
オープンソースERP&CRM「Dolibarr」の微妙な日本語をなんとかする方法

前回まででとりあえずの設定を済ませたDolibarrだが、時々絶妙におかしい日本語が画面に登場する。

これはダッシュボードの画面だが、このじんわりとおかしい日本語群…おわかりいただけるだろうか。
海外製オープンソースではよくあることだが、これに無理して耐える必要はなく、即座に自分で書き換えて反映させる簡単な方法がある。今回はその日本語文字列の登録方法を紹介する。

左メニューの「翻訳」をクリック。

表示されたリストの一番上に「現在の翻訳文字列」という項目があるので、ここに直したい文字列を入力して、右の虫眼鏡マークをクリック。
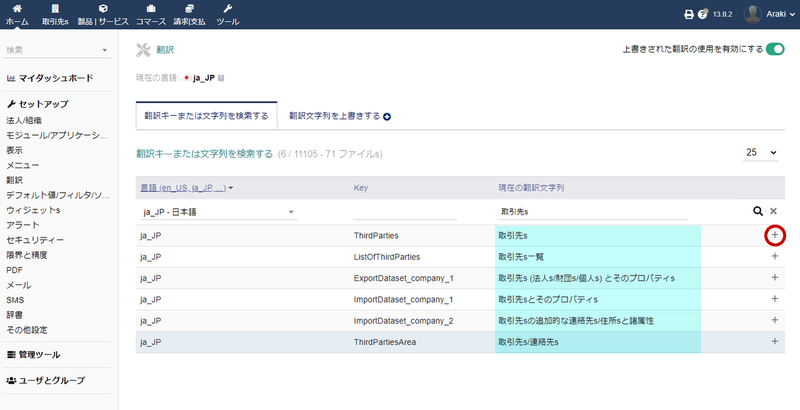
該当する文字列を含む翻訳が絞り込み表示されるので、該当するものを探して行の右端の+マークをクリック。

変更用フォームが表示されるので、直した文字列を入力し「加える」ボタンをクリック。(”加える”も微妙におかしいので余力があったら”追加”あたりに直すといいかもしれない…)

修正が終わったものは「翻訳文字列を上書きする」タブから見ることができる。再度修正をしたい時は、この画面で該当文字列の行の右端の鉛筆マークをクリックすればOK。(よく見たら説明文に「誤っていたりなの。」って書いてあるな…。どんな翻訳エンジン使ったんだろう)

修正は即座に反映されるので、目についたおかしい部分をちまちまと直していくといいと思う。この変更は自分のDolibarrにしか反映されないので、日本語にするのが難しい単語などは適当に自分好みに変えて登録してしまうという使い方もできる。
以前に書いたようにTransifexというオンラインツールによるDolibarrの翻訳プロジェクトがあるので、そこにマトモな日本語を少しずつではあるが登録して行っているところだ。次回のアップデートで採用されることを祈りつつ…
(ヘッダー画像クレジット:https://flic.kr/p/dvPdHA)
この記事が気に入ったらサポートをしてみませんか?