
機械学習モデルで「Pokémon LEGENDS Z-A」の「メガシンカ」予測してみた。

こんばんは。
「Z-A」は「過去派」です。
今回、ポケモンの新作として、「Pokémon LEGENDS Z-A」が発売されることが決まったということで、舞台のカロス地方(当作品での呼び方はまだ不明)と関係の深い、追加の「メガシンカ」を機械学習モデルで予測してみたいと思います。
※注意:あくまで予想を楽しむための取り組みですので、ご理解ください。また、データ分析やプログラミングに関する知識等については勉強中ですので、手法等に間違いがある可能性があります。
■背景
今回の新作が6世代をテーマとしている「LEGENDS」第2作目ということで、本編では6世代以降、毎世代でバトルに大きな影響を与える追加要素があったと思います。
・6世代(XY,ORAS):メガシンカ
・7世代(SM,USUM):Zワザ
・8世代(剣盾):ダイマックス,キョダイマックス
・9世代(SV):テラスタル
先日(2024年2月27日)のPokémon Dayで公開された映像では、メガシンカのロゴも登場しており、Z-Aでも必ず関係してくると考えられます。
そこで、既存のキャラクターから「追加のメガシンカが来るのではないか」という視点に立ち、それがどのポケモンなのかをAIに予測してもらおうと思います。
■使用データ
Kaggleデータセット「The Complete Pokemon Dataset」
※Kaggleとは、データサイエンティストたちが利用するプラットフォームで、データ分析のコンペティション(大会)や公開データなどがあります。
データ内容
・レコード数:801(1世代~7世代:フシギダネ~マギアナ、フォルム違いによる複数レコードは無)
・カラム(項目)※加工後:

もとのデータでは伝説ポケモンかどうかを予測することを想定して用意されているデータセットのようなので、今回の目的とは正例の割合が近いと思いそのまま採用することにしました。
他に予測に影響を与えそうな項目として、進化段階、リージョンフォームの有無など追加フォルム・要素があったかどうかを追加してみました。
■予測の条件
⓪使用ツール
・プログラミング言語は「Python」を使用し、環境は「Visual Studio Code」を使用しています。
・ライブラリについては、numpy、pandas、matplotlib、seaborn、sklearnなどの基本的なものを使用しています。
①trainとtestの分け方
機械学習モデルの構築には、モデルが予測を行うための知識を学習させる「学習データ:train」と予測を行うための「テストデータ:test」を用意する必要があります。
今回は、「LEGENDS」第1作目の「Pokémon LEGENDS アルセウス」(以降、LAと略)の登場ポケモンを参考にしてデータを分けたいと思います。
まず、ダイヤモンド・パール(以降、DPと略)とLAの図鑑を比較しどの程度違いがあるか確認しました。

確認してみると、追加されたポケモンは追加進化・リージョンフォーム等を除くと、パラス族、タマザラシ族が純粋に追加されたポケモンでした。
一方で、除外されたポケモンは、ポケモン数19、族数で8でした。こちらは特定の法則性を見ることはできませんが、強いて言えば、ホウエン地方で登場するポケモンが多いということでしょうか。これについてはDPtとの関連性はあまりないので、今回の線引きには応用できなさそうです。
つまるところ、基本的にはDPtのシンオウ図鑑登録のポケモンとLAのヒスイ図鑑登録のポケモンとでは、母数に対する大きな差異はないと考え、今回のテストデータはXYのカロス図鑑(セントラルカロス図鑑、コーストカロス図鑑、マウンテンカロス図鑑)をベースにしたいと思います。
・train:test以外のレコード。レコード数418。
・test:すでにメガシンカが確認されている族を除いたカロス図鑑登録のポケモンのレコード。レコード数383。
②複数フォルムのあるポケモンの扱い
今回は、1ポケモン1レコードとします。そのため、複数フォルムのあるポケモンについては、最もベーシックと考えられるフォルムの情報を採用します。
例)ナッシー:通常のすがた、ミノマダム:くさきのミノ
③追加ポケモンの想定
LA同様に今回も御三家の入れ替え、リージョンフォームの追加等が考えられ、カロス図鑑には登録されていないポケモンが追加されることが想定されます。しかし、リージョンフォーム等に関する法則性を特定することは難しいので、今回はそれらの想定は一切考慮せず、既存ポケモンのみをメガシンカ可能性の対象として考えます。
■データの可視化
まずは、trainデータのメガシンカの数を確認します。

メガシンカ可能なポケモンはtrainデータ内で1割程度と見て取れます。
(x軸の数値がメガシンカ可能種類の数を表しています。)
次に、trainデータとtestデータの均衡を確認します。



世代については、6・7世代に大きく偏りがありますが、それ以外は大きく偏っているというほどではなさそうです。
進化系・最終形態に関してはおおむね均衡がとれているように見えます。
次に、メガシンカと各指標の関係性を見てみます。


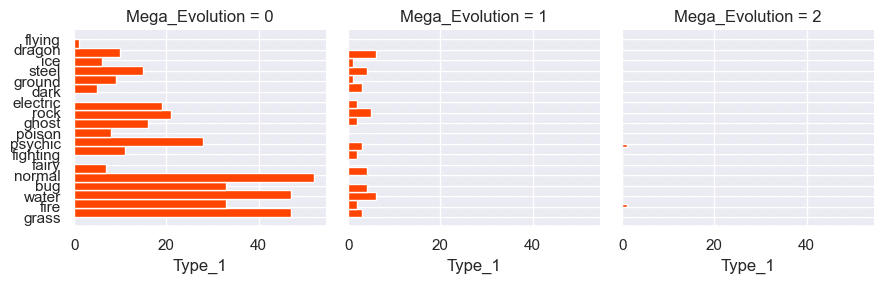

・世代については、当然ながら6世代までのポケモンにメガシンカが確認できます。とはいえ5・6世代にはほとんどメガシンカはいません。モデル上では、この情報は寄与しそうな気がします。
・種族値合計については、600族周辺に集まっているようです。
・タイプについては、この可視化ではあまり特徴的なことは言えなさそうです。深掘りの甲斐はありそうですが、今回は一旦そのままにしておきます。
・メガシンカ以外の追加要素については、傾向を見ようにもデータが少ない印象です(他で追加要素が来ていないポケモンが優遇されると読んでの可視化でしたが微妙だったとように思いました)。
■データの加工
機械学習で予測を行うには、基本的にデータの中身はすべて数値で構成されている必要があります。そのため文字列データ(分類、特性など)については数値に置き換える作業を行います。
①カウントエンコーティング
※カウントエンコーティングとは:文字列について、データ全体での出現回数に置き換える加工方法。
・分類(○○ポケモン)

・特性
特性は3列に分かれているので、3列を合わせて出現回数を計算します。

②ラベルエンコーティング
※ラベルエンコーティングとは:1種類ずつに別の数値を割り当てる加工方法。
・同族(同じ進化系列ごとに、たねポケモンの名前が格納されている)
左右差・上下差がないため、One-Hotエンコーティングの方がふさわしいかもしれませんが、カラム数が多くなることを防ぐために今回はラベルエンコーティングにしました。
※One-Hotエンコーティングとは:「0」か「1」で表現する(True or False)加工方法。
■特徴量の選択
今回は以下を特徴量として選択しました。

削除したのは、主にはタイプに関する情報(タイプ、タイプ相性)です。理由としては、単にカラムの割合が最も多かったためです。試しに全カラムでランダムフォレストを回してみてもこの後の結果と大差がなかったため、今回は削除しました。
参考までに、ヒートマップとVIFを可視化しておきます。

■予測モデルの構築と評価
今回は複数のアルゴリズムを使用し、1つ以上の予測結果があったものを載せておきます。

ここでは、5つのモデルの精度と寄与度をみておきます。
※見方としては、モデルスコア・交差検証については最小が0、最大が1の範囲でモデルの精度をスコアリングしています。寄与度についても精度と基本的には同じですが、ロジスティクス回帰については範囲を-1から1までとり、絶対値が1に近いほど寄与が大きく、0に近いほど寄与が小さいと考えます。
・精度としては、交差検証を行うことで低い結果となっていたり、すべての結果が異様に高く信頼できるか不確かであったりといった印象です。
・寄与度については、バトルへの影響が少ない基本情報(緑)やバトルへの影響が最も大きい能力値の情報(黄)が多く寄与している傾向が見られました。
モデルの精度はいまいちですが、とりあえず早く結果が見たいので、今回はこれで切り上げます。
■予測結果(メガシンカするポケモン)
お待たせしました。それでは、機械学習モデルによって予測されたメガシンカするポケモンを発表します。
今回、モデルを5つ用意したので、モデル別に結果を見てみたいと思います。
それではどうぞ。




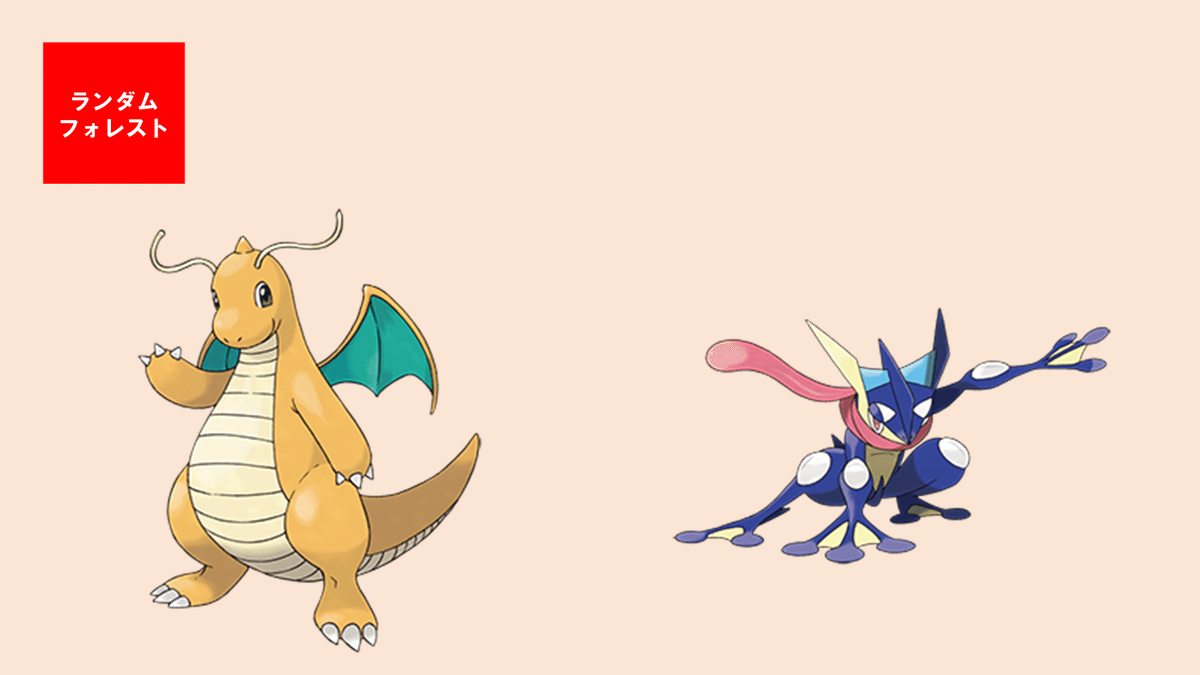
それぞれ、なかなか面白い結果になったのではないでしょうか。
・ロジスティクス回帰は、並列の進化先が両方含まれている点で面白いと感じました。
・KNNは、中でも世代のばらけ方がきれいで現実味があるように感じました。特に、ジョウトとイッシュのポケモンのチョイスが熱いですね。
・ナイーブ・ベイズは、最も予測数が多く、内容もこの中ではいちばんみんなが喜ぶような組み合わせなのではないでしょうか。ついに、ブイズにも動きがあるかもしれませんね。
・決定木は、後半の世代でなかなか渋い予測をしていると感じました。今回の作品では重要な役割が期待されるフラエッテを押さえている点はポイントが高いですね。
・ランダムフォレストは、、、そう言われたらそうかもしれない…。
■予測結果を受けての考察
5つのモデルの結果を見てもらうとわかる通り、カイリューがめっちゃいます。(笑)
特徴量から考えられる要因としては、寄与度から考えても600族であることが大きく起因していると考えられます。
他の結果についても基本的には種族値をベースに予測していそうです。
ちなみに、予測への貢献を期待していた追加要素関連ですが、予測結果を見てもあまり影響していないことがわかります(ランダムフォレストは逆に影響しすぎたか?)。
今回は、タイプに関する特徴量は使いませんでしたが、タイプに関する特徴量も加えて結果を見てみたいですね。
また、ランクバトルでの使用率や人気ランキングなどの指標も採用するとより面白い結果が得られるかもしれません。
さらに、8世代以降のデータも追加すれば、内定ポケモン・追加ポケモン・追加リージョンなどの予測も行えるかもしれませんので、興味がある方はぜひコメントください。
■最後に
今回は、勉強の息抜き程度の気持ちで取り組んだので、かなり雑な分析になってしまったように思います。
ここまでご覧いただいた方の中に、デー分析に精通している方がいらっしゃれば、ぜひご意見をいただきたく思います。
最後までご覧いただき、ありがとうございました。
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?