
「お客様の声を聞くアンケート」の分析、どうせならデコムに発注して下さい!

今回のnoteは比較的ポジショントークが強めです。苦手な人は、そのまま前のページに戻るか、このページを表示するタブを消して下さい。
「お客様の声」って大事ですよね。
CoCo壱番屋の社長は1日をアンケートで始まり、アンケートで終えるそうです。だからでしょうか、特にチェーン系飲食店に足を運ぶと、必ず「お客様の声をお聞かせ下さい」というアンケートはがきが置かれています。
お客様の声を聞いているのは飲食系に限りません。B2B企業でも「顧客満足度調査にお答えください(抽選でAmazonギフト券が当たります)」といったメールが飛んできます。
業種業態を問わず、ビジネスを伸ばすヒントはお客様が知っている。それは紛うことなき事実でしょう。
問題は、どんな風に聞くかです。
定量調査だけだと具体的な内容に乏しいため定性調査(自由記述欄)を設けているアンケートは多いようです。ちなみにCoCo壱番屋のアンケートは、半分以上が自由記述欄でした。
今回のnoteは、どのような定性分析の手法が考えられるのか、その一部を紹介させて頂き、私から「定性調査ならデコムでっせ!」と強くアピールさせて下さい。
アンケートを分析するための考え方について
どんなアンケートも、基本的に「結論設問」と「結論に影響を与えそうな設問(影響設問)」で構成されています。
仮に「また店に来たいと思いますか?」という結論設問なら、再訪問の心理に影響を与えそうな「味」「雰囲気」「接客」という影響設問を設けます。
なぜなら、どの影響設問が悪ければ結論設問も悪いかが分かれば、次回に向けて改善できるからです。

影響質問が数字で表現されれば分析もし易いかもしれませんが、定性調査の場合はどうすれば良いでしょう。数字が良い悪いで判断できません。テキストに書かれた内容が良い悪いで判断するべきなのでしょうか。
①KH Coderを使ったクラスター分析
まずは、もっともライトに分析できる手法です。
定性データを何種類かのクラスターに分類して、それぞれの結論設問を集計しましょう。BOTTOM3(下図だと3〜5)が高いクラスターを発見し、その中でどんな特徴ある言葉が語られているかを確認します。

クラスター分析? RとかPython書けないとダメですよね? と一気にハードルを高く感じたかもしれません。
この場合、みんな大好き、誰でも使える「KH Coder」を利用します。GUIベースで操作できるので心理的ハードルは低いはず。
それでは、実際にやってみます。
今回の定性データは、デコムで定期的に開催している「成熟市場でもヒットを生み出すためのインサイト実践講座」のアンケート結果を用いています(※匿名加工済み)。ちなみに、7月18日、24日はまだ席が空いているので興味がある人はリンク先を覗いてみて下さい。
https://peatix.com/group/6949714/events
まず「KH Coder」を起動して、前処理を済ませた後に、「ツール」>「文書」>「クラスター分析」を選択します。

デフォルトのまま、まずは「OK」を選択します。
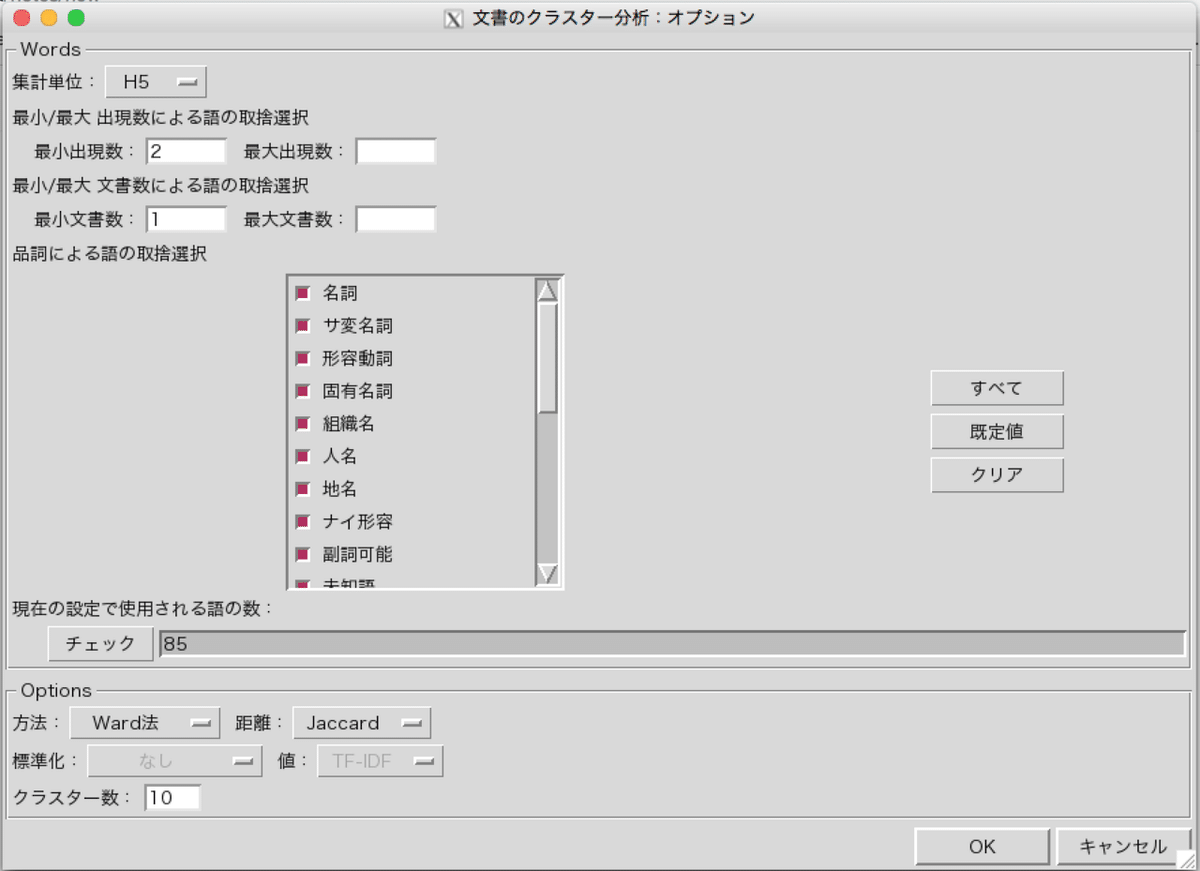
すると以下のような画面が現れます。画面左側が10個のクラスターに分類されたテキスト行の内訳です。
それぞれの内訳を見ても良いのですが、その前に「そもそもクラスターは10個で良いんだっけ?」問題を解決しなければいけません。そこで、右下にある「プロット」を選択します。

すると以下のような画面が現れます。このグラフは「クラスターは何個にするのか?」を判断するために使います。
KH Coderを作られた樋口先生の言葉を借りて説明します。
そもそも階層的クラスター分析は「似ているもの同士を順にくっつけて1つのクラスターにする」という作業を繰り返します。最初は割と似たもの同士をくっつけていきますが、最後はあまり似てないもの同士を無理してくっつけます。この「似ていない度合い」が併合水準です。だからグラフが右に行くにつれて併合水準は上がります。特に、折れ線が急に上がっている場合、そこで大きく無理をしてくっつけているとも言えます。

グラフを見ると、7から6にかけて大きく上昇しているようです。
クラスターの数の極め方は「併合水準」と「結果の解釈の容易さ」というわけで、そんなにクラスターがあっても仕方ないので「7」とします。
再度、クラスター数を「7」にして分析をします。その結果、一番多く分類されたクラスター2を選択してみました。

合わせて、特徴語も見てみましょう。

あとは定性データにクラスターのラベルをつけて、クラスター単位で集計するだけです。
ちなみにBOTTOM3が多かったのは、クラスター5だとわかりました。事例という言葉が多く並んでいて、「事例で理解できても導入するかどうかは別」だと身に沁みました。
②Rを使ったクラスター分析
次に、少しだけカスタマイズを効かせた手法です。
基本的な流れは①と同じですが、Rを使って過程を見ながら結論を出していきます。使用する定性データはそのままとします。
まず最初に、定性データの形態素解析を行い、出現頻度を確認します。その結果を元に行を作成し、それぞれ文中に何回登場するか確認します。この結果を元にユークリッド距離を求め、ウォード法によるクラスターのグラフを作成します。

library(RMeCab)
res <- RMeCabFreq("./survey1cluster.csv")
// 名詞だけを対象に絞り込み & 登場回数が2回以上
res.re <- res[res[,2]=="名詞" & res[,4] > 1,]
res.re[rev(order(res.re$Freq)),]
Term Info1 Info2 Freq
237 サイト 名詞 一般 24
233 イン 名詞 一般 24
379 こと 名詞 非自立 19
373 的 名詞 接尾 13
253 事例 名詞 一般 12
211 説明 名詞 サ変接続 9
197 理解 名詞 サ変接続 9
383 の 名詞 非自立 8
370 性 名詞 接尾 7
307 自分 名詞 一般 7
264 具体 名詞 一般 7「インサイト」が「イン」「サイト」に分裂している等ありますが、Freqから見て「インサイト」だろうと考えておきます。
Freq2回以上は80個ありましたが、なんやかんや確認して58個に収斂されました。その結果を横一列に並べます。そして、A列の文中に「インサイト」が何度登場するかを数えます。以下の関数を使います。何でもそのままではダメらしく、最後にCtrl+Shift+Enterを同時で押下しないとダメみたい。
=SUM(LEN($A2)-LEN(SUBSTITUTE($A2,B$1,"")))/LEN(B$1)

実際にはA列に定性データがありますが、代替テキストを表示しています。
表が完成したので、その結果でまずは樹形図(階層的クラスターグラフ)を作成します。定性データ(行)単位、単語(列)単位は以下の通り。
survey <- read.csv("./survey1cluster.csv",header=T,row.names=1,fileEncoding="utf-8")
sv.p<-survey/apply(survey,1,sum)
sv.ed<-dist(sv.p)
sv.hc<-hclust(sv.ed,"ward.D")
plot(sv.hc,hang=-1)
sv.t<-t(survey)
sv.cd<-dist(sv.t,"can")
sv.hc<-hclust(sv.cd,"ward.D")
plot(sv.hc,hang=-1,main="")
樹形図だけでなく、k-means法も使います。k-means法は実行する前にクラスタ数を指定しなければならないため、機械的に極めてしまいます。
> library(cluster)
> result <- clusGap(survey, kmeans, K.max = 10, B = 100, verbose = interactive())
Clustering k = 1,2,..., K.max (= 10): .. done
Bootstrapping, b = 1,2,..., B (= 100) [one "." per sample]:
.................................................. 50
.................................................. 100
> result
Clustering Gap statistic ["clusGap"].
B=100 simulated reference sets, k = 1..10
--> Number of clusters (method 'firstSEmax', SE.factor=1): 1
logW E.logW gap SE.sim
[1,] 3.670477 4.115241 0.4447637 0.01310425
[2,] 3.625306 4.051905 0.4265986 0.01361970
[3,] 3.570948 4.004465 0.4335172 0.01379836
[4,] 3.540026 3.964374 0.4243472 0.01419233
[5,] 3.496579 3.928506 0.4319275 0.01361033
[6,] 3.464444 3.894515 0.4300706 0.01339250
[7,] 3.413141 3.861969 0.4488280 0.01350555
[8,] 3.417032 3.832388 0.4153560 0.01354735
[9,] 3.358048 3.800941 0.4428929 0.01266548
[10,] 3.330389 3.771339 0.4409508 0.01305019この結果から、クラスターは7個とします。
求めるクラスタ数は、厳密に考えるなら gap(k) ≧ gap(k+1) - SE.sim(k+1) となる最小のkであり、k=7は条件に合致しません…。
sv.km<-kmeans(sv.p, 7)
sv.km$cluster
User1 User2 User3 User4 User6 User8 User9 User10 User11 User12 User13 User14 User15 User16 User17 User18
4 3 6 3 4 1 4 7 3 1 4 3 7 3 3 3
User19 User20 User21 User22 User23 User24 User25 User26 User27 User28 User29 User30 User31 User32 User33 User34
4 4 5 5 4 4 3 3 1 4 3 4 3 3 2 4
User35 User36 User37 User38 User39 User40 User41 User43 User44 User45 User46 User47 User48 User49 User50 User51
3 4 4 3 3 3 3 3 3 4 6 3 4 3 3 1
User52 User53 User54 User55 User56 User57 User58 User59 User60 User61 User62 User63
3 4 1 4 3 3 3 4 3 4 4 4それぞれのコメントが分類されたようです。あとは①同様に、結論設問をクラスタ単位で集計してみましょう。
アンケートに書かれた内容は信用できるのか?
突然ですが、こんなアンケート設問があったとします。
Q.あなたは今浮気していますか?
①している ②どちらかと言えばしている ③どちらとも言えない
④どちらかと言えばしていない ⑤していない
面白半分の回答が無い限り、その殆どが⑤で締められるでしょう。例え浮気をしている人でも、本心を打ち明けるわけがありません。
そう、アンケートには「本音と建前」があります。性格診断テストでも「ありのままの自分」ではなく「ありたい自分」を選んでしまって、全然違う診断結果になるのは、よくある話です。
それなのに、どうして「アンケートの結果です」と言われたら、それが全て本音のように見えるのでしょう。
例えばHRTech系には「従業員のモチベーションを見える化しましょう!」的なツールがたくさんありますよね。私は早晩HRTechの大半が行き詰まると思っているのですが、その理由は以前にこんなアンケート設問が投げられてきたからです。
Q.あなたの体調はどうですか?
| ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- |
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
0%〜100%まで10%刻みのプログレスバーみたいなのが表示されて、その中からどれかを選択するというものでした。
気でも狂ってるのかと思いました。誰だ、設計者はと思いました。
個人は特定されないとはいえ、精神的に参っていて0%なんかにしたら平均が下がって「犯人探し」が始まります。直ぐさま嫌いな上司と面談が実施され「最近どう?」みたいな他愛も無い会話で誤魔化しが行われるのです。そんなの地獄でしょうが。
だから私は、精神的に辛くても絶対に60%〜70%を選択していました。
HRtechの人たちは人事のプロかもしれませんが、アンケート設計や人間心理のプロではありません。こんなデータを元に「勘や経験に頼るマネジメントではなく、データに基づいた確かな分析」とか言われても「はぁっ?」と思っておりました。何が「THE TEAM」だ。
…話が脱線しました。
つまり、私たちデータサイエンティストは間違っているかもしれないデータで「こ分析をしなければならない、ということです。分析したけど何も出てこなかったのは、私たちの腕が悪いんじゃない、元のデータが「建前」だらけだからだとも言えます。
本来ならアンケートについては設計段階からデータサイエンティストが入り込んで、「建前」を除いた「本音の定性データ」が拾えるように取り仕切らなければならないのですが…果たしてリサーチ会社にもそこまでやれるリサーチャーってどれくらい居るのかは謎説を唱えたいです。
「顧客の声」を聞いているフリは、もう止めよう
そもそも、なぜ「顧客の声」を聞いているかと言えば「ビジネスを伸ばすヒントはお客様が知っている」からです。
では、顧客に「何が欲しいですか?」「何に困ってますか?」と聞いたら、ちゃんと答えてくれるんでしょうか。
「メニューが少ないから増やして欲しい」。じゃあメニューが増えたら、顧客の数も比例して増えるんでしょうか?
「値段が高いからもう少し安くして欲しい」。じゃあ値段が下がったら、顧客の数は反比例して増えるんでしょうか?
飲食店の皆さん始め大半のビジネスマンは「顧客の声」を聞いて実践したとても、さほど売上に影響を与えないと気付いているのではないでしょうか。
さすがに「店が汚い」「態度が悪い」みたいなPOFになりかねないクレームは聞くべきです。その意味で「売上の低下」は防げるのかもしれません。
「聞いている」というポーズを見せないと株主や上司が納得しないから、やむなく膨大なハガキ代を使い、データを収集した後は「せっかくだし何かやりますか」とデータサイエンス企業に200〜300万程度で発注し、「まぁこんなもんかな」という結果に納得している。
今までもやってきたし、そんなに大した結果も出ていないけど「顧客の声」自体を聞くのは決して悪いことじゃない…。
それは、顧客の声を聞いているのではなく、聞いたフリです。本当に顧客の声を聞きたいなら、心の鍵を開けて奥底に潜んでいる「本音」を引き出すぐらいじゃないと「聞いている」とは言えません。
C CHANNEL株式会社の森川さんは「シンプルに考える」という自著の中でLINE時代の経験談として消費者心理に迫った時の話をされています。
以前、ゲームをやめてしまったユーザーにその理由を尋ねたことがあります。すると、「飽きたから」と応えた人が非常に多かった。そこで、僕たちは「なぜ、飽きるんだろう?」と考えました。
そして、さらにユーザーに聞きました。すると、少しずつわかってくる。「飽きた」と言うけれど、実は、ゲームに負けたときにやめてしまう人が多かった。あるいは、お金でアイテムを買った人と戦ってイヤな気分になったという人もいました。
まさにアンケートでありますよね、「どうしてゲームを止めてしまったのですか?」という質問。

どうやって「ゲームに負けたときにやめてしまう」「お金でアイテムを買った人と戦ってイヤな気分になった」という理由に出会えたのかは謎ではありますが…そんな「顧客の声」に出会えるアンケートならお金を払う価値がありますよね。(ちなみにこの結果できたゲームがツムツムだそうです)
自分でも気付けていないがために言語化できておらず、「なんとなく」としか表現できない、無意識の奥に隠されている「理由」にアクセスできる聞き方ならアンケートも意味はあるでしょうが、それが無ければ大半は単なる建前データでしかないでしょう。
だから、最初に申し上げました。「問題は、どんな風に聞くかです」と。
私たちは今、こういう世界に生きています。氷山の上に立ち、目に見える範囲でしかペンギンを数えていないのです。

本当は、水中にダイブし氷山全体(心理全体)を捉え、目に見えなかったペンギンも数えられるマーケターにならなければいけません。或いは、そうした全体像を捉えられるアンケートで無ければ、顧客の声を拾えられると言えないと私は思っています。
だから、「お客様の声を聞くアンケート」の分析、どうせならデコムに発注して下さいとお願いしたいのです。
今までの惰性で定性データの分析に200万〜300万払うぐらいなら、インサイトリサーチのプロフェッショナルであるデコムなら同金額で、先ほどの森川さんの書籍にあったような止めた本質的な理由にまで(高確率で)たどり着けます!
ホンマでっせ!
今回は少し長くなってしまいましたが、ある日「言っていることは分かるんだけど〜、やっぱ今までやってた案件だから〜、予算が〜」と言われたことに腹を立てて、土曜日1日かけて書き殴りました。
無駄とわかってて消化する予算ならワシらに来れ!
お粗末様でした。
1本書くのに、だいたい3〜5営業日くらいかかっています。良かったら缶コーヒー1本のサポートをお願いします。