
trocco®開発ログ 2022春「Snowflakeデータマート、データカタログ他」

マネージド ETL&ワークフローサービスの trocco® を開発している primeNumber社 CTO の鈴木です(自己紹介記事)。trocco® はデータエンジニアの方々の様々な手間を削減し、より価値ある業務に集中していただくためのプロダクトです。BigQueryなどを中心にした分析基盤構築をサポートします。
昨年、Series B の資金調達を終え、より多くのお客様に価値を提供するべく trocco® の開発を進めております。
面接の場などで「trocco® のエンジニアは実際にどんな開発を行っているの?」と良く聞かれるため、今回は trocco® で2022年の1-4月にリリースした機能をいくつか紹介します。
実際の顧客課題やそれに対する機能開発の事例を通じて、チームが日々どんな開発を行っているか、少しでも知っていただければ幸いです。
trocco® とは?

https://trocco.io/lp/index.html
trocco® は、MySQL や S3 などのデータを BigQuery を始めとしたデータウェアハウス(DWH)に統合し、分析基盤を構築するためのデータエンジニアリングサービス です。大企業からスタートアップまで様々な企業にご利用いただいており、お客様からは「trocco® 無しでは分析基盤構築は考えられない」など、嬉しいフィードバックを多々頂いてます。
trocco® が解決する課題
BigQuery などを利用して分析基盤を構築する会社は増えていますが、多くの場合、データ統合(MySQL や S3 のデータを BigQuery に転送する)のパイプラインはデータエンジニアの方が自前で開発しています。安定したパイプラインを構築・運用するのは非常に手間がかかり、データエンジニアがより戦略的な業務に時間を割きにくいという課題がありました。
trocco® を利用することで、データ統合部分をまるっと任せることができます。
現在はデータ統合だけでなく、データエンジニアリング周辺の様々な業務までカバー領域を広げていて、分析基盤構築については全てを trocco® に任せられる状態を目指しています。
リリース機能 1: 「転送先 kintone の UPSERT 対応」
それでは、直近数ヶ月でリリースした数多くの機能の中から、いくつかピックアップして紹介します。
まずは、trocco® のメイン機能である、データ転送機能の改修を紹介します。
trocco® では転送先として kintone をサポートしています。簡単な設定を行うだけで、BigQuery などの任意の転送元から kintone に対してデータを転送することが出来ます。
転送元サービスの追加や、転送先の改修などは、特にユーザーの要望が多い部分です。
今回は、kintone にデータを転送する際に、
kintone 上に既存のレコードが存在する場合は更新
既存のレコードが存在しない場合は追記
する機能を実装しました。

trocco® では、データ転送の多くにおいて、OSS の Embulk を利用しています。
Embulk はプラグインアーキテクチャ構造になっており、転送元、先それぞれ Embulk のインターフェースに従って Java や Ruby で plugin を開発することで、データ転送を行うことができます。
転送先 kintone では、trocco® で開発している embulk-output-kintone を利用しているため、こちらに対して改修を行い、UPSERT 機能を実装しました。
また、trocco® のサーバーサイドは Rails、フロントエンドは React(TypeScript)で開発されています。ユーザーが実際に触る画面側や API、Embulk をキックする部分などの改修を行うことで、実際にユーザーに対して機能を提供することが可能です。
リリース機能 2: 「Snowflake データマート」
trocco® には、DWHに対して直接クエリを実行し、集計テーブルの作成などを行うことができる「データマート」機能があります。
BigQuery のスケジューリング・クエリに相当する機能で、日別の集計テーブルを作成したり、NULL値を除外した別テーブルを作成するなどの用途でご利用いただいています。

今回、BigQuery、Redshift に加え、Snowflake を新たにサポートしました。
最近は、DWHとして Snowflake を選ばれるお客様も増えています。
データマート機能はRails上に実装されており、Snowflake API を叩いてクエリ実行を行っています。
Snowflake API は最近一般公開されたこともあり、各種エラーハンドリングやお客様の要件に耐えるだけのデータ量を処理できるかなどの検証を行い、リリースしました。
この機能は、副業で入っていただいているRailsエンジニアの方を中心に開発を進めていただきました。
trocco® では、副業エンジニアの方々も多く活躍頂いています。すぐの転職は検討していないけど、まずは副業から始めてみたい方など、是非ご応募下さい!
リリース機能 3: 「データカタログ」
分析者が DWH 上のデータをより楽に分析できるように、様々なメタデータの可視化を行うデータカタログ機能を開発しています。
例えば、trocco® で MySQLのデータを BigQuery に転送している場合、BigQuery のテーブル・カラムが MySQL のどのカラムから転送されたデータなのかを trocco® 上で確認することが出来ます。
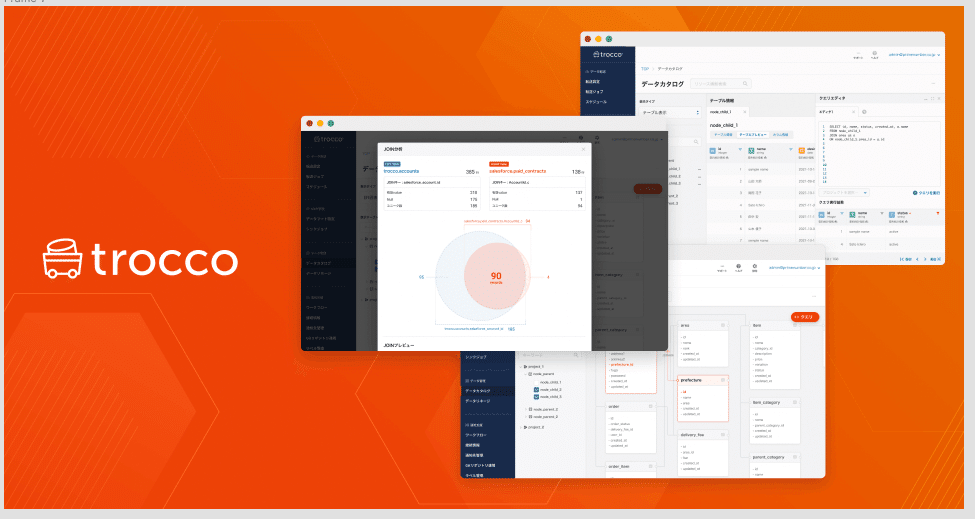
お客様のフィードバックを元に、直近数ヶ月で様々なアップデートを行っています。
▼リリース機能例
メタデータ抽出対象のコネクタの拡充
Google Analytics
Google広告
Yahoo!検索広告
kintone
PostgreSQL
ユーザーが自由にメタデータを定義できる機能
データカタログは、リードエンジニアの中根さん、新卒2年目の上原さん、プロダクトオーナー小林さん、デザイナー飯田さんの4人体制で開発を進めています。
データカタログはデファクトが無い領域です。実際のお客様の声をいただきつつ、自分たちがデファクトになれるように開発を進めています。
現在取り組んでいること: 「グループ機能の改善」
trocco® では現在様々な機能を開発中ですが、一例として「グループ機能の改善」プロジェクトを紹介します。
グループ機能は、データパイプラインの設定や、DWH の設定を企業内の特定のユーザー同士で共有する機能で、多くのお客様にご利用いただいています。
比較的シンプルな機能でしたが、trocco® が様々なお客様にご利用いただくにつれて、より細かい権限管理などのご要望を多くいただくようになったため、現在改修を進めています。
大きめの改修の場合、エンジニア、プロダクトオーナー、デザイナーでチームを組み、顧客ヒアリングを通して機能アイデアを絞り込んでいくような進め方をすることが多いです。
今回のグループ機能の改善も同様に、実際にお客様へのヒアリングを通して開発を進めています。

正解の無い中で、現状の技術的な制約などと照らし合わせながら最適案を探り、プロジェクトを進めていく事は、非常に難易度が高いことです。
trocco® では、高いエンジニア力や、物事を整理して周りと調整しながら前に進める能力が必要な機能開発が山程あります。そういったことにやりがいを感じるエンジニアの方には、おすすめの環境です。
この機能は、2022/03に入社したシニアエンジニアの岡さん(紹介記事準備中)、プロダクトオーナーの小林さん、デザイナーの飯田さんで開発を進めています。
3名のエンジニアが入社しました🎉
2022/03に2名、2022/04に1名のエンジニアが入社しました!
また、2022/07 頃にSRE エンジニア2名の入社を予定しています。
エンジニアを募集しています
trocco® を一緒に伸ばしていっていただけるエンジニアを絶賛募集中です。伸びしろしか無い、面白いプロダクトだと自負しています。
データエンジニアリングの経験は問いません(私も含め、現メンバーもほとんどがデータエンジニアリング未経験でジョインしています)。
この記事を読んで、少しでも興味を持っていただけましたら、是非カジュアル面談でお話させて下さい!
primeNumber: 会社紹介
現在募集中のエンジニア職種
もちろん、カジュアル面談からでもOKです!
その他、エンジニア以外の職種も絶賛募集中です
この記事が気に入ったらサポートをしてみませんか?