
第9章 ボラティリティ予測と統計的裁定取引 第5節: 統計的裁定取引(共和分検定)

はじめに
今回は統計的裁定取引について話します。ここら辺の知識は直接収益に結び付く可能性があるので詳しく解説していきたいと思います。
共和分による統計的裁定取引とは大雑把に以下の二つのステップが必要になります。
・形成段階(Formation phase):長期的に平均回帰するような資産の組を見つける。
・取引段階(Trading phase):スプレッドが収束または発散することによって生じる価格の変化から取引ルールを定める。
どのように同じ動きをする資産の組を選定し取引するのか。
・距離のアプローチ:2つの銘柄間の距離を定義(厳密に相関係数は距離にはならない。相関係数を使用する一例として、d(X,Y) = √(1-ρ[X,Y]^2)として定義してあげる必要がある。
・共和分アプローチ:計量経済モデルで、2つないしもっと多い資産の長期的な関係からアプローチします。このセクションでは、ヨハンセン検定とEngle-Granger検定から証券のペアまたはバスケットを見つけます。
・時系列アプローチ:取引段階に焦点を当てて話すと、このカテゴリの戦略は資産間のスプレッドを平均回帰するような確率過程としてモデリングして、エントリーとエグジット条件を最適化する。既にそのような通貨ペアは見つけていると仮定する。(e.g. 原資産 vs その先物)
・確率制御アプローチ:時系列アプローチと似ているが、ここでの目標は確率制御を用いて価値と政策関数を見つけて取引ルールを最適化して、最適なポートフォリオに到達することである。
・その他のアプローチ:主成分分析やコピュラのような統計モデルに基づく資産ペアの発見以外に、最近では機械学習で相対的な価格やフォワードリターンの予測等が人気になっている。次のチャプターでこの目的のためのいくつかの機械学習アルゴリズムとそれに対応した多変量ペアトレーディング戦略をカバーする。
共和分とは?
以下wiki引用です。
共和分(きょうわぶん、英: cointegration)とは時系列変数の集まり (X1, X2, ..., Xk) が持つ統計学的性質である。まず、共和分を持つ全ての系列は1次の和分過程でなくてはならない(単位根を参照)。次に、この系列の線形結合が0次の和分過程(定常過程ということ)ならば、この時系列は共和分していると言う。厳密には、もし変数 (X, Y, Z) が全て1次の和分過程であり、ある係数 a,b,c が存在して aX+bY+cZ が0次の和分過程となるならば、(X, Y, Z) は共和分しているという。時系列はしばしば確率的にしろ非確率的にしろトレンドを持つ。チャールズ・ネルソンとチャールズ・プロッサーが行った研究では、アメリカの多数のマクロ経済時系列(例えば、GNP、賃金、雇用者数など)は確率的なトレンドを持つ、すなわち単位根過程であるか、1次の和分過程であった。彼らはまたこれらの単位根過程が標準的ではない統計的性質を持っている事を示した。この結果から、伝統的な計量経済学の手法をこれらの系列に適用することは出来ないということが明らかとなった。
実務上でのペアトレーディング
距離のアプローチは資産間の標準化された価格またはリターンの相関係数に基づく距離から算出されるため、シンプルで且つ共和分検定を比べ計算量も少ない。
また、計算速度によるアドバンテージは非常に有益である。なぜなら、計算量は資産の数の二乗に比例するためである。言い換えれば、距離の方では一番儲かるペアを見つける必要がないということである。高すぎる相関は取引機会を排除するからである。経験的な研究によると共和分ペアのスプレッドのボラティリティは距離のペアのスプレッドのボラティリティの約2倍になります。(2015 Huck and Afawubo)
この計算量コストと結果の資産ペアのクオリティのトレードオフを調整するため、Krauss(2017)は二つのアプローチを組み合わせたものを推奨しました。
1.まず、安定していて且つ低いドリフトを持つペアだけに絞る。
2.そのペアたちに対して共和分検定を行う。
このプロセスではスプレッドが発散するリスクを抑えつつ、スプレッドのボラティリティを確保するため、より高い収益機会を見つけることになる。
今回使用する共和分検定は二つである。
・エンゲル–グレンジャーの検定
・ヨハンセン
データ取得の注意点
今回のデータはstooqから取得してあります。詳細はdata/create_stooq_data.ipynbを拝読してください。
注意点としましては、そのまま実行すると日本株しか取得しませんので、Downloading price dataのセクションで、
data_url = 'd_us_txt.zip'を定義して、米国株も取得しましょう。
インポートと設定
import warnings
warnings.filterwarnings('ignore')from time import time
from pathlib import Path
import pandas as pd
from sklearn.model_selection import StratifiedKFold, GridSearchCV
from sklearn.metrics import confusion_matrix
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegressionCV
import numpy as np
from numpy.linalg import LinAlgError
from statsmodels.tsa.stattools import adfuller, coint
from statsmodels.tsa.vector_ar.vecm import coint_johansen
from statsmodels.tsa.api import VAR
import matplotlib.pyplot as plt
import seaborn as snspd.set_option('display.float_format', lambda x: f'{x:,.2f}')DATA_PATH = Path('..', 'data')
STORE = DATA_PATH / 'assets.h5'ヨハンセン検定異常値閾値
critical_values = {0: {.9: 13.4294, .95: 15.4943, .99: 19.9349},
1: {.9: 2.7055, .95: 3.8415, .99: 6.6349}}trace0_cv = critical_values[0][.95] # critical value for 0 cointegration relationships
trace1_cv = critical_values[1][.95] # critical value for 1 cointegration relationship株とETFデータの読み込みとクレンジング
高い相関を持つ資産を取り除く
def remove_correlated_assets(df, cutoff=.99):
corr = df.corr().stack()
corr = corr[corr < 1]
to_check = corr[corr.abs() > cutoff].index
keep, drop = set(), set()
for s1, s2 in to_check:
if s1 not in keep:
if s2 not in keep:
keep.add(s1)
drop.add(s2)
else:
drop.add(s1)
else:
keep.discard(s2)
drop.add(s2)
return df.drop(drop, axis=1)定常的な時系列データを取り除く
def check_stationarity(df):
results = []
for ticker, prices in df.items():
results.append([ticker, adfuller(prices, regression='ct')[1]])
return pd.DataFrame(results, columns=['ticker', 'adf']).sort_values('adf')def remove_stationary_assets(df, pval=.05):
test_result = check_stationarity(df)
stationary = test_result.loc[test_result.adf <= pval, 'ticker'].tolist()
return df.drop(stationary, axis=1).sort_index()資産選定
def select_assets(asset_class='stocks', n=500, start=2010, end=2019):
idx = pd.IndexSlice
with pd.HDFStore(STORE) as store:
df = (pd.concat([
store[f'stooq/us/nasdaq/{asset_class}/prices'],
store[f'stooq/us/nyse/{asset_class}/prices']
]).sort_index().loc[idx[:, str(start):str(end)], :])
df = df.reset_index().drop_duplicates().set_index(['ticker', 'date'])
df['dv'] = df.close.mul(df.volume)
dv = df.groupby(level='ticker').dv.mean().nlargest(n=n).index
df = (df.loc[idx[dv, :],
'close'].unstack('ticker').ffill(limit=5).dropna(axis=1))
df = remove_correlated_assets(df)
return remove_stationary_assets(df).sort_index()for asset_class, n in [('etfs', 500), ('stocks', 250)]:
df = select_assets(asset_class=asset_class, n=n)
df.to_hdf('data.h5', f'{asset_class}/close')ティッカーを辞書型で取得
def get_ticker_dict():
with pd.HDFStore(STORE) as store:
return (pd.concat([
store['stooq/us/nyse/stocks/tickers'],
store['stooq/us/nyse/etfs/tickers'],
store['stooq/us/nasdaq/etfs/tickers'],
store['stooq/us/nasdaq/stocks/tickers']
]).drop_duplicates().set_index('ticker').squeeze().to_dict())names = get_ticker_dict()相関クラスターを視覚化する
stocks = pd.read_hdf('data.h5', 'stocks/close')
stocks.info()
'''
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 2516 entries, 2010-01-04 to 2019-12-31
Columns: 173 entries, AA.US to YUM.US
dtypes: float64(173)
memory usage: 3.3 MB
'''etfs = pd.read_hdf('data.h5', 'etfs/close')
etfs.info()
'''
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 2516 entries, 2010-01-04 to 2019-12-31
Columns: 139 entries, AAXJ.US to YCS.US
dtypes: float64(139)
memory usage: 2.7 MB
'''tickers = {k: v for k, v in names.items() if k in etfs.columns.union(stocks.columns)}
pd.Series(tickers).to_hdf('data.h5', 'tickers')corr.info()
'''
<class 'pandas.core.frame.DataFrame'>
Index: 173 entries, AA.US to YUM.US
Columns: 139 entries, AAXJ.US to YCS.US
dtypes: float64(139)
memory usage: 194.2+ KB
'''cmap = sns.diverging_palette(220, 10, as_cmap=True)
sns.clustermap(corr, cmap=cmap, center=0);
経験則から候補を選定する。
計算複雑性:実行時間を比較する。
stocks.shape, etfs.shape
'''
((2516, 173), (2516, 139))
'''stocks.info()
'''
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 2516 entries, 2010-01-04 to 2019-12-31
Columns: 173 entries, AA.US to YUM.US
dtypes: float64(173)
memory usage: 3.3 MB
'''etfs.info()
'''
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 2516 entries, 2010-01-04 to 2019-12-31
Columns: 139 entries, AAXJ.US to YCS.US
dtypes: float64(139)
memory usage: 2.7 MB
'''security = etfs['AAXJ.US'].loc['2010': '2013']
candidates = stocks.loc['2010': '2013']security = security.div(security.iloc[0])
candidates = candidates.div(candidates.iloc[0])
spreads = candidates.sub(security, axis=0)n, m = spreads.shape
X = np.ones(shape=(n, 2))
X[:, 1] = np.arange(1, n+1)経験則
%%timeit
np.linalg.inv(X.T @ X) @ X.T @ spreads
'''
850 µs ± 22.4 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
'''%%timeit
spreads.std()
'''
1.53 ms ± 50.9 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
'''%%timeit
candidates.corrwith(security)
'''
33.5 ms ± 468 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
'''%%timeit
for candidate, prices in candidates.items():
df = pd.DataFrame({'s1': security,
's2': prices})
var = VAR(df.values)
lags = var.select_order()
k_ar_diff = lags.selected_orders['aic']
coint_johansen(df, det_order=0, k_ar_diff=k_ar_diff)
coint(security, prices, trend='c')[:2]
coint(prices, security, trend='c')[:2]
'''
22.7 s ± 611 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
'''距離ベースの経験則で共和分ペアを見つける。
以下のメソッドでは、23000以上のペアと2010-14と2015-19のETFから以下の距離を計算する。
・スプレッドのドリフト、スプレッドの時間方向のトレンドの線形回帰として定義する。
・スプレッドのボラティリティ
・標準化した価格の系列とリターンの間の相関係数
低いドリフトとボラティリティで高い相関を持つ場合は、単純に共和分と言える。
def compute_pair_metrics(security, candidates):
security = security.div(security.iloc[0])
ticker = security.name
candidates = candidates.div(candidates.iloc[0])
spreads = candidates.sub(security, axis=0)
n, m = spreads.shape
X = np.ones(shape=(n, 2))
X[:, 1] = np.arange(1, n + 1)
drift = ((np.linalg.inv(X.T @ X) @ X.T @ spreads).iloc[1]
.to_frame('drift'))
vol = spreads.std().to_frame('vol')
corr_ret = (candidates.pct_change()
.corrwith(security.pct_change())
.to_frame('corr_ret'))
corr = candidates.corrwith(security).to_frame('corr')
metrics = drift.join(vol).join(corr).join(corr_ret).assign(n=n)
tests = []
for candidate, prices in candidates.items():
df = pd.DataFrame({'s1': security, 's2': prices})
var = VAR(df.values)
lags = var.select_order() # select VAR order
k_ar_diff = lags.selected_orders['aic']
# Johansen Test with constant Term and estd. lag order
cj0 = coint_johansen(df, det_order=0, k_ar_diff=k_ar_diff)
# Engle-Granger Tests
t1, p1 = coint(security, prices, trend='c')[:2]
t2, p2 = coint(prices, security, trend='c')[:2]
tests.append([ticker, candidate, t1, p1, t2, p2,
k_ar_diff, *cj0.lr1])
columns = ['s1', 's2', 't1', 'p1', 't2', 'p2', 'k_ar_diff', 'trace0', 'trace1']
tests = pd.DataFrame(tests, columns=columns).set_index('s2')
return metrics.join(tests)こちら計算物凄い時間がかかるのでお気をつけてください。(私は2時間以上かかりました(笑)
spreads = []
start = 2010
stop = 2019
etf_candidates = etfs.loc[str(start): str(stop), :]
stock_candidates = stocks.loc[str(start): str(stop), :]
s = time()
for i, (etf_ticker, etf_prices) in enumerate(etf_candidates.items(), 1):
df = compute_pair_metrics(etf_prices, stock_candidates)
spreads.append(df.set_index('s1', append=True))
if i % 10 == 0:
print(f'{i:>3} {time() - s:.1f}')
s = time()
'''
10 623.3
20 610.5
30 621.1
40 618.1
50 629.8
60 646.6
70 642.2
80 637.7
90 626.6
100 613.0
110 611.2
120 637.2
130 636.2
'''names = get_ticker_dict()
spreads = pd.concat(spreads)
spreads.index.names = ['s2', 's1']
spreads = spreads.swaplevel()
spreads['name1'] = spreads.index.get_level_values('s1').map(names)
spreads['name2'] = spreads.index.get_level_values('s2').map(names)spreads['t'] = spreads[['t1', 't2']].min(axis=1)
spreads['p'] = spreads[['p1', 'p2']].min(axis=1)
Engle-Granger vs ヨハンセン: 結果の比較方法
spreads['trace_sig'] = ((spreads.trace0 > trace0_cv) &
(spreads.trace1 > trace1_cv)).astype(int)
spreads['eg_sig'] = (spreads.p < .05).astype(int)pd.crosstab(spreads.eg_sig, spreads.trace_sig)
'''
trace_sig 0 1
eg_sig
0 21778 748
1 1360 161
'''spreads['coint'] = (spreads.trace_sig & spreads.eg_sig).astype(int)spreads.info()
'''
<class 'pandas.core.frame.DataFrame'>
MultiIndex: 24047 entries, ('AAXJ.US', 'AA.US') to ('YCS.US', 'YUM.US')
Data columns (total 19 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 drift 24047 non-null float64
1 vol 24047 non-null float64
2 corr 24047 non-null float64
3 corr_ret 24047 non-null float64
4 n 24047 non-null int64
5 t1 24047 non-null float64
6 p1 24047 non-null float64
7 t2 24047 non-null float64
8 p2 24047 non-null float64
9 k_ar_diff 24047 non-null int64
10 trace0 24047 non-null float64
11 trace1 24047 non-null float64
12 name1 24047 non-null object
13 name2 24047 non-null object
14 t 24047 non-null float64
15 p 24047 non-null float64
16 trace_sig 24047 non-null int64
17 eg_sig 24047 non-null int64
18 coint 24047 non-null int64
dtypes: float64(12), int64(5), object(2)
memory usage: 3.6+ MB
'''spreads = spreads.reset_index()sns.scatterplot(x=np.log1p(spreads.t.abs()),
y=np.log1p(spreads.trace1),
hue='coint', data=spreads[spreads.trace0>trace0_cv]);
データの書き込み
spreads.to_hdf('heuristics.h5', 'spreads')spreads = pd.read_hdf('heuristics.h5', 'spreads')評価
spreads.drift = spreads.drift.abs()pd.crosstab(spreads.eg_sig, spreads.trace_sig)
'''
trace_sig 0 1
eg_sig
0 21778 748
1 1360 161
'''pd.set_option('display.float_format', lambda x: f'{x:.2%}')
pd.crosstab(spreads.eg_sig, spreads.trace_sig, normalize=True)
'''
trace_sig 0 1
eg_sig
0 90.56% 3.11%
1 5.66% 0.67%
'''fig, axes = plt.subplots(ncols=4, figsize=(20, 5))
for i, heuristic in enumerate(['drift', 'vol', 'corr', 'corr_ret']):
sns.boxplot(x='coint', y=heuristic, data=spreads, ax=axes[i])
fig.tight_layout();
結果の優位性
1.ロジスティック回帰モデルで十分な共和性を持つペアを予測する。
2.AUCで結果の妥当性の評価をする。
spreads.groupby(spreads.coint)['drift', 'vol', 'corr'].describe().stack(level=0).swaplevel().sort_index()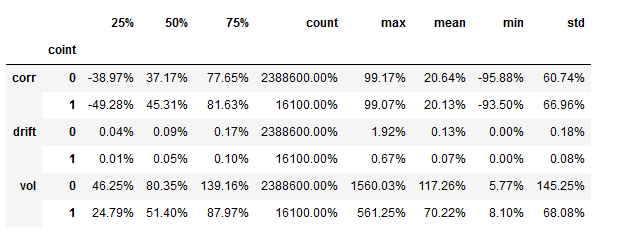
spreads.coint.value_counts()
'''
0 23886
1 161
Name: coint, dtype: int64
'''ロジスティック回帰
ロジスティック回帰のパラメーターで交差検定はデフォルトでStratified K-Folds(K=5)になっているみたいです。詳しくはsklearnのドキュメントをご参照ください。
y = spreads.coint
X = spreads[['drift', 'vol', 'corr', 'corr_ret']]log_reg = LogisticRegressionCV(Cs=np.logspace(-10, 10, 21),
class_weight='balanced',
scoring='roc_auc')log_reg.fit(X=X, y=y)
Cs = log_reg.Cs_
scores = pd.DataFrame(log_reg.scores_[True], columns=Cs).mean()
scores.plot(logx=True);
f'C:{np.log10(scores.idxmax()):.2f}, AUC: {scores.max():.2%}'
'''
'C:-10.00, AUC: 64.86%'
'''
log_reg.coef_
'''
array([[-3.53484281e-10, -2.82771411e-07, -3.08418033e-09,
-7.35534688e-08]])
'''y_pred = log_reg.predict_proba(X)[:, 1]
confusion_matrix(y_true=spreads.coint, y_pred=(y_pred>.5))
'''
array([[23886, 0],
[ 161, 0]])
'''※本の中ではAUCが0.815と書いてありましたが、それに関しては完全に疑問符でした。評価方法だけご参考にしてくださいませ。
この記事が気に入ったらサポートをしてみませんか?