
第12章:戦略をブースティングする 第3節: sklearn gbm チューニング結果

前回第2節で行ったチューニングの結果について分析していきます。
インポートと設定
import warnings
warnings.filterwarnings('ignore')%matplotlib inline
from pathlib import Path
import os
from datetime import datetime
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import graphviz
from statsmodels.api import OLS, add_constant
from sklearn.tree import DecisionTreeRegressor, export_graphviz
from sklearn.metrics import roc_auc_score
import joblibsns.set_style("white")
np.random.seed(42)
pd.options.display.float_format = '{:,.4f}'.formatwith pd.HDFStore('data/tuning_sklearn_gbm.h5') as store:
test_feature_data = store['holdout/features']
test_features = test_feature_data.columns
test_target = store['holdout/target']sklearnでGBM GridsearchCV
class OneStepTimeSeriesSplit:
passこれはGridSearchCVの保存結果が想定しているため。
計算結果の読み込み
gridsearch_result = joblib.load('results/sklearn_gbm_gridsearch.joblib')最適パラメーター&AUCスコア
pd.Series(gridsearch_result.best_params_)
'''
learning_rate 0.0100
max_depth 9.0000
max_features 1.0000
min_impurity_decrease 0.0100
min_samples_split 50.0000
n_estimators 300.0000
subsample 1.0000
dtype: float64
''''{:.4f}'.format(gridsearch_result.best_score_)
'''
'0.5569'
'''最適モデルの評価
ホールドアウトセット上でテスト
best_model = gridsearch_result.best_estimator_idx = pd.IndexSlice
test_dates = sorted(test_feature_data.index.get_level_values('date').unique())auc = {}
for i, test_date in enumerate(test_dates):
test_data = test_feature_data.loc[idx[:, test_date], :]
preds = best_model.predict(test_data)
auc[i] = roc_auc_score(y_true=test_target.loc[test_data.index], y_score=preds)auc = pd.Series(auc)auc.head()
'''
0 0.5134
1 0.5195
2 0.5111
3 0.5014
4 0.5046
dtype: float64
'''ax = auc.sort_index(ascending=False).plot.barh(xlim=(.45, .55),
title='Test AUC: {:.2%}'.format(auc.mean()),
figsize=(8, 4))
ax.axvline(auc.mean(), ls='--', lw=1, c='k')
sns.despine()
plt.tight_layout()
グローバル特徴量重要度の調査
(pd.Series(best_model.feature_importances_,
index=test_features)
.sort_values()
.tail(25)
.plot.barh(figsize=(8, 5)))
sns.despine()
plt.tight_layout()
results = pd.DataFrame(gridsearch_result.cv_results_).drop('params', axis=1)
results.info()
'''
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 576 entries, 0 to 575
Data columns (total 40 columns):
mean_fit_time 576 non-null float64
mean_score_time 576 non-null float64
mean_test_score 576 non-null float64
mean_train_score 576 non-null float64
param_learning_rate 576 non-null object
param_max_depth 576 non-null object
param_max_features 576 non-null object
param_min_impurity_decrease 576 non-null object
param_min_samples_split 576 non-null object
param_n_estimators 576 non-null object
param_subsample 576 non-null object
rank_test_score 576 non-null int32
split0_test_score 576 non-null float64
split0_train_score 576 non-null float64
split10_test_score 576 non-null float64
split10_train_score 576 non-null float64
split11_test_score 576 non-null float64
split11_train_score 576 non-null float64
split1_test_score 576 non-null float64
split1_train_score 576 non-null float64
split2_test_score 576 non-null float64
split2_train_score 576 non-null float64
split3_test_score 576 non-null float64
split3_train_score 576 non-null float64
split4_test_score 576 non-null float64
split4_train_score 576 non-null float64
split5_test_score 576 non-null float64
split5_train_score 576 non-null float64
split6_test_score 576 non-null float64
split6_train_score 576 non-null float64
split7_test_score 576 non-null float64
split7_train_score 576 non-null float64
split8_test_score 576 non-null float64
split8_train_score 576 non-null float64
split9_test_score 576 non-null float64
split9_train_score 576 non-null float64
std_fit_time 576 non-null float64
std_score_time 576 non-null float64
std_test_score 576 non-null float64
std_train_score 576 non-null float64
dtypes: float64(32), int32(1), object(7)
memory usage: 177.8+ KB
'''パラメーターの値と平均検定スコアの取得
test_scores = results.filter(like='param').join(results[['mean_test_score']])
test_scores = test_scores.rename(columns={c: '_'.join(c.split('_')[1:]) for c in test_scores.columns})
test_scores.info()
'''
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 576 entries, 0 to 575
Data columns (total 8 columns):
learning_rate 576 non-null object
max_depth 576 non-null object
max_features 576 non-null object
min_impurity_decrease 576 non-null object
min_samples_split 576 non-null object
n_estimators 576 non-null object
subsample 576 non-null object
test_score 576 non-null float64
dtypes: float64(1), object(7)
memory usage: 36.1+ KB
'''params = test_scores.columns[:-1].tolist()test_scores = test_scores.set_index('test_score').stack().reset_index()
test_scores.columns= ['test_score', 'parameter', 'value']test_scores.info()
'''
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4032 entries, 0 to 4031
Data columns (total 3 columns):
test_score 4032 non-null float64
parameter 4032 non-null object
value 4032 non-null object
dtypes: float64(1), object(2)
memory usage: 94.6+ KB
'''def get_test_scores(df):
"""Select parameter values and test scores"""
data = df.filter(like='param').join(results[['mean_test_score']])
return data.rename(columns={c: '_'.join(c.split('_')[1:]) for c in data.columns})テストスコア vs パラメーターセッティングのプロット
plot_data = get_test_scores(results).drop('min_impurity_decrease', axis=1)
plot_params = plot_data.columns[:-1].tolist()
plot_data.info()
'''
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 576 entries, 0 to 575
Data columns (total 7 columns):
learning_rate 576 non-null object
max_depth 576 non-null object
max_features 576 non-null object
min_samples_split 576 non-null object
n_estimators 576 non-null object
subsample 576 non-null object
test_score 576 non-null float64
dtypes: float64(1), object(6)
memory usage: 31.6+ KB
'''fig, axes = plt.subplots(ncols=3, nrows=2, figsize=(12, 6))
axes = axes.flatten()
for i, param in enumerate(plot_params):
sns.swarmplot(x=param, y='test_score', data=plot_data, ax=axes[i])
fig.suptitle('Mean Test Score Distribution by Hyperparameter', fontsize=14)
fig.tight_layout()
fig.subplots_adjust(top=.94)
fig.savefig('figures/sklearn_cv_scores_by_param', dpi=300);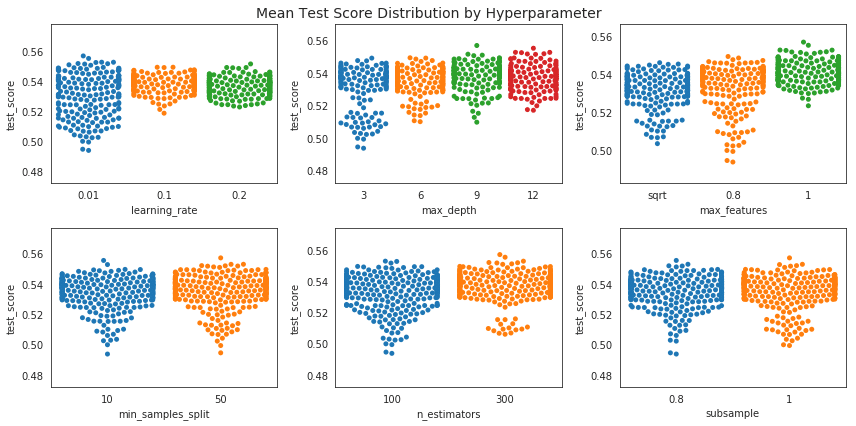
ダミーエンコード パラメーター
data = get_test_scores(results)
params = data.columns[:-1].tolist()
data = pd.get_dummies(data,columns=params, drop_first=False)
data.info()
'''
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 576 entries, 0 to 575
Data columns (total 19 columns):
test_score 576 non-null float64
learning_rate_0.01 576 non-null uint8
learning_rate_0.1 576 non-null uint8
learning_rate_0.2 576 non-null uint8
max_depth_3 576 non-null uint8
max_depth_6 576 non-null uint8
max_depth_9 576 non-null uint8
max_depth_12 576 non-null uint8
max_features_0.8 576 non-null uint8
max_features_1 576 non-null uint8
max_features_sqrt 576 non-null uint8
min_impurity_decrease_0.0 576 non-null uint8
min_impurity_decrease_0.01 576 non-null uint8
min_samples_split_10 576 non-null uint8
min_samples_split_50 576 non-null uint8
n_estimators_100 576 non-null uint8
n_estimators_300 576 non-null uint8
subsample_0.8 576 non-null uint8
subsample_1.0 576 non-null uint8
dtypes: float64(1), uint8(18)
memory usage: 14.7 KB
'''回帰木を作成
reg_tree = DecisionTreeRegressor(criterion='mse',
splitter='best',
max_depth=4,
min_samples_split=5,
min_samples_leaf=10,
min_weight_fraction_leaf=0.0,
max_features=None,
random_state=42,
max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_impurity_split=None,
presort=False)gbm_features = data.drop('test_score', axis=1).columns
reg_tree.fit(X=data[gbm_features], y=data.test_score)特徴量重要度の計算
reg_tree = DecisionTreeRegressor(criterion='mse',
splitter='best',
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_features=None,
random_state=42,
max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_impurity_split=None,
presort=False)
gbm_features = data.drop('test_score', axis=1).columns
reg_tree.fit(X=data[gbm_features], y=data.test_score)gbm_fi = (pd.Series(reg_tree.feature_importances_,
index=gbm_features)
.sort_values(ascending=False))
gbm_fi = gbm_fi[gbm_fi > 0]
idx = [p.split('_') for p in gbm_fi.index]
gbm_fi.index = ['_'.join(p[:-1]) + '=' + p[-1] for p in idx]
gbm_fi.sort_values().plot.barh(figsize=(5,5))
plt.title('Hyperparameter Importance')
sns.despine()
plt.tight_layout();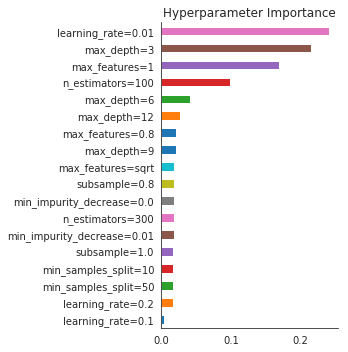
線形回帰を実行
data = get_test_scores(results)
params = data.columns[:-1].tolist()
data = pd.get_dummies(data,columns=params, drop_first=True)
model = OLS(endog=data.test_score, exog=add_constant(data.drop('test_score', axis=1))).fit(cov_type='HC3')
print(model.summary())
'''
OLS Regression Results
==============================================================================
Dep. Variable: test_score R-squared: 0.403
Model: OLS Adj. R-squared: 0.391
Method: Least Squares F-statistic: 26.95
Date: Mon, 24 Aug 2020 Prob (F-statistic): 3.34e-45
Time: 07:03:12 Log-Likelihood: 1976.0
No. Observations: 576 AIC: -3928.
Df Residuals: 564 BIC: -3876.
Df Model: 11
Covariance Type: HC3
==============================================================================================
coef std err z P>|z| [0.025 0.975]
----------------------------------------------------------------------------------------------
const 0.5213 0.002 322.640 0.000 0.518 0.524
learning_rate_0.1 0.0080 0.001 9.293 0.000 0.006 0.010
learning_rate_0.2 0.0061 0.001 6.807 0.000 0.004 0.008
max_depth_6 0.0043 0.001 4.333 0.000 0.002 0.006
max_depth_9 0.0071 0.001 6.781 0.000 0.005 0.009
max_depth_12 0.0061 0.001 5.545 0.000 0.004 0.008
max_features_1 0.0081 0.001 9.428 0.000 0.006 0.010
max_features_sqrt -0.0016 0.001 -1.873 0.061 -0.003 7.37e-05
min_impurity_decrease_0.01 -6.906e-05 0.001 -0.104 0.917 -0.001 0.001
min_samples_split_50 0.0007 0.001 0.997 0.319 -0.001 0.002
n_estimators_300 0.0042 0.001 6.278 0.000 0.003 0.005
subsample_1.0 0.0006 0.001 0.845 0.398 -0.001 0.002
==============================================================================
Omnibus: 15.164 Durbin-Watson: 0.971
Prob(Omnibus): 0.001 Jarque-Bera (JB): 15.665
Skew: -0.398 Prob(JB): 0.000397
Kurtosis: 3.139 Cond. No. 7.90
==============================================================================
'''この記事が気に入ったらサポートをしてみませんか?