
第11章:ランダムフォレスト - ロングショート戦略 第3節: ランダム木をチューニング

はじめに
この記事では、ランダムフォレストの分類モデルと回帰モデルの両方に対して、モデルの最適化のやり方、特徴量の重要度の比較をやっていきたいと思います。
インポートと設定
import warnings
warnings.filterwarnings('ignore')%matplotlib inline
import os, sys
import numpy as np
from numpy.random import choice
import pandas as pd
from scipy.stats import spearmanr
from sklearn.ensemble import RandomForestRegressor, RandomForestClassifier
from sklearn.model_selection import GridSearchCV, cross_val_score
from sklearn.metrics import make_scorer
import joblib
import matplotlib.pyplot as plt
import seaborn as sns
from pathlib import Pathsys.path.insert(1, os.path.join(sys.path[0], '..'))
from utils import MultipleTimeSeriesCVsns.set_style('white')
np.random.seed(seed=42)results_path = Path('results', 'random_forest')
if not results_path.exists():
results_path.mkdir(parents=True)データ取得
with pd.HDFStore('data.h5') as store:
data =store['us/equities/monthly']
data.info()
'''
<class 'pandas.core.frame.DataFrame'>
MultiIndex: 56756 entries, ('A', Timestamp('2010-12-31 00:00:00')) to ('ZION', Timestamp('2017-11-30 00:00:00'))
Data columns (total 27 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 atr 56756 non-null float64
1 bb_down 56756 non-null float64
2 bb_high 56756 non-null float64
3 bb_low 56756 non-null float64
4 bb_mid 56756 non-null float64
5 bb_up 56756 non-null float64
6 macd 56756 non-null float64
7 natr 56756 non-null float64
8 rsi 56756 non-null float64
9 sector 56756 non-null object
10 return_1m 56756 non-null float64
11 return_3m 56756 non-null float64
12 return_6m 56756 non-null float64
13 return_12m 56756 non-null float64
14 beta 56756 non-null float64
15 SMB 56756 non-null float64
16 HML 56756 non-null float64
17 RMW 56756 non-null float64
18 CMA 56756 non-null float64
19 momentum_3 56756 non-null float64
20 momentum_6 56756 non-null float64
21 momentum_3_6 56756 non-null float64
22 momentum_12 56756 non-null float64
23 momentum_3_12 56756 non-null float64
24 year 56756 non-null int64
25 month 56756 non-null int64
26 target 56756 non-null float64
dtypes: float64(24), int64(2), object(1)
memory usage: 12.0+ MB
'''y = data.target
y_binary = (y > 0).astype(int)
X = pd.get_dummies(data.drop('target', axis=1))ランダムフォレスト
交差検定パラメーター
n_splits = 10
train_period_length = 60
test_period_length = 6
lookahead = 1
cv = MultipleTimeSeriesCV(n_splits=n_splits,
train_period_length=train_period_length,
test_period_length=test_period_length,
lookahead=lookahead)分類器
rf_clf = RandomForestClassifier(n_estimators=100, # default changed from 10 to 100 in version 0.22
criterion='gini',
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_features='auto',
max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_impurity_split=None,
bootstrap=True,
oob_score=True,
n_jobs=-1,
random_state=42,
verbose=1)交差検定のデフォルト設定
cv_score = cross_val_score(estimator=rf_clf,
X=X,
y=y_binary,
scoring='roc_auc',
cv=cv,
n_jobs=-1,
verbose=1)np.mean(cv_score)
'''
0.5236992279415401
'''回帰
def rank_correl(y, y_pred):
return spearmanr(y, y_pred)[0]
ic = make_scorer(rank_correl)rf_reg = RandomForestRegressor(n_estimators=100,
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_features='auto',
max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_impurity_split=None,
bootstrap=True,
oob_score=False,
n_jobs=-1,
random_state=None,
verbose=0,
warm_start=False)cv_score = cross_val_score(estimator=rf_reg,
X=X,
y=y,
scoring=ic,
cv=cv,
n_jobs=-1,
verbose=1)np.mean(cv_score)
'''
0.02360557172927478
'''パラメーターグリッド
param_grid = {'n_estimators': [50, 100, 250],
'max_depth': [5, 15, None],
'min_samples_leaf': [5, 25, 100]}GridSearchCVのインスタンス
gridsearch_clf = GridSearchCV(estimator=rf_clf,
param_grid=param_grid,
scoring='roc_auc',
n_jobs=-1,
cv=cv,
refit=True,
return_train_score=True,
verbose=1)フィッティング
gridsearch_clf.fit(X=X, y=y_binary)
'''
Fitting 10 folds for each of 27 candidates, totalling 270 fits
[Parallel(n_jobs=-1)]: Done 42 tasks | elapsed: 43.6s
[Parallel(n_jobs=-1)]: Done 192 tasks | elapsed: 5.5min
[Parallel(n_jobs=-1)]: Done 270 out of 270 | elapsed: 8.8min finished
[Parallel(n_jobs=-1)]: Using backend ThreadingBackend with 4 concurrent workers.
[Parallel(n_jobs=-1)]: Done 42 tasks | elapsed: 2.5s
[Parallel(n_jobs=-1)]: Done 192 tasks | elapsed: 10.9s
[Parallel(n_jobs=-1)]: Done 250 out of 250 | elapsed: 14.2s finished
GridSearchCV(cv=<utils.MultipleTimeSeriesCV object at 0x7fbf99d90dd0>,
estimator=RandomForestClassifier(n_jobs=-1, oob_score=True,
random_state=42, verbose=1),
n_jobs=-1,
param_grid={'max_depth': [5, 15, None],
'min_samples_leaf': [5, 25, 100],
'n_estimators': [50, 100, 250]},
return_train_score=True, scoring='roc_auc', verbose=1)
'''結果の保存
joblib.dump(gridsearch_clf, results_path / 'gridsearch_clf.joblib') gridsearch_clf = joblib.load(results_path / 'gridsearch_clf.joblib') gridsearch_clf.best_params_
'''
{'max_depth': None, 'min_samples_leaf': 5, 'n_estimators': 250}
'''gridsearch_clf.best_score_
'''
0.5208670763661614
'''特徴量の重要度
fig, ax = plt.subplots(figsize=(12,5))
(pd.Series(gridsearch_clf.best_estimator_.feature_importances_,
index=X.columns)
.sort_values(ascending=False)
.iloc[:20]
.sort_values()
.plot.barh(ax=ax, title='RF Feature Importance'))
sns.despine()
fig.tight_layout();
回帰バージョン
gridsearch_reg = GridSearchCV(estimator=rf_reg,
param_grid=param_grid,
scoring=ic,
n_jobs=-1,
cv=cv,
refit=True,
return_train_score=True,
verbose=1)gs_reg = gridsearch_reggridsearch_reg.fit(X=X, y=y)
'''
Fitting 10 folds for each of 27 candidates, totalling 270 fits
[Parallel(n_jobs=-1)]: Using backend LokyBackend with 4 concurrent workers.
[Parallel(n_jobs=-1)]: Done 42 tasks | elapsed: 3.2min
[Parallel(n_jobs=-1)]: Done 192 tasks | elapsed: 24.6min
[Parallel(n_jobs=-1)]: Done 270 out of 270 | elapsed: 39.6min finished
GridSearchCV(cv=<utils.MultipleTimeSeriesCV object at 0x7fbf99d90dd0>,
estimator=RandomForestRegressor(n_jobs=-1), n_jobs=-1,
param_grid={'max_depth': [5, 15, None],
'min_samples_leaf': [5, 25, 100],
'n_estimators': [50, 100, 250]},
return_train_score=True, scoring=make_scorer(rank_correl),
verbose=1)
'''結果の保存
joblib.dump(gridsearch_reg, results_path / 'rf_reg_gridsearch.joblib') gridsearch_reg = joblib.load(results_path / 'rf_reg_gridsearch.joblib') gridsearch_reg.best_params_
'''
{'max_depth': 5, 'min_samples_leaf': 5, 'n_estimators': 100}
'''f'{gridsearch_reg.best_score_*100:.2f}'
'''
'4.81'
'''結果の比較
最適パラメーター
pd.DataFrame({'Regression': pd.Series(gridsearch_reg.best_params_),
'Classification': pd.Series(gridsearch_clf.best_params_)})
特徴量の重要度
fi_clf = gridsearch_clf.best_estimator_.feature_importances_
fi_reg = gridsearch_reg.best_estimator_.feature_importances_idx = [c.replace('_', ' ').upper() for c in X.columns]fig, axes = plt.subplots(figsize=(14, 4), ncols=2)
(pd.Series(fi_clf, index=idx)
.sort_values(ascending=False)
.iloc[:15]
.sort_values()
.plot.barh(ax=axes[1], title='Classifier'))
(pd.Series(fi_reg, index=idx)
.sort_values(ascending=False)
.iloc[:15]
.sort_values()
.plot.barh(ax=axes[0], title='Regression'))
sns.despine()
fig.tight_layout()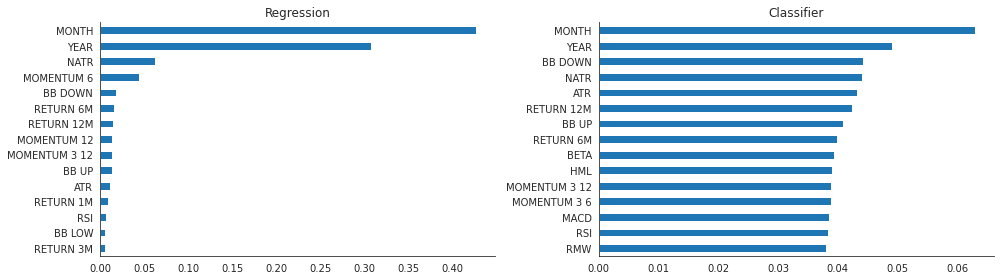
この記事が気に入ったらサポートをしてみませんか?