
第7章 線形モデル編: 第3節 モデルデータの準備

こんにちは、今回は主にデータの処理についての話ですので、初めての方々には参考になると思います(*'ω'*)
今回準備するデータは株価を予測するためのアルファファクターと特徴量になります。
インポートと設定
import warnings
warnings.filterwarnings('ignore')%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.stats import pearsonr
from talib import RSI, BBANDS, MACD, ATRMONTH = 21
YEAR = 12 * MONTHSTART = '2013-01-01'
END = '2017-12-31'sns.set_style('whitegrid')
idx = pd.IndexSliceQuandl Wiki 株価 & メタデータを読み込む
データの取得方法は初めての方はこちらをご参照ください。
DATA_STORE = '../data/assets.h5'
ohlcv = ['adj_open', 'adj_close', 'adj_low', 'adj_high', 'adj_volume']
with pd.HDFStore(DATA_STORE) as store:
prices = (store['quandl/wiki/prices']
.loc[idx[START:END, :], ohlcv]
.rename(columns=lambda x: x.replace('adj_', ''))
.swaplevel()
.sort_index())
prices.volume /= 1e3
stocks = (store['us_equities/stocks']
.loc[:, ['marketcap', 'ipoyear', 'sector']])
OHLCVのデータセットになります。
観測値が少ないデータを取り除く
min_obs = 2 * YEAR
nobs = prices.groupby(level='ticker').size()
keep = nobs[nobs > min_obs].index
prices = prices.loc[idx[keep, :], :]こちらでは最低でも二年分のデータが取得出来れば使用することにします。
価格とメタデータを揃える
stocks = stocks[~stocks.index.duplicated() & stocks.sector.notnull()]
stocks.sector = stocks.sector.str.lower().str.replace(' ', '_')
stocks.index.name = 'ticker'こちらのstocksではticker(銘柄コード)がインデックスで、カラムが時価総額、上場年、セクターになります。
shared = (prices.index.get_level_values('ticker').unique()
.intersection(stocks.index))
stocks = stocks.loc[shared, :]
prices = prices.loc[idx[shared, :], :]次にpricesの中にあるティッカーとstocksのティッカーの共通部分を取ります。
prices.info(null_counts=True)
'''
<class 'pandas.core.frame.DataFrame'>
MultiIndex: 2904233 entries, ('A', Timestamp('2013-01-02 00:00:00')) to ('ZUMZ', Timestamp('2017-12-29 00:00:00'))
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 open 2904233 non-null float64
1 close 2904233 non-null float64
2 low 2904233 non-null float64
3 high 2904233 non-null float64
4 volume 2904233 non-null float64
dtypes: float64(5)
memory usage: 122.0+ MB
'''stocks.info()
'''
<class 'pandas.core.frame.DataFrame'>
Index: 2348 entries, A to ZUMZ
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 marketcap 2345 non-null float64
1 ipoyear 1026 non-null float64
2 sector 2348 non-null object
dtypes: float64(2), object(1)
memory usage: 73.4+ KB
'''stocks.sector.value_counts()
'''
consumer_services 440
finance 393
health_care 297
technology 297
capital_goods 227
basic_industries 138
consumer_non-durables 126
energy 123
public_utilities 105
consumer_durables 78
miscellaneous 69
transportation 55
Name: sector, dtype: int64
'''ここから特徴量を突っ込んでいきます。
ローリング平均ドル出来高を計算
# compute dollar volume to determine universe
prices['dollar_vol'] = prices.loc[:, 'close'].mul(prices.loc[:, 'volume'], axis=0)
prices['dollar_vol'] = (prices
.groupby('ticker',
group_keys=False,
as_index=False)
.dollar_vol
.rolling(window=21)
.mean()
.fillna(0)
.reset_index(level=0, drop=True))
prices.dollar_vol /= 1e3prices['dollar_vol_rank'] = (prices
.groupby('date')
.dollar_vol
.rank(ascending=False))他の基本ファクターを追加
RSI
prices['rsi'] = prices.groupby(level='ticker').close.apply(RSI)ax = sns.distplot(prices.rsi.dropna())
ax.axvline(30, ls='--', lw=1, c='k')
ax.axvline(70, ls='--', lw=1, c='k')
ax.set_title('RSI Distribution with Signal Threshold')
plt.tight_layout();
ボリンジャーバンド
def compute_bb(close):
high, mid, low = BBANDS(close, timeperiod=20)
return pd.DataFrame({'bb_high': high, 'bb_low': low}, index=close.index)prices = (prices.join(prices
.groupby(level='ticker')
.close
.apply(compute_bb)))prices['bb_high'] = prices.bb_high.sub(prices.close).div(prices.bb_high).apply(np.log1p)
prices['bb_low'] = prices.close.sub(prices.bb_low).div(prices.close).apply(np.log1p)fig, axes = plt.subplots(ncols=2, figsize=(15, 5))
sns.distplot(prices.loc[prices.dollar_vol_rank<100, 'bb_low'].dropna(), ax=axes[0])
sns.distplot(prices.loc[prices.dollar_vol_rank<100, 'bb_high'].dropna(), ax=axes[1])
plt.tight_layout();fig, axes = plt.subplots(ncols=2, figsize=(15, 5))
sns.distplot(prices.loc[prices.dollar_vol_rank<100, 'bb_low'].dropna(), ax=axes[0])
sns.distplot(prices.loc[prices.dollar_vol_rank<100, 'bb_high'].dropna(), ax=axes[1])
plt.tight_layout();
ATR
def compute_atr(stock_data):
df = ATR(stock_data.high, stock_data.low,
stock_data.close, timeperiod=14)
return df.sub(df.mean()).div(df.std())prices['atr'] = (prices.groupby('ticker', group_keys=False)
.apply(compute_atr))sns.distplot(prices[prices.dollar_vol_rank<50].atr.dropna());
移動平均コンバージェンス/ダイバージェンス(MACD)
def compute_macd(close):
macd = MACD(close)[0]
return (macd - np.mean(macd))/np.std(macd)prices['macd'] = (prices
.groupby('ticker', group_keys=False)
.close
.apply(compute_macd))prices.macd.describe(percentiles=[.001, .01, .02, .03, .04, .05, .95, .96, .97, .98, .99, .999]).apply(lambda x: f'{x:,.1f}')sns.distplot(prices[prices.dollar_vol_rank<100].macd.dropna());
ラグリターン
lags = [1, 5, 10, 21, 42, 63]returns = prices.groupby(level='ticker').close.pct_change()
percentiles=[.0001, .001, .01]
percentiles+= [1-p for p in percentiles]
returns.describe(percentiles=percentiles).iloc[2:].to_frame('percentiles').style.format(lambda x: f'{x:,.2%}')異常値をウィンソライズする
q = 0.0001for lag in lags:
prices[f'return_{lag}d'] = (prices.groupby(level='ticker').close
.pct_change(lag)
.pipe(lambda x: x.clip(lower=x.quantile(q),
upper=x.quantile(1 - q)))
.add(1)
.pow(1 / lag)
.sub(1)
)シフトする
for t in [1, 2, 3, 4, 5]:
for lag in [1, 5, 10, 21]:
prices[f'return_{lag}d_lag{t}'] = (prices.groupby(level='ticker')
[f'return_{lag}d'].shift(t * lag))フォワードリターン
for t in [1, 5, 10, 21]:
prices[f'target_{t}d'] = prices.groupby(level='ticker')[f'return_{t}d'].shift(-t)価格データとメタデータを結合
prices = prices.join(stocks[['sector']])時刻とセクターのダミー変数作成
prices['year'] = prices.index.get_level_values('date').year
prices['month'] = prices.index.get_level_values('date').monthprices.info(null_counts=True)
'''
<class 'pandas.core.frame.DataFrame'>
MultiIndex: 2904233 entries, ('A', Timestamp('2013-01-02 00:00:00')) to ('ZUMZ', Timestamp('2017-12-29 00:00:00'))
Data columns (total 45 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 open 2904233 non-null float64
1 close 2904233 non-null float64
2 low 2904233 non-null float64
3 high 2904233 non-null float64
4 volume 2904233 non-null float64
5 dollar_vol 2904233 non-null float64
6 dollar_vol_rank 2904233 non-null float64
7 rsi 2871361 non-null float64
8 bb_high 2859618 non-null float64
9 bb_low 2859585 non-null float64
10 atr 2871361 non-null float64
11 macd 2826749 non-null float64
12 return_1d 2901885 non-null float64
13 return_5d 2892493 non-null float64
14 return_10d 2880753 non-null float64
15 return_21d 2854925 non-null float64
16 return_42d 2805617 non-null float64
17 return_63d 2756309 non-null float64
18 return_1d_lag1 2899537 non-null float64
19 return_5d_lag1 2880753 non-null float64
20 return_10d_lag1 2857273 non-null float64
21 return_21d_lag1 2805617 non-null float64
22 return_1d_lag2 2897189 non-null float64
23 return_5d_lag2 2869013 non-null float64
24 return_10d_lag2 2833793 non-null float64
25 return_21d_lag2 2756309 non-null float64
26 return_1d_lag3 2894841 non-null float64
27 return_5d_lag3 2857273 non-null float64
28 return_10d_lag3 2810313 non-null float64
29 return_21d_lag3 2707001 non-null float64
30 return_1d_lag4 2892493 non-null float64
31 return_5d_lag4 2845533 non-null float64
32 return_10d_lag4 2786833 non-null float64
33 return_21d_lag4 2657693 non-null float64
34 return_1d_lag5 2890145 non-null float64
35 return_5d_lag5 2833793 non-null float64
36 return_10d_lag5 2763353 non-null float64
37 return_21d_lag5 2608385 non-null float64
38 target_1d 2901885 non-null float64
39 target_5d 2892493 non-null float64
40 target_10d 2880753 non-null float64
41 target_21d 2854925 non-null float64
42 sector 2904233 non-null object
43 year 2904233 non-null int64
44 month 2904233 non-null int64
dtypes: float64(42), int64(2), object(1)
memory usage: 1.1+ GB
'''データの保存
prices.assign(sector=pd.factorize(prices.sector, sort=True)[0]).to_hdf('data.h5', 'model_data/no_dummies')prices.to_hdf('data.h5', 'model_data')データを探求する。
target = 'target_5d'
top100 = prices[prices.dollar_vol_rank<100].copy()RSI
top100.loc[:, 'rsi_signal'] = pd.cut(top100.rsi, bins=[0, 30, 70, 100])ボリンジャーバンド
j=sns.jointplot(x=top100.bb_low, y=target, data=top100)
j.annotate(pearsonr);
j=sns.jointplot(x='bb_high', y=target, data=top100)
j.annotate(pearsonr);
ATR
j=sns.jointplot(x='atr', y=target, data=top100)
j.annotate(pearsonr);
MACD
j=sns.jointplot(x='macd', y=target, data=top100)
j.annotate(pearsonr);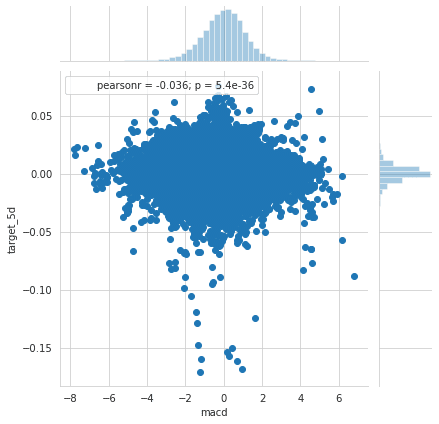
この記事が気に入ったらサポートをしてみませんか?