
AIによるコード生成は人間を超えるのか

この記事では、AIによるコード自動生成の基本的なメカニズムから、最新の研究結果までを俯瞰的に眺め、現代のコード生成技術の潮流と、人間を超越する可能性について論じる。
コード自動生成の基本的なメカニズム
現代のコード自動生成は、かつてのプログラミング合成のアプローチとは異なり、自然言語と同じ要領でソースコードをLLMに学習させることから始まる。なので、コード自動生成のメカニズムに入る前に、コード自動生成に限らない一般的なLLMの学習方法についておさらいすることから始めよう。
LLMにおいては基本的に、大規模なテキストデータをNext-Token Predictionのタスクで事前学習することで、汎用的な基盤モデルを得る。Next-Token Predictionとは、単純に言えば、あるテキストが与えられたときに、次に来る単語やトークン(言語の最小単位)を予測するタスクである。このプロセスは、人間が文章を読みながら次に来る言葉を予測するのに似ている。例えば、「今日はとてもいい天気」の次に「だ」という単語が来ることを予測するのと同じだ。このタスクを通じて、LLMは言語の文法的構造、単語間の関係、文脈の理解など、言語に関する複雑なパターンを学習している。
LLMとしてコード生成器を構築する最初の方法は、このNext-Token Predictionの枠組みでソースコードを学習させることだ。それはつまり、コード生成器に、与えられた部分的なコードから次のトークンを予測するというタスクを解かせる形で、ソースコードのパターンを学習させるということである。

ただし、そのためには学習の元となる大量のソースコードのデータが必要である。例えば、オープンソースの言語モデルであるStarCoder[1]などは、Github上にある2億以上のレポジトリからのソースコードを取得し、利用可能なライセンスのもののみを残し、さらに拡張子による分別や重複除去の処理を施して抽出した3テラバイト分のデータ(The Stack)[2]を用いて学習させ、コード生成モデルであるStarCoder+を得ている。また、コード生成はPythonに対して行われることが多いので、別途Pythonコードで追加に学習させるなどのケースもある。
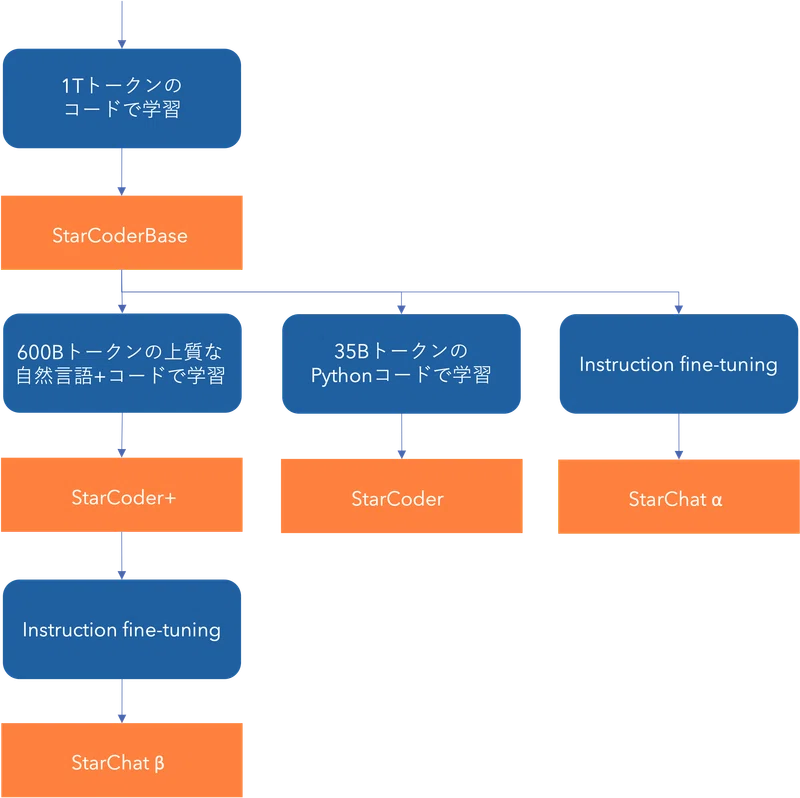
「このコードを生成せよ」という指示に沿うためのファインチューニング
実際には、コード生成器はユーザーからの指示に沿ってソースコードを生成するという使われ方をする。基盤モデルそれ自身である程度指示に沿ったコード生成はできるものの、より質の高い生成器を構築するにはさらに一手間が必要になる。そのため、指示とプログラムをセットにした学習データを整え、それを用いて事前学習済みの基盤モデルをファインチューニングしていくことになる。例えば、「レビューのポジネガを判定するプログラムを作って」という趣旨のお題とそのプログラムのセットのような、コード生成に関する指示と解答を大量に用意し、それを使って指示に沿ってコード生成できるようにモデルを微調整していく。例えば、Facebookのオープンソースのコード生成モデルであるCode Llamaは、50億トークンからなる指示データセットを使ってInstruction fine-tuningを行い、ユーザーからの指示に精度高く答えることのできるCode Llama Instructを構築している[3]。
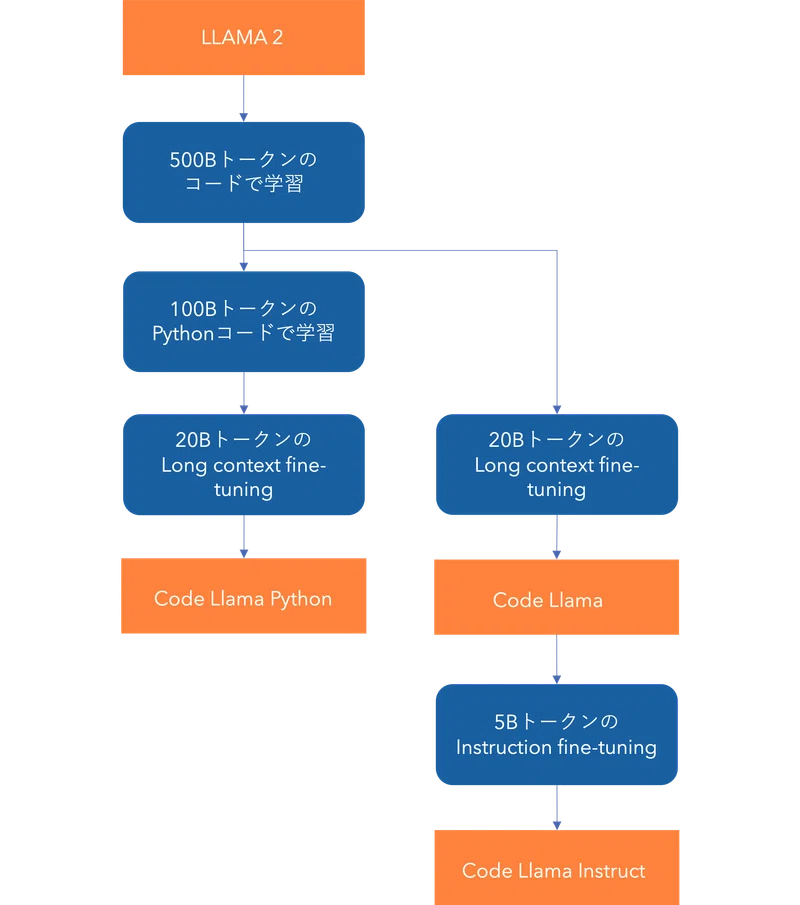
Code Llamaは他にも、ソースコードの生成に関する特徴を考慮に入れた学習の工夫をしている。例えば、ソースコード生成を利用する際はしばしば、周囲のコードの文脈と合うように適切なコードブロックを差し込むというような使い方がされる。それに適したように、学習にはNext-Token Predictionだけでなく、周囲の文脈を考慮に入れる穴埋め(Infilling)での学習が行われる。また、考慮可能な文脈も直前直後だけでなく、ファイル全体はレポジトリ全体にまで広げられるように、10万トークンのコンテキスト幅でのファインチューニング(Long context fine-tuning)も行っている。
学習データ自動生成:大量の学習データをどう手に入れるか
ユーザーの指示に従ってコードを作成できるようにモデルをファインチューニングするには、十分な量と質の学習データが必要である。そうなると、コード生成器の質を上げるためには、これらをどう構築するかが問題になってくる。指示データとそれをこなすソースコードを手作業で作成する方法もあるが、量を集めるは難しい。そのため、この分野では学習データを自動生成する様々な手法が提案されている。
例えば、Code LlamaはSelf-instruct[4]の手法を用いて、自動的にユニットテストとその解のコードを生成している。この手法では、元となるシードデータから学習対象のLLM自身、もしくはより強力なLLMを用いて指示データとコードを生成し(Code Llamaの場合は、Llama 2 70Bで指示を作り、Code Llama 7Bで解答およびユニットテストを作成)、重複やユニットテストに通らないものを取り除き、データセットに追加する、というプロセスで大量のトレーニングデータを生成している。
また、そのように生成されたトレーニングデータを、LLMを用いてそこからさらに様々な方向性へと進化させていくアプローチも存在する。WizardCoder[5]のEvol-instructは、生成されたトレーニングデータをベースに、「元の問題に新しい制約と要求を追加」「タスク要件をより具体的にする」「解くのに必要な推論ステップを増やす」などのお題を与えて、トレーニングデータをより複雑かつ多様に進化させていく。
さらに、そもそものシードデータにオープンソースのデータを用いる方法も存在する。MagiCoder[6]のOSS-instructは、GitHubなどからオープンソースのコードデータを取得し、そこからコード生成に関する様々なカテゴリ(システム設計、データベース、数値計算、データサイエンス、パフォーマンス最適化、UI、セキュリティ)およびその他ドメイン特有タスクなどをバランスよく用い、ChatGPTなどの強力なLLMによりトレーニングデータを生成している。MagiCoderはこのOSS-instructと上述のEvol-instructなどを組み合わせ、HumanEval[7]の評価指標でGPT-4に迫る性能を発揮している。

模倣から自己学習へ、人間を超えるための第一歩
コード自動生成の分野では、上述のように、ファインチューニングに用いるトレーニングデータを工夫して性能を上げる方法が数多く提案されている一方、より根本からの性能向上を目指す方法も提案されている。例えば、Google DeepMindは教師ありのファインチューニングの代わりに、強化学習を用いた自己学習の手法であるReST[8]およびReST^EM[9]を提案している。
教師ありファインチューニング(SFT)によるInstruction tuningの方法では、学習時に指示と正解のコードで構成されるトレーニングデータにアクセスすることができる。そしてそれを元に、正解のコードを模倣するようにNext-Token Predictionのタスクで学習する。

その代わりに、生成されたコードをAI自身が検証し、良い生成と悪い生成を判定することができるとしたらどうだろうか。良い生成に対しては高い報酬を、悪い生成に対しては低い報酬を設定し、その報酬関数へのアクセスを可能にした時に何ができるだろうか。その場合、正解のコードを予め用意していなくても、強化学習(RL)を用いて報酬が最大化するようにコード生成モデルを学習させることができるのである。つまり、指示に応えるコードの入出力が満たす論理的制約や入出力例によって、生成されたコードが正しいか誤りかがわかるならば、指示データのみからの学習が可能になるのだ。

そしてそれは、人のコードの書き方を基準とし、それを模倣したコード生成から、検証をパスすることを基準として、それに最適化したコード生成へと移行することを意味する。そしてこのアプローチは、人の帰納バイアスに囚われず、人に依存することなく、目的を達成するための本当に最適なコードに到達できる可能性を秘めている。それはつまり、コード生成において人をはるかに超えていく可能性を秘めているということでもある。
強化学習における過学習の問題:人間超えは一筋縄ではいかない
しかし、検証をパスすることを目的として報酬関数を設計し、それに対してモデルを最適化することには危険が伴う。なぜならば、報酬関数が真の目的と正確に一致していない場合、誤った目標に対して最適化が行われてしまうからである。例えば、入力に対してある特定の傾向を持った出力をする関数(y=xなど)を生成させようと意図して、その結果を入出力例([x,y]=[1,1][2,2][3,3]など)を満たすかどうかのみを確認することで検証したとしても、生成器は正しく意図を汲み取るとは限らない。それは、この方法の下では入出力例を満たすことのみが評価の基準であり、それをクリアするのであればどのような関数でも構わないからだ。従って、ユニットテストさえ通れば良いという、ユニットテストに対して過学習されたコード生成器が出来上がってしまう危険性があるのだ。もちろん、そうなってしまうと学習すればするほど性能評価を下げる結果となっていく。
事前学習や教師ありファインチューニングにおいては、基本的にはNext-Token Predictionで学習されるので、正解データなら次のトークンはこのようになるだろうという原理でコードが生成される。大規模なデータで十分に学習されたコード生成器には、人が持つ帰納バイアスと類似したものが備わっており、まるで見当違いなコードを生成する可能性は低い。しかし、強化学習を用いてモデルを上書きしてしまうと、人の認識と一致する帰納バイアスを失い、人の認識から外れたものが生成されてしまう。
もちろん、それで目的を果たすのであれば良い。それは、人には思いつかなかったような創造的な解を導き出したという意味でもある。ただ、検証器が完全に正しく目的を反映するものでなかった場合、単なる無意味なものを生成するコード生成器になってしまうのだ。
大量生成と検証という、最も機械的なアプローチ
モデルを過学習させることなく、入出力例による部分的な検証ができるというメリットを生かす方法はあるだろうか。一つの方法は、検証器を学習時に利用するのではなく、推論時に利用するというやり方だ。つまり、Next-Token Predictionで学習したLLMによって生成したコードを、検証器を用いて正しいかどうかを検証することで、誤った生成を防ぐという使い方である。これができると、大量のソースコードを生成して、その中から正しいものだけを選別するという総当たり式(Brute-Force)が可能になる。Next-Token Predictionの確率分布に従ってサンプリングしていけば、さまざまなバリエーションのコードを生成することができるため、選別の幅も十分にある。
例えば、Google DeepMindのAlphaCode[10]およびAlphaCode 2[11]では、コード生成モデル(AlphaCode 2ではGemini Proを基盤に用いる)から大規模(~100万)なサンプリングを施し、生成された全てのコードのうち99%をユニットテストを用いてフィルタリングする。また、AlphaCodeのアプローチでは、そこからさらに様々な入力に対して同じ出力をするものを同一クラスタに分類し、最終的に有力なクラスタ内の候補ををLLMで評価し、良いものを生成結果として出力する。こうすることで、正解を生成する可能性を大幅に引き上げている(性能は、競技プログラマーの上位15%に位置するレベルまで進歩している)。

Google DeepMindはこれとは別に、FunSearch[12]というアプローチも考案している。この方法では、仕様とプログラムデータベース内の関連プログラムを元に、仕様を満たすようなプログラムの候補を生成し、それを検証器を用いて評価し、良いものをDBに保存する、というサイクルを繰り返して、進化的により良いプログラムを得る手法だ。これは、Hallucinations(幻覚)を上手く避けながら、LLMに内在する創造性を利用し、そのポテンシャルを引き出す良い方法だ。FunSearchでは、この手法により数学のいくかの難問を解決することに成功した。

これらの手法では、コード生成器そのものによる出力はトレーニングデータの確率分布に基づいており、それはつまり、人のコードの書き方から大きく外れるようなものは生成されづらいことを意味する。また、過学習によって汎化性能が損なわれているわけではないので、ドメイン外の全くの未知の問題に対してもそれなりに対処可能である。与えられた入出力例と同じ出力すること以外にも、例えばセキュリティや可読性に関しても、ある程度保証されたものが生成される。LLMそのものを学習するわけではないので、学習にかかるコストが低いことも魅力的だ。
コード生成技術はどこまで発展するのか
コード生成技術は目覚ましい発展を遂げている。この自動化がこの先数年でどこまで進むかを予測することは難しい。上述のように、完全に自動化するためには、自動的なデータ生成、とりわけ検証可能性に基づく自己学習が重要なポイントとなる。ただ、検証が部分的にしか行えない、つまりいくつかの入出力例に基づいた不完全な形でしか検証を実現できないのならば、過学習の危険性があるため、強化学習のようなアプローチは採用しづらい。
これをクリアするには、単なる入出力例だけでない完全な仕様が必要だ。例えば形式手法のような、入出力が数学的に厳密に定義され、入出力の条件からプログラムの正当性を論理的に検証できるようなアプローチがあれば解決に近づく。しかし、それでもセキュリティや可読性な、あるいはUIなど検証方法の問題が残る。それらを全て考慮に入れた完全な検証器を構築するのは、かなり困難である。従って、強化学習によって人間の性能を大幅に超えるようなコード生成器が、すぐに完成するとは考えづらい。
従って、今後しばらくは、教師ありファインチューニング(SFT)のトレーニングデータを自動生成する方向性と、推論時にコード候補を大量に生成し、ユニットテストなどで誤りをフィルタリングする方向性が有望である。勝手な予測としては、この2つの方向性の発展だけでも、十分に人間のエキスパートの性能に匹敵するコード生成器を構築可能だと考えている。しかし、その予測の答え合わせはもう少し先の未来になるだろう。
参考文献
Li, R., Ben Allal, L., Zi, Y., et al. StarCoder: may the source be with you! ArXiv, abs/2305.06161, 2023.
Kocetkov, D., Li, R., Ben Allal, L., et al. The Stack: 3 TB of permissively licensed source code. ArXiv, abs/2211.15533, 2022.
Rozière, B., Gehring, J., Gloeckle, F., et al. Code Llama: Open Foundation Models for Code. ArXiv, abs/2308.12950, 2023.
Wang, Y., Kordi, Y., Mishra, S., et al. Self-Instruct: Aligning Language Models with Self-Generated Instructions. ArXiv, abs/2212.10560, 2023.
Luo, Z., Xu, C., Zhao, P., et al. WizardCoder: Empowering Code Large Language Models with Evol-Instruct. ArXiv, abs/2306.08568, 2023.
Wei, Y., Wang, Z., Liu, J., et al. Magicoder: Source Code Is All You Need. ArXiv, abs/2312.02120, 2023.
Chen, M., Tworek, J., Jun, H., et al. Evaluating Large Language Models Trained on Code. ArXiv, abs/2107.03374, 2021.
Gulcehre, C., Paine, T. L., Srinivasan, S., et al. Reinforced Self-Training (ReST) for Language Modeling. ArXiv, abs/2308.08998, 2023.
Singh, A., Co-Reyes, J. D., Agarwal, R., et al. Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models. ArXiv, abs/2312.06585, 2023.
Li, Y., Choi, D., Chung, J., et al. Competition-level code generation with AlphaCode. Science, 378(6624), 1092–1097, Dec. 2022. DOI: 10.1126/science.abq1158. Available at: http://dx.doi.org/10.1126/science.abq1158
AlphaCode Team, Google DeepMind. AlphaCode 2 Technical Report. 2023. Available at: https://storage.googleapis.com/deepmind-media/AlphaCode2/AlphaCode2_Tech_Report.pdf
Fawzi, A., Romera Paredes, B. FunSearch: Making New Discoveries in Mathematical Sciences Using Large Language Models. Google DeepMind Blog, 14 Dec. 2023. Available at: https://deepmind.google/discover/blog/funsearch-making-new-discoveries-in-mathematical-sciences-using-large-language-models/
この記事が気に入ったらサポートをしてみませんか?