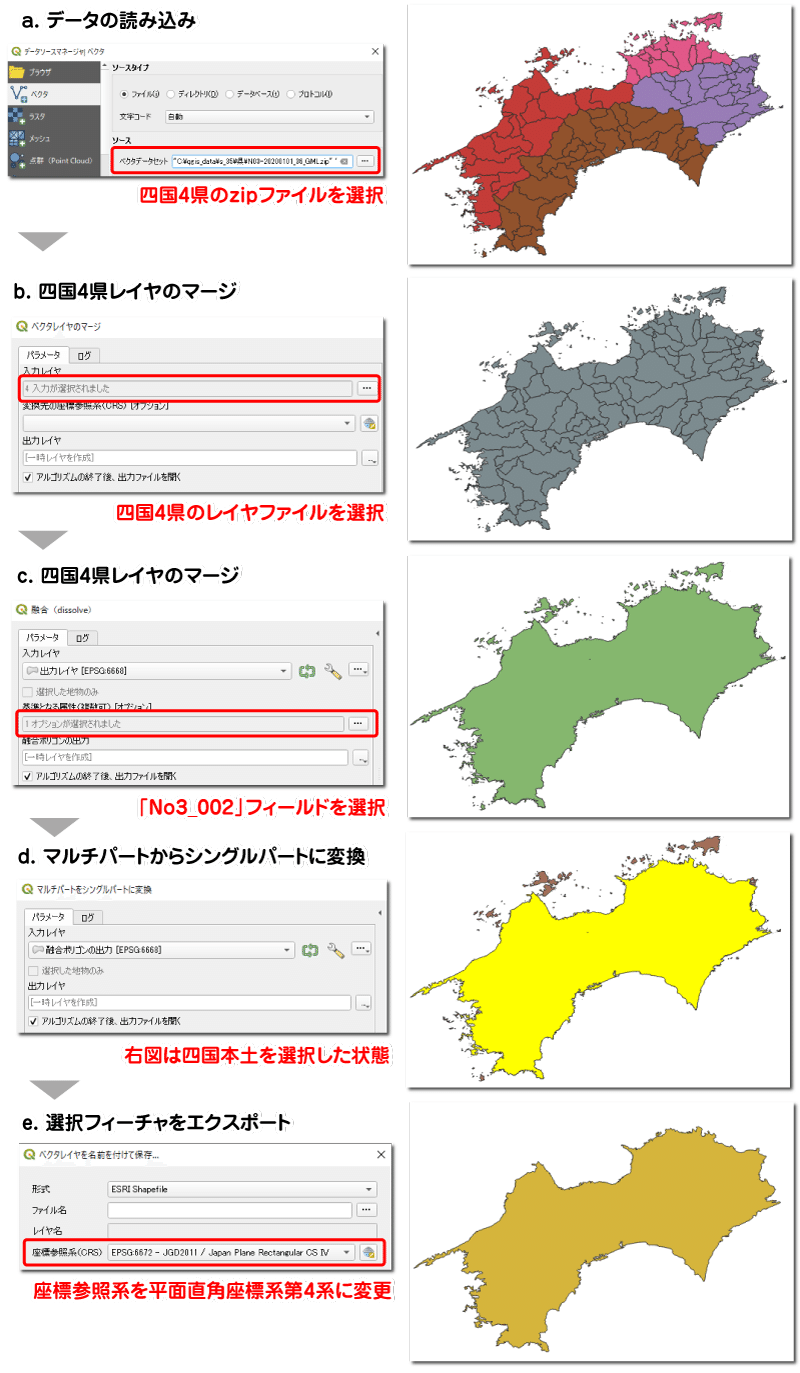
分析データを用意する前に、まず分析範囲の基準となる領域データを作成しておきましょう。これは、ジオリファレンスやメッシュデータの切り出しに利用します。四国の領域を示すポリゴンデータなら何でもよいですが、ここでは国土数値情報の行政区域データを使用します。四国4県の行政区域データを1つに結合し、四国本島のみを取り出したレイヤを作成します。
1. まず、四国4県のデータをダウンロードし、QGISに読み込みます。ダウンロードファイルはzip圧縮されていますが、そのまま読み込むことができます。
2. 続いて、メニューバーの「ベクタ」から「データ管理ツール」→「ベクタレイヤのマージ」ツールから4県のデータを1つに結合します。このとき、出力は一時レイヤで問題ありません。
3. メニューバーの「ベクタ」から「空間演算ツール」→「融合(dissolve)」ツールを用いて全てのフィーチャを結合します。ディゾルブフィールド(基準となる属性)には「No3_002」を選択します。No3_002は支庁・振興局名が入るフィールドですが、四国にはそれらの行政区分は無いので、情報が入っていません。そのため、ディゾルブによってNo3_002フィールドが空白であるフィーチャが一纏めに結合され、四国全体が1つのフィーチャになります。ここでも出力は一時レイヤで問題ありません。
4. メニューバーの「ベクタ」から「空間演算ツール」→「マルチパートをシングルパートに変換」ツールを使って四国本島と離島とを分割します。これも出力は一時レイヤで問題ありません。
5. 最後に、選択ツールで四国本島を選択し、レイヤの出力レイヤを右クリックして「エクスポート」→「新しいファイル名で選択地物を保存」します。このとき、座標参照系を「EPSG:6672/Japan Plane Rectangular CS IV」(平面直角座標系第4系)にしておきましょう。
5.で保存した四国本島レイヤを基準として、分析用データを準備します。
IV. 分析データの取得と前処理(在データのCSV作成)
MaxEntを実行するには在データのCSVファイルが必要です。CSVファイルは、次の3ステップによって作成します。
1. ソウシチョウの分布状況調査画像をジオリファレンス
2. 地点情報をポイントデータ化
3. フィールド演算で座標値を算出し、CSV形式で出力
まず準備として、QGISを新規に開き直し、1.で作成した四国本島ファイルを開きます。QGISウィンドウの右下を見て、プロジェクトの座標系が四国本島ファイルの座標系と同じEPSG:6672になっていることを確認します。
1. ソウシチョウの分布状況調査画像をジオリファレンス
NPO法人四国自然史科学研究センターのウェブサイトからソウシチョウの分布状況調査画像を保存し、QGISのジオリファレンスウィンドウで開きましょう。QGIS Ver.3.14以降であれば、メニューバーの「ラスタ」から「ジオリファレンサ」を選択すると、ジオリファレンスウィンドウが立ち上がります。ジオリファレンスウィンドウの「ファイル」から「ラスタを開く」をクリックし、ソウシチョウの分布状況調査画像を開きます。
次に、GCP(画像上のピクセル座標値と実世界上の座標値との対応関係を示した参照点)を追加し、分布状況調査画像と四国本島レイヤの位置合わせを行います。[ 点の追加 ] アイコンをクリックしてカーソルの形を変更したら、半島の先端のような対応関係の分かりやすいところをクリックします。すると「地図座標の入力」というボックスが表示されます。ここで座標系を「プロジェクトCRS」に変更し、[ 地図キャンバスから ] ボタンをクリックします。そして、先ほど画像上でクリックした場所と同じ地点を四国本島レイヤ上でもクリックします。すると、地図座標の入力ボックスのXYに座標値が入力されるので、[ OK ] ボタンをクリックしてGCPを確定させます。なおジオリファレンス操作の詳細は過去記事をご覧ください。
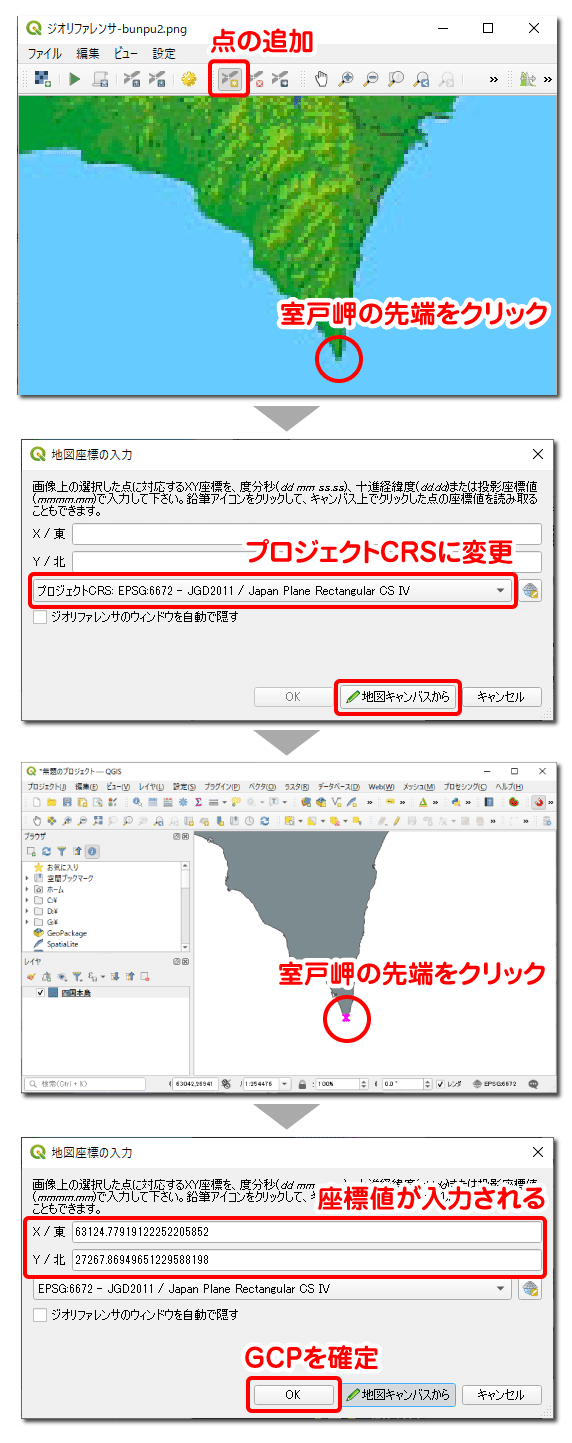
この操作を繰り返し、GCPを最低4つ、各地に満遍なく追加します。GCPを追加できたら、メニューバーの「設定」→「変換を設定」をクリックします。ここで、変換タイプを「線形」、変換先SRSを「EPSG:6672」、出力ラスタで保存先を指定し [ OK ] ボタンをクリックします。
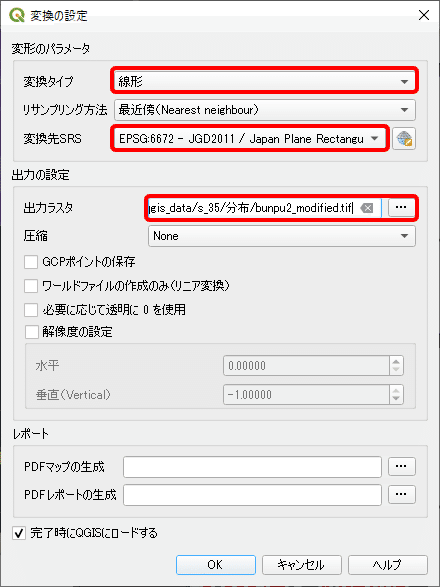
下図のように、GCPが4つ以上、残差が十分に小さい(今回は一桁以下)ことを確認できたら[ ジオリファレンスを開始 ]ボタンをクリックして処理を実行します。
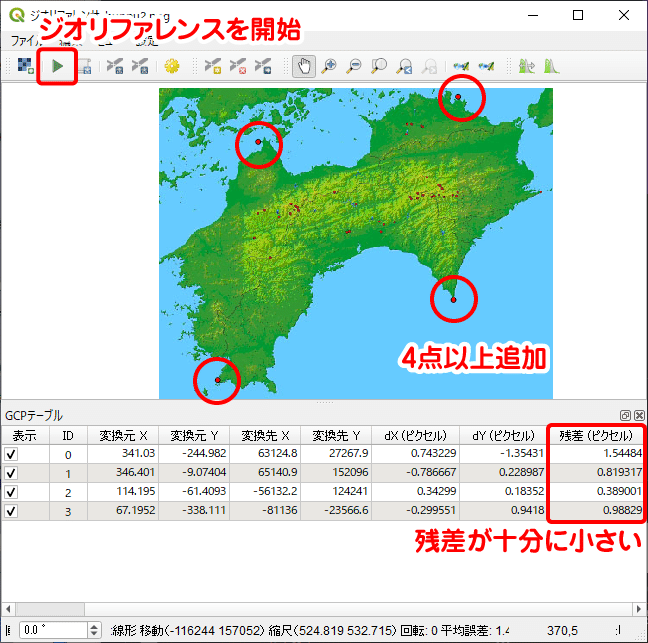
ジオリファレンスが完了すると、分布状況調査画像がレイヤに追加されます。正しくジオリファレンスできていれば、四国本島レイヤのほぼピッタリ重なっているはずです。
--- --- --- --- --- --- --- ---
2. 地点情報をポイントデータ化
ここではジオレファレンスした分布図を下絵として、分布地点のポイントデータを作成します。新規にデータを作成する場合は、まずデータを格納するための空ファイルを作成します。メニューバーの「レイヤ」から「レイヤの作成」を選びます。作成レイヤにはいくつか種類がありますが、どれを選択しても構いません。ここではGeoPakageを例にしますが、シェープファイル等を選択しても以下の操作は同じです。
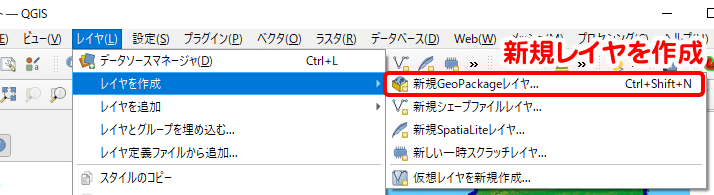
レイヤ作成ウィンドウでは、以下の3か所について設定します。
データベース:ファイルを作成する場所を指定
ジオメトリタイプ:ポイントを選択
座標系:プロジェクトCRS(EPSG:6672)を選択
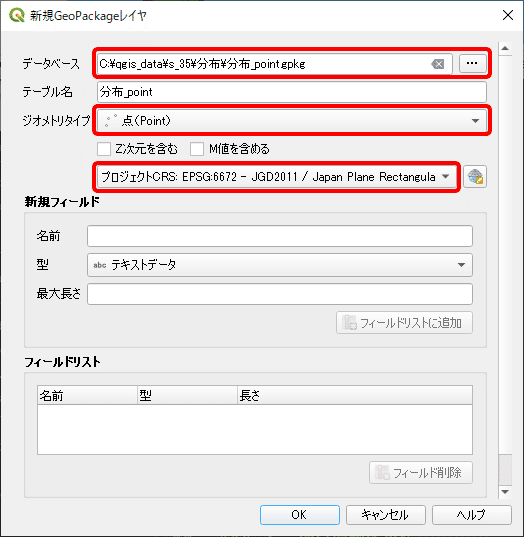
[ OK ]をクリックすると、レイヤにポイントレイヤが新しく追加されます。しかし、これは空ファイルなので中身のデータは存在せず、したがってキャンバス上には何も表示されません。
そこで、このポイントレイヤを編集して、ポイント情報を付与していきましょう。レイヤでポイントレイヤを選んだ状態でデジタイジングツールバーの鉛筆型のボタンをクリックすると、ポイントレイヤが編集モードに切り替わります(※2)。
※2 デジタイジングツールバーが無い場合は、メニューバーの「ビュー」→「ツールバー」からデジタイジングツールバーにチェックを入れます。
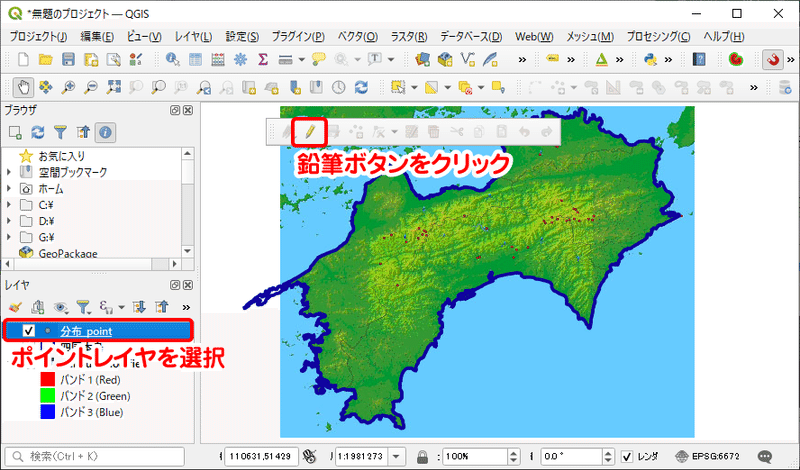
編集モードになると、デジタイジングツールバーのボタンが有効化されます。鉛筆ボタンの2つ隣りに [ 点地物の追加 ] ボタンがあり、これを使ってポイントを作成します。[ 点地物の追加 ] をクリックすると、カーソルのかたちが変わります。この状態でキャンバス上をクリックすると、クリックした場所にポイントが作成されます。このとき、属性情報の入力に関するボックスが表示されますが、[ OK ] ボタンをクリックします。
マップを拡大し、分布状況調査画像の目撃地点にポイントを作成していきましょう。目撃地点は、全部で40箇所あります。
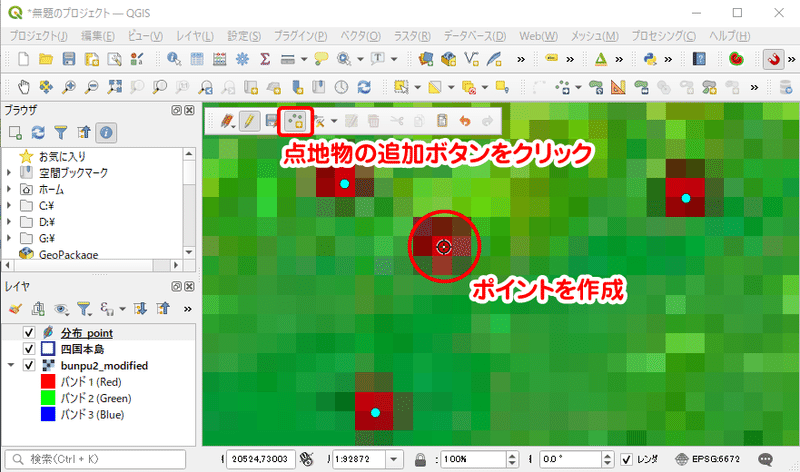
ポイントの作成が終わったら、鉛筆ボタンの右隣にある [ 編集内容の保存 ] ボタンをクリックし、編集を保存します。そして、鉛筆ボタンをクリックして編集モードを終了します。
--- --- --- --- --- --- --- ---
3. フィールド演算で座標値を算出し、CSV形式で出力
ここまでの工程でポイントデータが作成できましたが、MaxEntに必要な情報は座標値を含むCSVファイルでした。そこで、最後にフィールド演算によって属性テーブルに座標値を付加し、それをCSV形式で出力する作業を行います。
まず、ポイントデータの属性テーブルを開きます。属性テーブルのメニューに [ フィールド計算機を開く ] ボタンがあるので、それをクリックしてフィールド計算機を開きます。フィールド計算機では下図のように、新しいフィールドの作成、フィールドの名前、フィールド型、計算式の4つについて設定します。
「新しいフィールドを作る」にチェックを入れ、フィールド名は x としておきます。フィールド型は小数点付き数値にします。シェープファイルを作成した場合、フィールド長も設定します。左のボックスには10、右のボックスには3を入力します(全10桁、うち小数点以下に3桁使用の意味)。計算式には「$x」と入力します。これは、ポイントデータが内部で持っているx座標の情報を書き出す関数です。数式欄に直接書き込んでもよいですし、真ん中の関数ボックスのジオメトリの中から選択して入力してもOKです。設定が完了したら [ OK ] をクリックします。
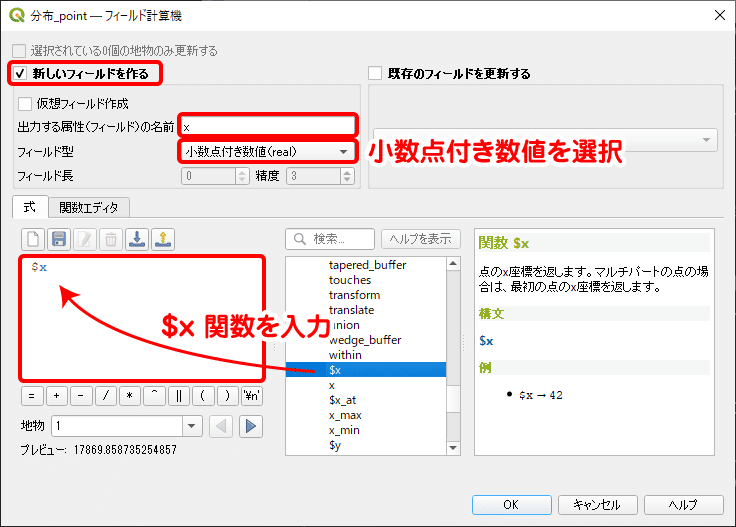
下図のように、x座標値が入ったフィールドが追加されます。同様にして、y座標の座標値も属性テーブルに追加しましょう。y座標を書き出す関数は「$y」です。x、yが追加できたら、属性テーブルのメニューにある保存ボタンを押して内容を保存、属性テーブルを閉じます。
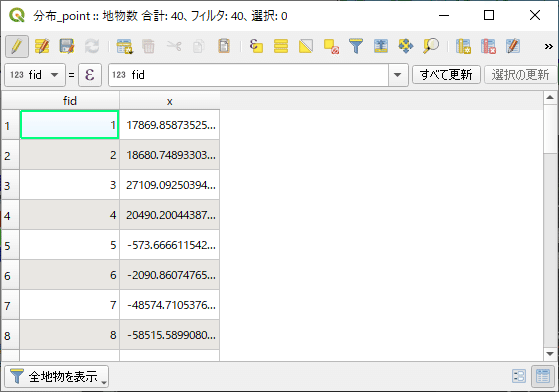
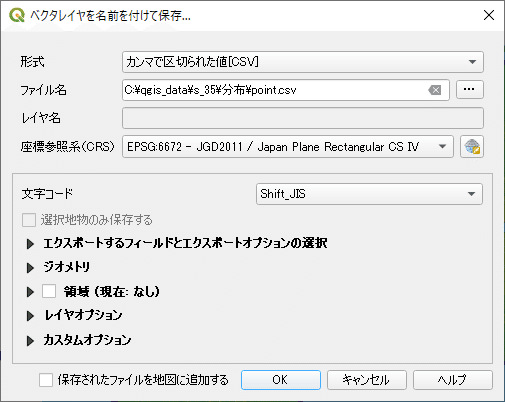
ポイントレイヤを右クリックし、「エクスポート」→「新しいファイル名で地物を保存」を選択します。保存形式をCSVに変更し、保存先を設定して [ OK ] をクリックすると、属性テーブルの内容がCSV形式で保存されます。
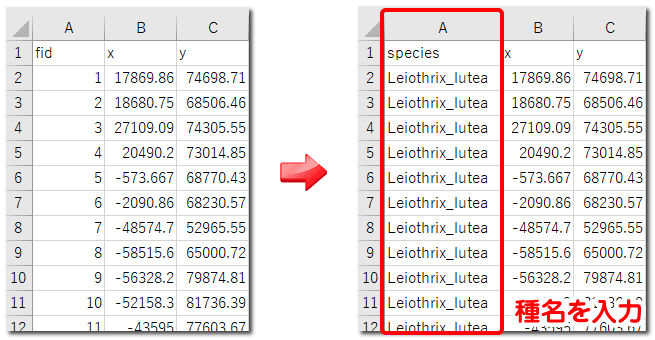
最後に、MaxEntの読み込みに対応するため、若干の修正を行います。QGISで保存したCSVは、1列目にID番号が振られています。MaxEntでは1列目に分析対象の名前が必要になります。そこで1列目には、各行の値がソウシチョウの情報だと分かるように値を入力します。ヘッダー名や内容に特に決まりはありませんが、ここではヘッダー名を「species」とし、値はソウシチョウの学名から「Leiothrix_lutea」を入力しました。なお、2列目は経度、3列目は緯度の順になるようにします。もし、y、xの順でフィールドを追加していたら、両者の並びを入れ替えておきましょう。
以上で、在データの準備が完了しました。最初から目撃情報の座標値がCSV形式で提供されていれば楽ですが、地図画像からでもジオリファレンスを利用することで座標値を得ることができます。
V. 分析データの取得と前処理(環境データの作成)
分析データ準備編の最後は環境データの作成です。MaxEntでは、環境データをEsri ASCII形式で用意します。また、各ラスターの座標系、セルサイズ、範囲が一致していることという条件も守らなければなりません。これらの点に注意しながら、前処理を進めていきましょう。
1. 植生調査3次メッシュデータ(生物多様性センター)
生物多様性センターでは、植生メッシュデータの他に1/25,000植生図データが公開されています。後者の方が、調査年次が新しくより詳細なデータとなっています。しかし、四国全域を対象とする今回の場合、1/25,000植生図データを選択すると多量のファイルをダウンロードして処理しなければならず、加えて3次メッシュベースに再集計する作業も必要になります。したがって、今回は植生メッシュデータを利用します。
提供データは、3次メッシュのシェープファイルと、植生情報が記述されたCSVファイルの2種類あります。データはそれぞれ日本全域のものとなっているので、必要な範囲を切り出したのち両者をテーブル結合する作業が必要になります(※3)。
まず、CSVから処理しましょう。ダウンロードしたCSVファイルの中身を見ると、メッシュコードと群落コードが入った約37万行のデータであることが確認できます。約37万行というのは、北海道から沖縄まで日本全国のデータになります。このうち、今回は四国の部分しか使わないので、不要な部分は手作業で削除しておきましょう。具体的には、メッシュコードの上二桁が36から47以下、および53以上は削除して問題ありません(※4)。ざっくりと削除すれば残りは12万行くらいになります。
※3 テーブル結合はデータの規模が大きくなるほど処理が遅くなります。したがって、手順を逆にする、すなわちテーブル結合してから必要な範囲を切り出そうとすると大変なことになります。
※4 標準地域メッシュの仕様上、メッシュコードの上二桁はその地域の緯度を1.5倍した値と対応しています。したがって、四国の北端(34度)と南端(32度)をそれぞれ1.5倍した値に多少のバッファ(秒以下の値の影響)を考慮して、48~52の範囲に納まっているだろうと概算します。
次に、群落コードが何を示しているのかを確認します。植生調査共通凡例コード(※5)を見ると、群落コードは群落名と対応しており、その分類は約900に及びます。この分類は、今回の分析目的に対して細かすぎますね。植生区分コードや自然度コードならば、どちらも10区分程度なので扱いやすそうです。そこで、ここでは自然度コードを使用します。
※5 ファイル名は「veg_gunraku.csv」。植生3次メッシュデータと同じページからダウンロードできます。
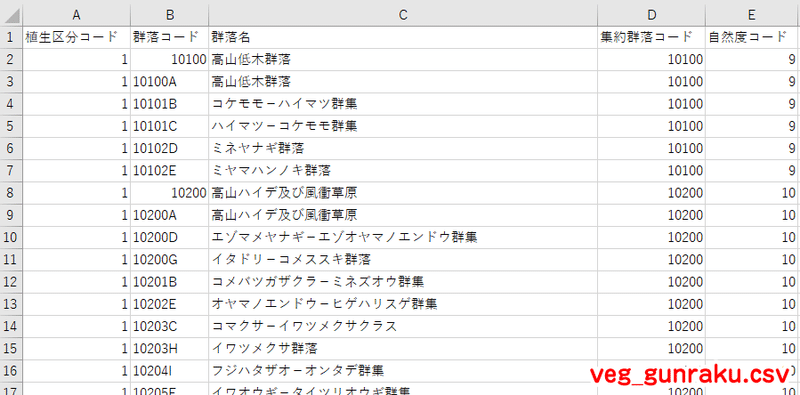
3次メッシュCSVには群落コードしかないので、3列目に自然度コード列を追加し、植生調査共通凡例コードを用いて群落コードと対応する自然度コードを付与します。
Excelで処理する場合は、群落コードと自然度コードの対応表を3次メッシュCSVの空いた部分にコピー&ペーストし、VLOOKUP関数やINDEX関数+MATCH関数などを用いて自然度コードを割り当てます。自然度コード列全体をコピーし、「値で貼り付け」によって上書きしてセルの中身を関数から値に直し、対応表は不要となったので削除します。
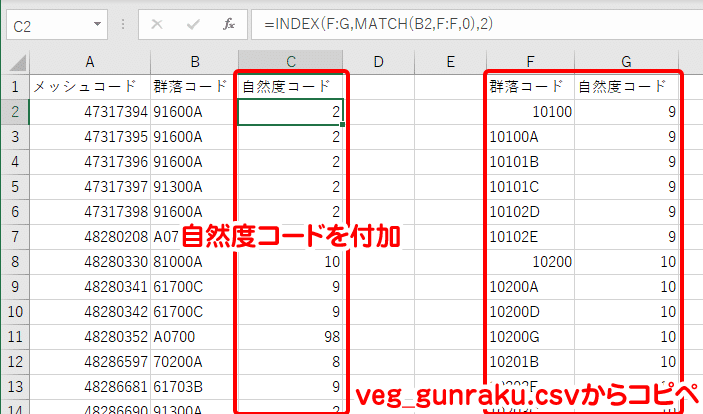
ここまでで3次メッシュCSVの処理が完了しました。次はメッシュデータの処理を行います。
作業環境をQGISに戻し、生物多様性センターからダウンロードした3次メッシュデータとIII. で作成した四国本島データを読み込みます。
3次メッシュデータと四国本島データの「交差する」という空間的関係を利用して、分析に使用する範囲のメッシュを切り出します。メニューの「ベクタ」から「調査ツール」→「場所による選択」をクリックします。新たに表示されたウィンドウで、選択する地物レイヤにメッシュを、比較対象の地物レイヤに四国本島を設定します。空間的関係は「交差する」でOKです。設定を確認し、[ 実行 ] をクリックしましょう。
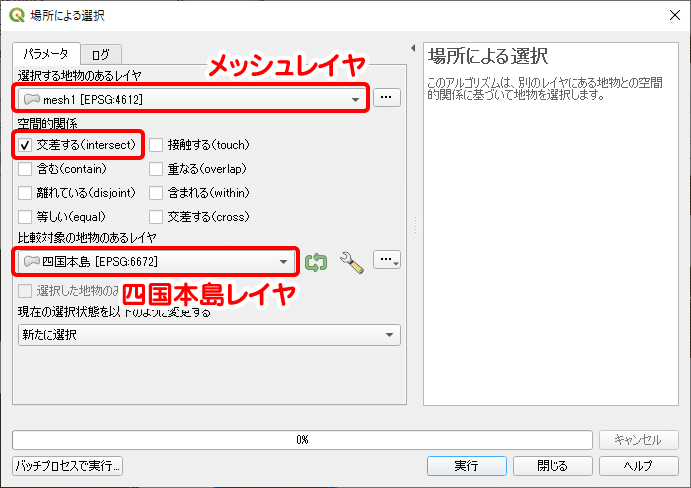
「場所による選択」により、四国本島レイヤと重なる3次メッシュが選択されました。この選択レイヤをエクスポートすれば、分析範囲の3次メッシュデータを得ることができます。レイヤを右クリックし、「エクスポート」→「新しいファイル名で選択地物を保存」と選択してエクスポートします。
最後に、メッシュデータとCSVファイルをテーブル結合します。QGISに上で作成した3次メッシュCSVと分析範囲メッシュデータを追加します。CSVはテキストファイルとして開くので、ジオメトリ定義は「ジオメトリなし」を選択します。
3次メッシュCSVと分析範囲メッシュデータがレイヤに追加されたら、メッシュレイヤのプロパティを開き、[ テーブル結合 ] ボタンをクリックします。続いてウィンドウ下の [ + ] ボタンをクリックし、結合の設定ウィンドウを開きます。
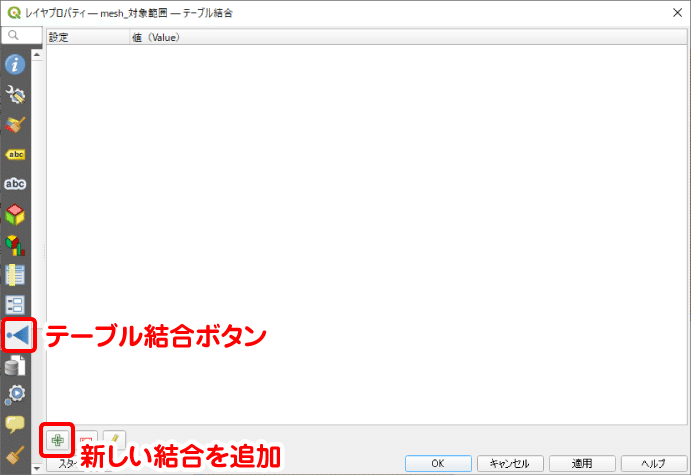
テーブル結合の設定では、「結合するレイヤ」にCSVレイヤ、「結合基準の属性」にCSV側のメッシュコードのヘッダー名、「ターゲット属性」にメッシュデータ側のメッシュコードのヘッダー名を設定します。「結合フィールド」にチェックを入れると、必要なフィールドのみを結合できます。
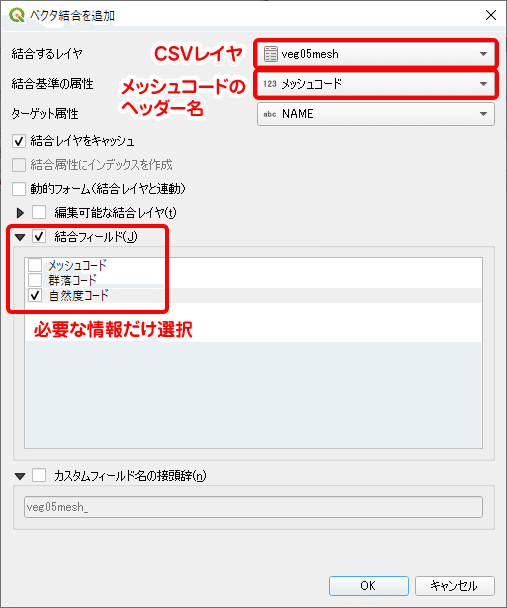
下図は、結合した自然度コードを用いてメッシュを色分けしたものです。配色はQGISが自動で指定したままになっています。地図を見ると山地の大部分はコード6、すなわち植林地に区分されることが分かります。
テーブル結合を行っただけでは、結合結果は保存されていません。データをエクスポートして、結合結果を保存します。このとき、保存するファイルの座標系を、在データの座標系と同じEPSG:6672に変更しておきます。
残る作業は、ラスター形式への変換です。これについては 4. で他の環境データと一緒に説明します。植生データについてはいったん区切りをつけ、次の環境データの整備に進みましょう。
--- --- --- --- --- --- --- ---
2. 標高・傾斜度3次メッシュデータ(国土数値情報)
次は、標高・傾斜度3次メッシュデータを分析用に加工します。まず、国土数値情報からメッシュデータをダウンロードしましょう。四国を覆う9つのファイルが必要になります。

ダウンロードした9つのzipファイルと四国本島データをQGISに追加します。ここで、標高・傾斜度3次メッシュのシェープファイルにはprjファイルがありません。すなわち、座標参照系の定義情報が欠けており、正しい場所に表示することができません。このような場合、QGISはプロジェクトの座標参照系を適用させてキャンバスに表示させます。QGISのデフォルトの座標参照系はEPSG:4612であり、たまたま標高・傾斜度3次メッシュの座標値と合っているので正しく表示されます。しかし、四国本島データを先に開くなどにより、プロジェクトの座標参照系がEPSG:6672になっていると、正しく表示されません。標高・傾斜度3次メッシュを開く前に、プロジェクトの座標参照系がEPSG:4612であることを確認しておきましょう。
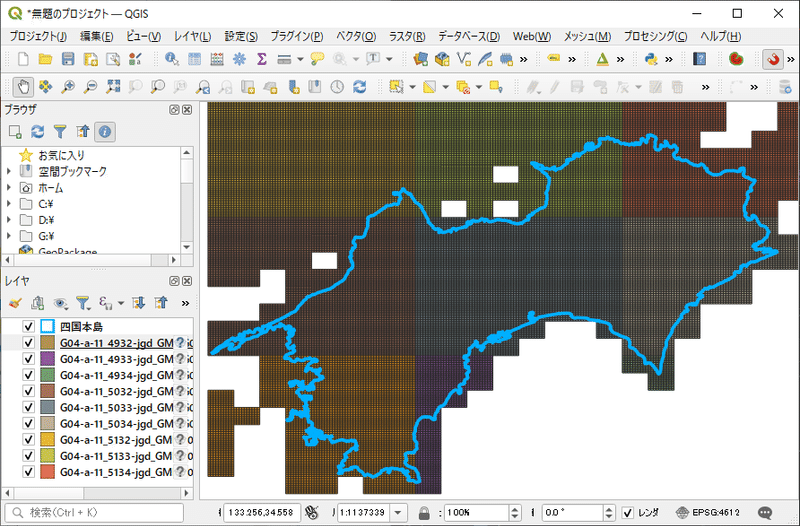
次にすべきことは、植生メッシュのときと同じく、四国本島レイヤに沿って切り出すことです。ただし、標高メッシュレイヤが1つにまとまっていた方が作業しやすいので、9つのメッシュをマージしてから空間検索を掛けて抽出します。
メニューバーの「ベクタ」から「データ管理ツール」→「ベクタレイヤのマージ」を選択します。ベクタレイヤのマージウィンドウの入力レイヤに9つのメッシュレイヤをセットし、マージを実行します。出力は一時レイヤで問題ありません。
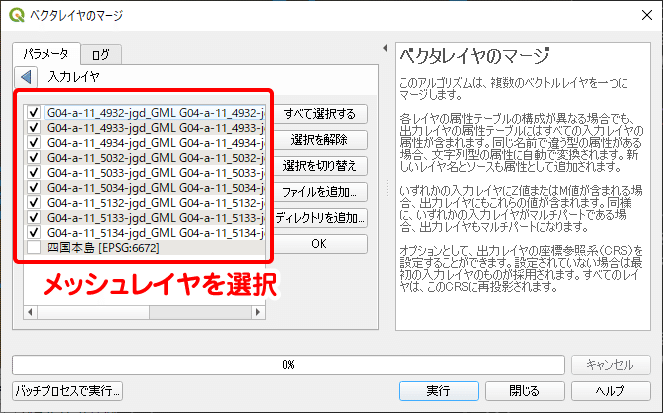
結合したメッシュレイヤが出力されたら、そのレイヤに対して「場所による選択」を実行し、選択されたフィーチャを「新しいファイル名で選択地物を保存」します。この作業は植生メッシュの時と全く同じです。保存する時には、座標参照系をEPSG:6672に指定することを忘れないようにしましょう。
エクスポートできたら植生メッシュと同様にいったん終了・・・としたかったのですが、もう1つ作業が必要です。属性テーブルを開いてみましょう。すると、属性テーブルの数値が全て左揃えで記載されています。これが意味するのは、フィールド型が文字列型であるということです。フィールド型が文字列型だと、ラスター化する際にそのフィールドをラスター値として使用できません。したがって、数値型に変換しておくことが必要になります。
シェープファイルは既存のフィールド型を変更することはできないので、フィールド演算によって新しく数値型のフィールドを追加します。属性テーブルからフィールド計算機を開き、各種設定を行います。フィールド型は「小数点付き数値」を選び、フィールド長は5、精度は1とします。数式は平均標高のフィールド名である"G04a_002"を記入します。
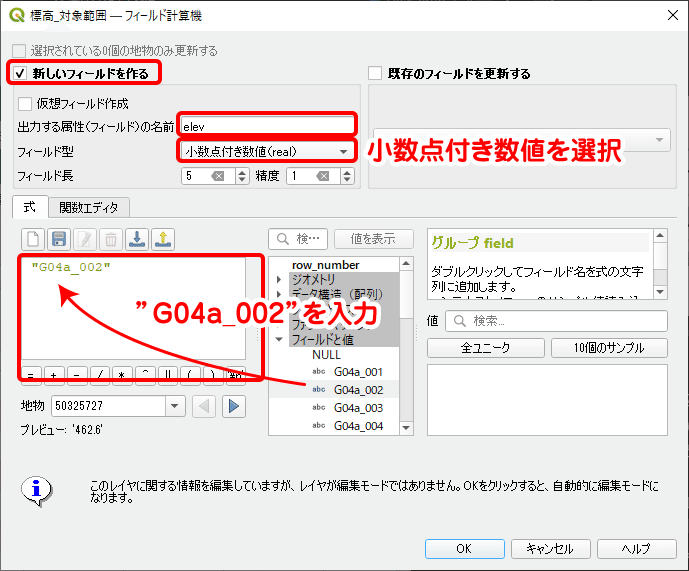
フィールド演算を実行すると、elevフィールドに数値型として標高値が入ります。標高の他にも、分析に利用できそうなものがあれば型変更しておきましょう。ここでは、平均傾斜角度(フィールド名:G04a_010)も変更しました。最後に編集を保存し、編集モードを終了します。これにて標高・傾斜度3次メッシュデータの前処理はいったん完了です。
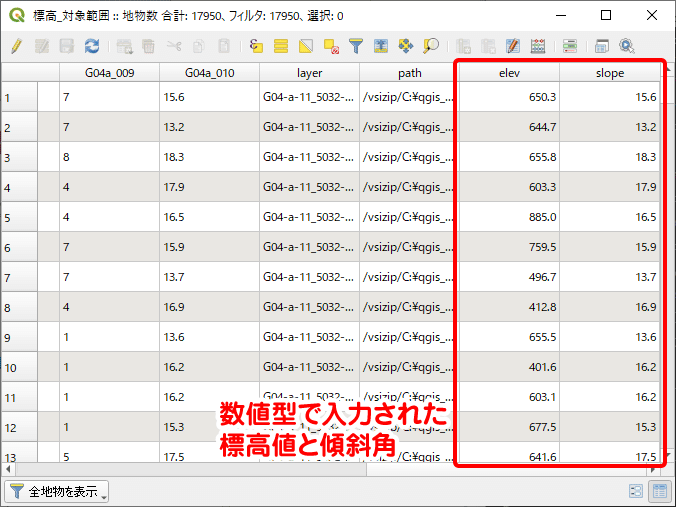
標高・傾斜度3次メッシュデータと同様の手順によって、平年値(気候)メッシュデータと道路密度・道路延長メッシュデータも、前処理を行うことができます(※6)。
解説は省略しますが、平年値(気候)メッシュデータでは年降水量(フィールド名:G002_014)と年平均気温(フィールド名:G002_053)、道路密度・道路延長メッシュデータでは幅員合計 道路延長_1k㎡当り(フィールド名:N04_056)を対象に分析用データを作成しました。
※6 平年値(気候)メッシュデータは、ダウンロードしたzipファイルのディレクトリ構成がzipファイル>フォルダ>shpファイルという構成となっているため、zipのままQGISで読み込むことができません。zipを展開してシェープファイルを読み込みましょう。道路密度・道路延長メッシュデータは、属性情報の値が数値型で入っているので、フィールド演算は不要です。
--- --- --- --- --- --- --- ---
3. 土地利用細分メッシュ(ラスタ版)データ(国土数値情報)
土地利用データには土地利用細分メッシュのラスターデータを使用します。標高データと同様に、まずは四国をカバーする9つのデータをダウンロードし、zipファイルから直接ラスターデータとしてQGISで開きましょう。
次に、ラスターを結合します。メニューバーの「ラスタ」から「その他」→「結合(gdal_merge)」を選択し、入力レイヤに9個のレイヤを指定して処理を実行します。出力先は一時ファイルでOKです。
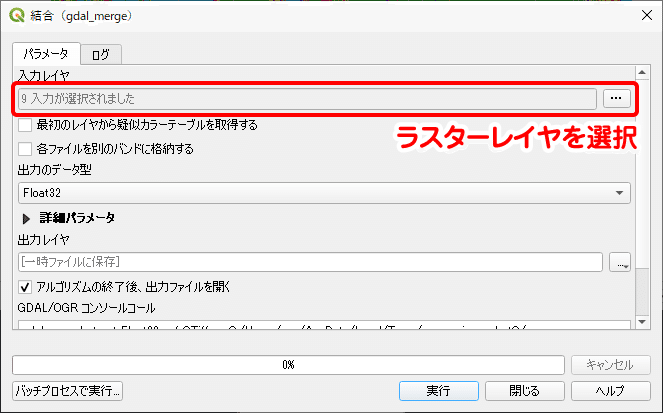
植生メッシュや標高メッシュの時は、四国本島レイヤを使って必要な範囲を切り抜いていましたが、今回はすでに切り出したメッシュレイヤを使ってラスターの情報を集計し、メッシュにデータを付与します。植生メッシュの前処理工程で、四国本島レイヤとの空間関係を用いて切り出したメッシュファイルを開きます。次に、メニューバーの「プロセシング」から「ツールボックス」を表示させ、「ラスタ解析」の中にある「ゾーン統計量(ベクタ)」を実行します。
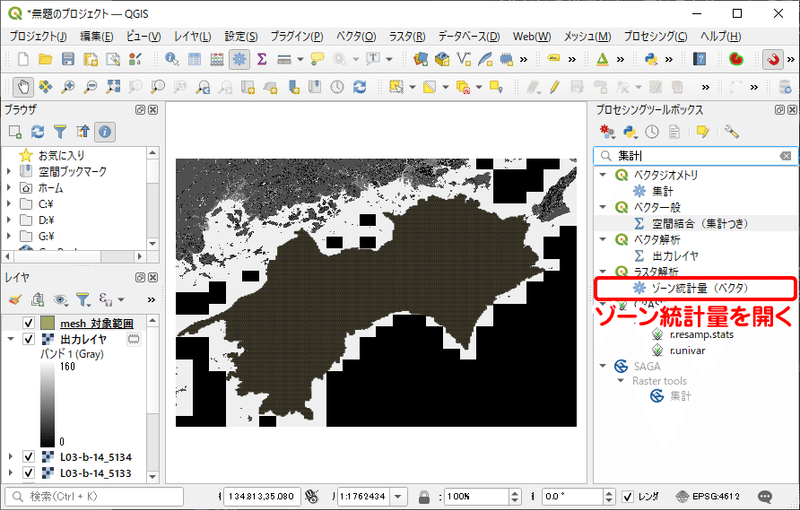
入力レイヤにメッシュレイヤを、ラスタレイヤに結合したレイヤを選択、計算する統計量には最頻値を設定します。最頻値とすることで、1つのメッシュの中に含まれるラスターの各値のうち、もっとも出現頻度の高いものをそのメッシュの代表値とすることができます。出力先は一時レイヤにします。
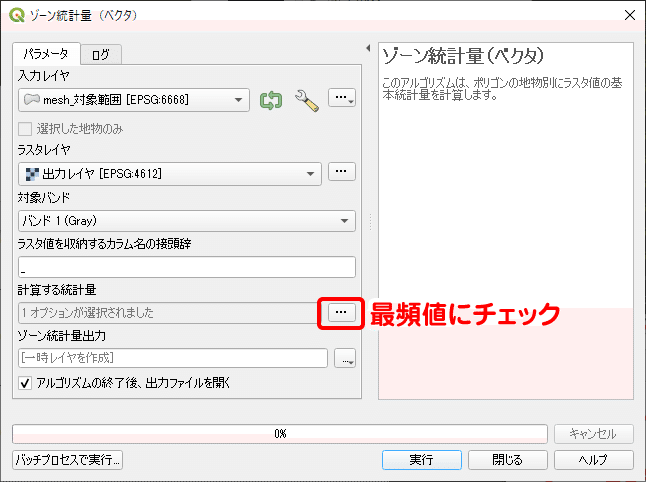
下図に、元のラスター画像と集計後のメッシュレイヤを同じ配色に設定して並べてみました。両者の土地利用分布の傾向は同じであり、正しく集計できていることを確認できます。
最後に、一時レイヤをエクスポートしてシェープファイル等の形式で保存しましょう。このとき、座標参照系をEPSG:7762に指定しておきます。
--- --- --- --- --- --- --- ---
4. メッシュデータをASCIIファイルに変換
環境データの作成完了まであと一歩のところまで来ました。最後に、これまで作成したメッシュデータをASCII形式のラスタファイルに変換します。まず1. ~ 3. で作成した、ラスタに変換するメッシュデータをすべてQGISに読み込みます。
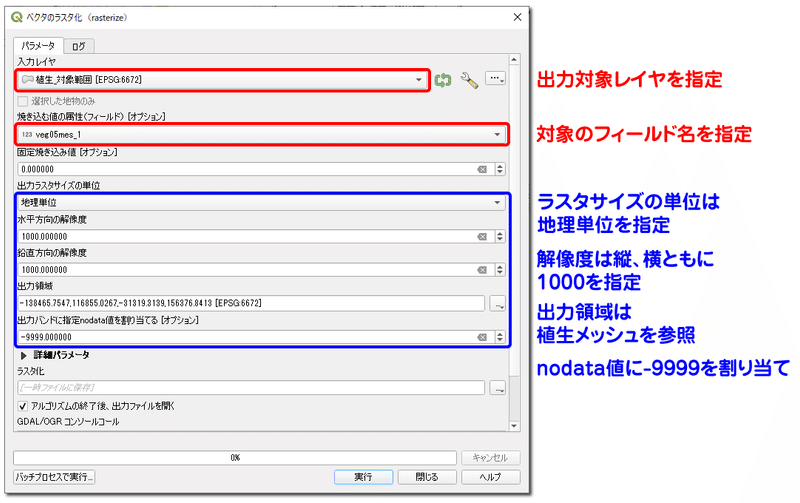
次に、メニューバーの「ラスタ」から「変換」→「ベクタのラスタ化」を選択します。ラスタ化の設定は下図のようにします。
まず、図の赤枠で囲んだ部分は変換対象となるレイヤごとに適切に選択します。例えば植生メッシュを入力レイヤに選んだら、「焼き込む値の属性」には自然度コードのフィールドを指定します。
一方、青枠で囲んだ部分は共通で下図のように設定します。「出力ラスタサイズの単位」は地理単位、解像度は水平、鉛直方向ともに1000にします。1000にするのは、元のメッシュが3次メッシュ(1kmメッシュ)であることに対応しています。出力領域は「レイヤから計算」→「植生メッシュレイヤ」を指定しておきます。指定するレイヤは他のレイヤでも構いませんが、必ず全ての変換処理において同じものを指定するようにします。これによって、各ラスターの範囲を一致させるようにしています。nodata値の割り当てはオプションですが、未指定だと0が割り当てられ、意味のある0(例えば標高0m、平均気温0度など)との区別が付かなくなるので、-9999のような値を指定するのが一般的です。出力ファイルについて、設定上はASCII形式で出力ができますが、実際には出力エラーが出て保存されない可能性が高いです。したがって、ここでは一時ファイルに出力し、一時ファイルを形式変換によってASCII形式で保存するという2段階のステップを取ります。
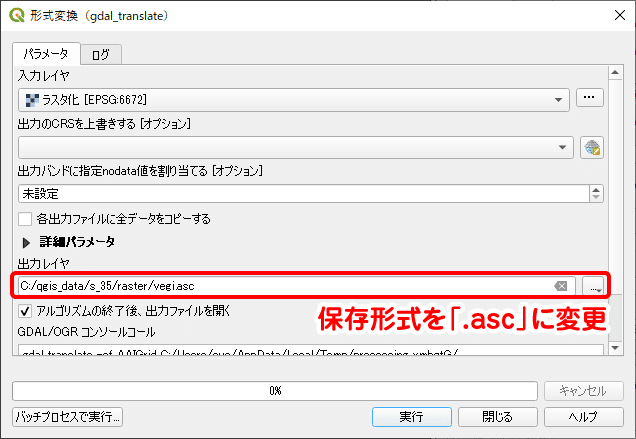
一時ファイルを出力できたら、メニューバーの「ラスタ」から「変換」→「形式変換」を選択します。入力レイヤを一時レイヤに、出力レイヤの保存形式を「.asc」に設定したら [ 実行 ] し、ASCII形式として保存します。出力先のフォルダを作成しておき、ラスターファイルを1か所に纏めて保存しておきます。
各レイヤ、フィールドについてこれを繰り返し、全てのメッシュデータをラスター形式に変換しましょう。
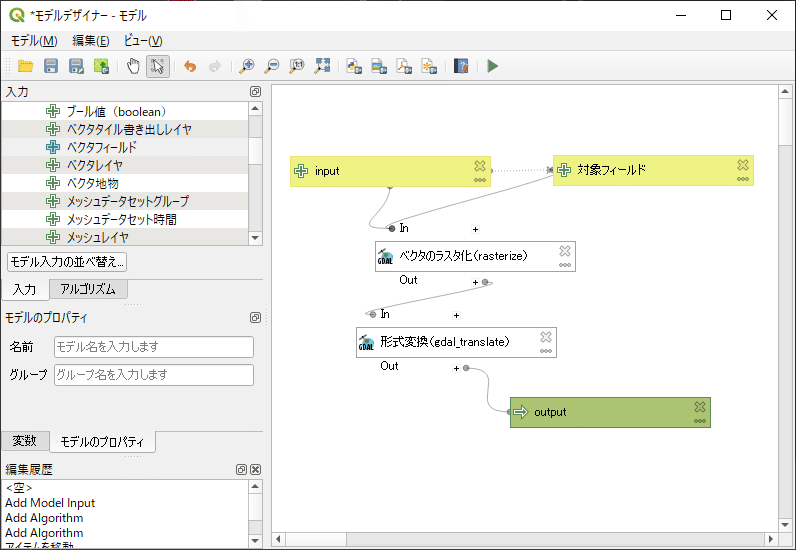
ちなみに、何度も同じような作業を繰り返す場合は、モデルデザイナーを使って処理をモデル化することで、出力を自動化できます。下図のモデルは、対象レイヤ、対象フィールド、出力ファイル名については毎回手動で設定しているので半自動化ですが、機能の呼び出しや共通設定などを都度設定することなくASCIIファイルを出力できます。モデルデザイナーの活用方法は他の記事で解説したいと思います。
VI. MaxEntによるソウシチョウの生息適地推定
分析に必要なデータが揃ったので、いよいよMaxEntを用いた分析です。まず、下記のページからMaxEntをダウンロードしましょう。ページ中段のDownload枠のリンクからダウンロードします。「I prefer to download without providing this information」と書かれた部分をクリックすれば、個人情報を送付しなくてもダウンロードボタンが表示されます。
ダウンロードしたzipファイルを展開すると、4つのファイルが入っています。このソフトウェアはインストール不要で実行できます。maxent.batをダブルクリックしてソフトウェアを起動しましょう。
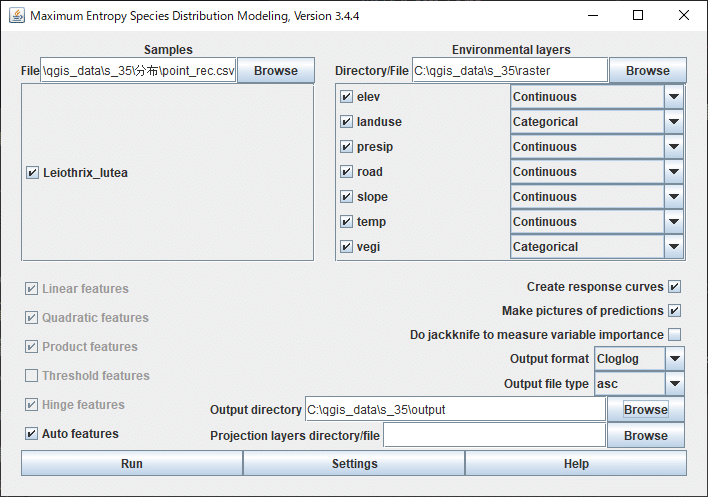
ソフトウェアが開いたら、データの読み込みを行います。左上の [ Browse ] では、在データのCSVファイルを指定します。右上の [ Browse ] では環境データが入っているフォルダを指定します。
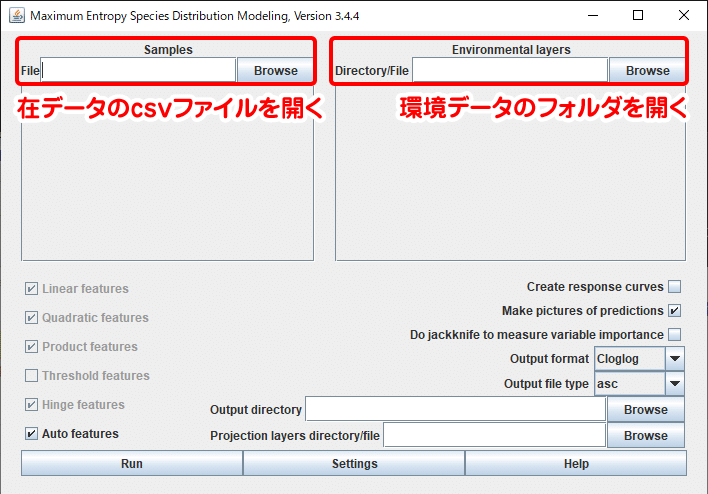
ファイルやフォルダを設定すると、分析に使用するデータの内容が表示されます。在データ側に表示された「Leiothrix_lutea」は、CSVの1列目に入力したソウシチョウの学名です。今回はソウシチョウの1種のみのデータを用意したので、表示されるチェックボックスも1つだけです。
環境データ側には標高や土地利用など、V章で作成したラスターデータが表示されています。右のプルダウンは、データの種類が連続(Continuous)であるか、カテゴリカル(Categorical)であるかを指定します。土地利用と植生はカテゴリカルデータなので、設定を「Categorical」に変更します。
ウィンドウの下部では分析方法や出力の設定を行います。重要なのは「Output directory」で、レポートを保存する場所を指定します。その他は、とりあえずはデフォルトのままでも問題ありません。
左のチェックは分析モデルの設定です。「Auto features」を選択しておけば最適なモデルが自動的に選ばれるので、特別な理由が無ければAutoで良いと思います。右のチェックは分析レポートの出力設定で、3つのチェックは上から順に反応曲線の出力、予測マップ画像の出力、ジャックナイフテストの結果の出力をするかどうかを設定します。「Output format」は計算結果の変換方法の指定で、開発者のPhillips(2017)によれば、Cloglogが良いと述べています(※7)。その下の「Output file type」は予測マップのファイル形式の設定ですが、デフォルトである「asc」のままにしておきます。
入力・出力の設定ができたら、[ Run ] ボタンをクリックして解析を実行しましょう。
※7 以前はLogisticが用いられていました。Cloglogは高適性域の値をより顕著にし、メリハリのついた分かりやすい分布図を描くことができるそうです。
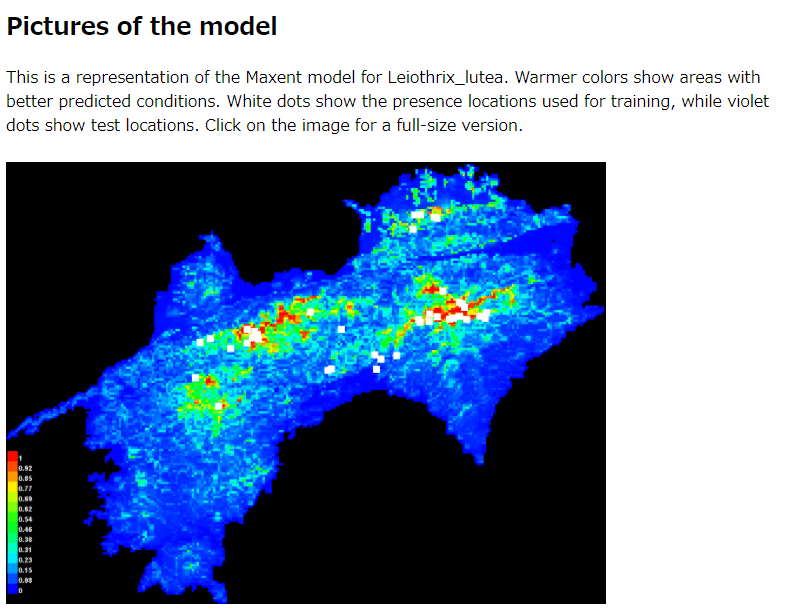
解析が終了すると、出力先フォルダにhtml形式のレポートファイルが生成されています。レポートファイルをブラウザで開いてみましょう。モデルの精度評価指標(AUC)、変数の影響(反応曲線や寄与度)など検討すべき点は幾つかありますが、とりあえず推定された分布図を見てみましょう。
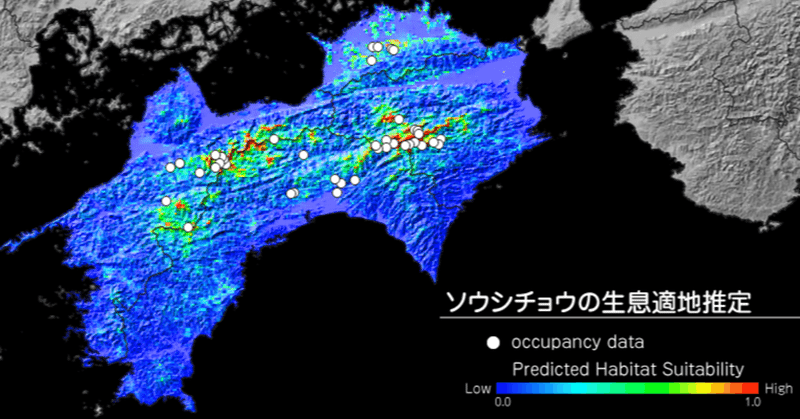
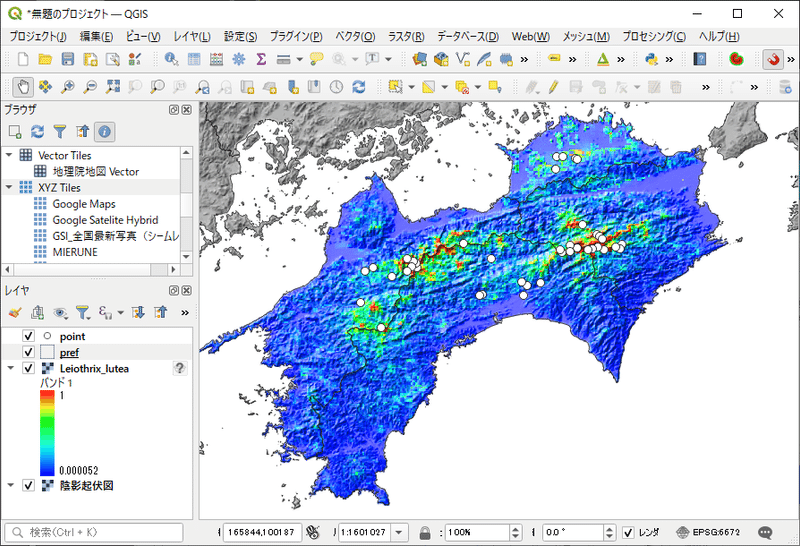
下図が、推定されたソウシチョウの分布マップです。青色の地域は生息確率が低く、赤色の地域が生息している可能性の高いと見積もられています。白い点が在データです。標高の高い地域を中心に生息確率が高く推定されています。レポートファイルのマップはpngファイルですが、QGISで開けるASCIIファイルも出力されています。最後に推定結果をQGISで表示させてみましょう。
QGISのショートカットキー [ Ctrl ] + [ Shift ] + [ R ] でデータソースマネージャを開き、分布推定のascファイルを開きます。ascファイルには座標参照系の定義が付いていませんが、入力ファイルと同じ座標参照系で出力されています。したがって、プロジェクトの座標系をEPSG:6672にしておきます。
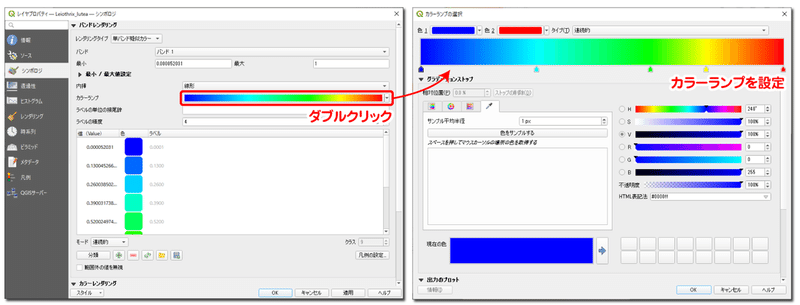
レイヤのプロパティを開き、下図のようにシンボロジを設定します。カラーランプは、レポートの画像と合うように独自に設定しました。
更に、背景に国土地理院の陰影起伏図のタイル画像を追加し、分布推定レイヤをオーバーレイ設定で重ねています。また、IV. で作成した在データをポイントデータとして追加しました。QGISならばマップを拡大・縮小でき、他のデータと重ね合わせることができるので、推定結果をより詳しく考察することができます。
VII. おわりに
今回は、MaxEntを使って生息分布を推定する方法を、特に分析データをどのように準備するかに焦点を充てて紹介しました。ポイントは、分析範囲の基準とするポリゴンを作成することで、そのポリゴンを用いてデータの切り出しやラスターデータの作成範囲を決定します。また、座標系もポリゴンの領域に合わせてどの座標系で共通させるかを決めておきます。MaxEntは、地理座標系でも投影座標系でも問題ないようですが、ラスター形式を扱う場合は投影座標系を選ぶ方が無難なことが多いです。
最後に、ここまでの分析の流れの中で抜けていたもの、すなわち「どのような環境データ(変数)を利用すればよいか」について補足したいと思います。
分析に使用するデータは、II-3でみたように、先行研究に沿って対象となる生物の生態と関係がありそうな環境情報を選択します。このとき、今回の分析では検討しませんでしたが、使用する変数間の相関関係に注意し、高い相関が見られる場合はデータセットから落とすことを考えなければなりません。相関のある変数を分析に使用すると、推測に寄与した変数の評価を正しく行えなくなる可能性があります。
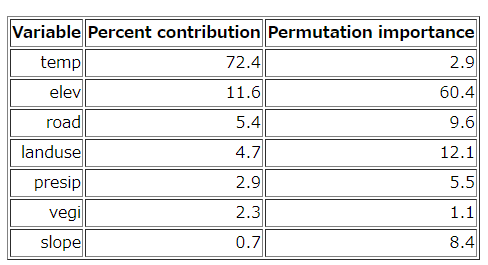
また、分析レポートの結果を見て使用する変数の再検討を行うことも重要です。分析レポートに記載された次の表は、各変数の寄与率と並べ替え重要度を記載したものです。寄与率は各変数がモデル作成に使用された割合であり、並べ替え重要度はモデルに依存せず変数の重要性を評価したものです。今回のモデル作成に最も寄与した変数は気温で72.4%、次点で標高の11.6%となっています。一方、並べ替え重要度では標高が60.4%、次いで土地利用が12.1%となっており、気温は2.9%しかありません。
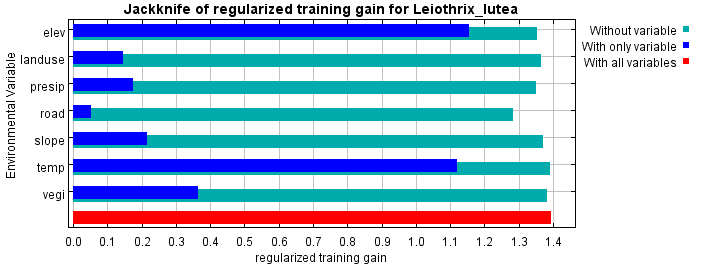
ジャックナイフ法では各変数について、それを用いなかった時のAUC(緑の棒グラフ)、それしか用いなかった場合のAUC(青)、全ての変数を用いた場合のAUC(赤)を棒グラフで示しています。標高と気温は、それだけを投入したモデルでも比較的高いAUCを示すモデルを作ることができ、それぞれを除いたモデルでもAUCが下がらないことが分かります。寄与率、並べ替え重要度の結果も考慮すると、気温と標高は高い相関関係にありそうです。また道路密度について、道路密度のみで分析した際のAUCは非常に低く、予測への貢献度は高いとは言えません。しかし、道路密度を除いた場合のAUCは、他の変数を除いた場合と比べて低くなっています。したがって、道路密度には他の変数には無い情報があると考えられます。
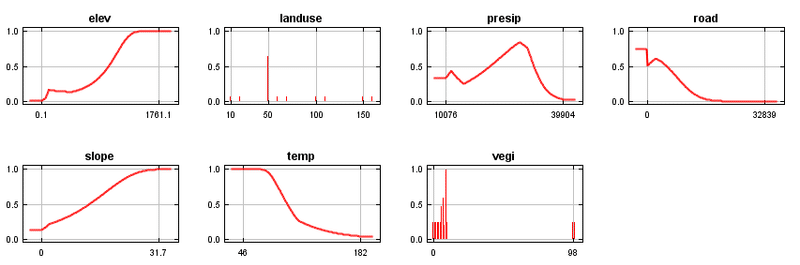
反応曲線も、変数選択の参考になります。これは各変数が予測にどのように影響するかを値の変化とともに示しています。もしグラフが水平ならば、予測に寄与していないのでデータセットから除いても良いと考えられます。また、図中の土地利用のように、ある1つのカテゴリーのみが寄与し(図ではコード50:森林)他のカテゴリーの反応が低い場合、その反応の高いカテゴリーに関する環境データ(例えば森林率、森林からの距離など)を用意した方がモデルの改善に繋がるかもしれません。
このように、分析は1回実行したら終わりではなく、モデルの精度を高めるためには各変数の反応を見ながらフィードバックを重ねることが重要になります。
参考ウェブサイト、参考文献
"Current tutorial in English". American Museum of Natural History. (PDF)
”Maxentを利用したクマタカ営巣適地の抽出”. 株式会社エコリス. (Link)
"【Maxent】QGISを用いたMaxEntの生息適地図作成方法※初心者向け【QGIS】". 初心者の備忘録. (Link)
岡久雄二、岡久佳奈、小田谷嘉弥. ライトセンサスと Maximum Entropy Model による佐渡島におけるヤマシギ Scolopax rusticola の越冬分布推定. 日本鳥学会誌, Vol. 68, No. 2, pp. 307-315, 2019. (PDF)
草野保. 種分布モデリングによるトウキョウサンショウウオの好適生息環境の予測. 爬虫両棲類学会報, Vol. 2016, No. 2, 2016. (PDF)
橋本大、長谷川雅美. 冬期の印旛沼流域における猛禽類の環境選好性と生息環境評価. 千葉県生物多様性センター研究報告, Vol. 7, pp. 65-78, 2014(PDF)
Steven J. Phillips Miroslav Dudík. Modeling of species distributions with Maxent: new extensions and a comprehensive evaluation. Ecography, Vol. 31, pp. 161-185, 2008.(Link)
Steven J. Phillips Robert P. Anderson Miroslav Dudík Robert E. Schapire Mary E. Blair. Opening the black box: an open‐source release of Maxent. Ecography, Voi. 40, pp. 887-893. 2017.(Link)
記事の内容でもそれ以外でも、地理やGISに関して疑問な点があれば、可能な限りお答えしたいと思います。