
bzip2を読む ブロックソート5

こんにちは、junkawaです。
本記事では、前回に続きブロックソートアルゴリズムの「巡回行列のソート」についてソースコードを交えて紹介します。
前回の記事
bzip2を読む はじめに
bzip2を読む ブロックソート1
bzip2を読む ブロックソート2
bzip2を読む ブロックソート3
bzip2を読む ブロックソート4
前回までのおさらい
巡回行列のソートでは、下記の1. 2. を行います。
1. 先頭の2バイトでソート
2. 先頭バイトのシンボルの出現頻度が少ない順に下記を行う
(3バイト目以降のソート)
Step1) 先頭2バイトが異なる値、の行をソート
Step2) 先頭2バイトが同じ値、の行をソート
Step3) ソート高速化のための情報を更新
本記事では、「先頭2バイトが異なる値、の行をソート」について、実際にソートを行う部分を紹介します。
先頭2バイトが異なる値、の行をソート
ソートには、マルチキークイックソート を使用します。
これは、論文 “Fast Algorithm for Sorting and Searching Strings” J.L.Bentley and R.Sedgewick. で紹介されています。
一般的なクイックソートは数値などをソート対象としており、基準値(ピボット)未満(or以下)と以上(orより大きい)の2つに分割して、それぞれの領域に対して再度クイックソートを行います。
マルチキークイックソートでは、基準値未満、基準値と同じ、基準値より大きいの3つに分割して、それぞれの領域に対して再度クイックソートを行います。文字列をソート対象としているので、基準値と同じ領域では、次の文字を比較対象として使います。

ソースコード紹介
GitHubでソースコードを公開しています。
mainQSort3()@blocksort.c L559 〜 L717
559: /*--
560: The following is an implementation of
561: an elegant 3-way quicksort for strings,
562: described in a paper "Fast Algorithms for
563: Sorting and Searching Strings", by Robert
564: Sedgewick and Jon L. Bentley.
565: --*/
566:
前述の論文についての説明です。
3-way quicksort for strings というのが、マルチキークイックソートのことです。
567: #define mswap(zz1, zz2) \
568: { Int32 zztmp = zz1; zz1 = zz2; zz2 = zztmp; }
569: zz1とzz2を入れ替えます。
570: #define mvswap(zzp1, zzp2, zzn) \
571: { \
572: Int32 yyp1 = (zzp1); \
573: Int32 yyp2 = (zzp2); \
574: Int32 yyn = (zzn); \
575: while (yyn > 0) { \
576: mswap(ptr[yyp1], ptr[yyp2]); \
577: yyp1++; yyp2++; yyn--; \
578: } \
579: }
580: 
zzp1〜zzp1+zzn-1と、zzp2〜zzp2+zzn-1の領域を交換する。
581: static
582: __inline__
583: UChar mmed3 ( UChar a, UChar b, UChar c )
584: {
585: UChar t;
586: if (a > b) { t = a; a = b; b = t; };
587: if (b > c) {
588: b = c;
589: if (a > b) b = a;
590: }
591: return b;
592: }
593: a,b,c の中で中間の値を返します。
594: #define mmin(a,b) ((a) < (b)) ? (a) : (b)
595: a,b の小さい方の値を返します。
596: #define mpush(lz,hz,dz) { stackLo[sp] = lz; \
597: stackHi[sp] = hz; \
598: stackD [sp] = dz; \
599: sp++; }
600: 3つのスタック、stackLo、stackHi、stackDへデータを積みます。
スタックポインタspをインクリメントします。
601: #define mpop(lz,hz,dz) { sp--; \
602: lz = stackLo[sp]; \
603: hz = stackHi[sp]; \
604: dz = stackD [sp]; }
605:
606: スタックからデータを取り出します。
スタックポインタspをデクリメントします。
607: #define mnextsize(az) (nextHi[az]-nextLo[az])
608: スタックに積むmpush()3つの領域(next*[0]、next*[1]、next*[2])の、ソート対象の領域az(0〜2)のサイズ(hi-lo)を取得します。
(next* は、nextHi、nextLo、nextDのこと)
706〜708行で使用します。
609: #define mnextswap(az,bz) \
610: { Int32 tz; \
611: tz = nextLo[az]; nextLo[az] = nextLo[bz]; nextLo[bz] = tz; \
612: tz = nextHi[az]; nextHi[az] = nextHi[bz]; nextHi[bz] = tz; \
613: tz = nextD [az]; nextD [az] = nextD [bz]; nextD [bz] = tz; }
614:
615: スタックに積むmpush()3つの領域next*[]を入れ替えます。
706〜708行で使用します。
616: #define MAIN_QSORT_SMALL_THRESH 20ソート対象の、比較する行数がMAIN_QSORT_SMALL_THRESH未満の場合、クイックソートをやめて、シェルソート(mainSimpleSort())を行います。
617: #define MAIN_QSORT_DEPTH_THRESH (BZ_N_RADIX + BZ_N_QSORT)ソート対象がMAIN_QSORT_DEPTH_THRESH+1文字、先頭から一致する場合、クイックソートをやめて、シェルソートを行います。
bzlib_private.h:L187
#define BZ_N_QSORT 12
となっています。
618: #define MAIN_QSORT_STACK_SIZE 100
619: クイックソートを再帰ではなく、スタックで実装します。
スタックのサイズはMAIN_QSORT_STACK_SIZEです。
620: static
621: void mainQSort3 ( UInt32* ptr,
622: UChar* block,
623: UInt16* quadrant,
624: Int32 nblock,
625: Int32 loSt,
626: Int32 hiSt,
627: Int32 dSt,
628: Int32* budget )
629: {ptr
入力:ptr[loSt..hiSt]の範囲で、ブロック番号 ptr[i] (block[ptr[i]]) から始まる(巡回行列の)行をソートする。
出力:ソート結果をptrに格納する。
block
入力:入力データブロック
quadrant
入力:同じ入力文字、同じ入力パターンが連続する場合、比較に時間がかかるが、これを避けて高速に比較できるようにする情報。
nblock
入力:blockのサイズ。block[0..nblock]。nblockは最大で900,000。
loSt
入力:ソート対象の、ptr の下限インデックス。
hiSt
入力:ソート対象の、ptr の上限インデックス。
dSt
入力:先頭2バイトはすでにソート済みなので、3バイト目(インデックスでは0,1,2の2)からソートを始める。そのための値として呼び出し元ではBZ_N_RADIX(2)を入れています。
budget
入力、出力:同じ入力文字、同じ入力パターンが連続する場合、クイックソートだと時間がかかるので、別のソート方法(fallbackSort())に切り替える必要がある。そのためのカウンタ。
630: Int32 unLo, unHi, ltLo, gtHi, n, m, med;
631: Int32 sp, lo, hi, d;
632: ローカル変数です。後で紹介します。
633: Int32 stackLo[MAIN_QSORT_STACK_SIZE];
634: Int32 stackHi[MAIN_QSORT_STACK_SIZE];
635: Int32 stackD [MAIN_QSORT_STACK_SIZE];
636: クイックソートを再帰ではなくスタックに積むことでループとして実装しています。
stackLo[]、stackHi[]はソート対象の領域の下限と上限です。ptr[starkLo[i] .. starkHi[i]] の範囲をソートします。
stackD[]は、先頭から何文字目を比較するかを表します。文字 block[ ptr[j] + stackD[i] ]を比較します。
637: Int32 nextLo[3];
638: Int32 nextHi[3];
639: Int32 nextD [3];
640: クイックソートで3つの領域をスタックに積む前に並べ替える(706〜708)時に使用する配列。
641: sp = 0;
642: mpush ( loSt, hiSt, dSt );
643: 初期値としてスタックに、loSt、hiSt、dStをセットします。

mpush()では、loSt、hiSt、dStをスタックにセット後、spを1増やします。
644: while (sp > 0) {
645: spが0になる時は、全てのソートが終わった時です。
646: AssertH ( sp < MAIN_QSORT_STACK_SIZE - 2, 1001 );
647: sp >= 98 (MAIN_QSORT_STACK_SIZE - 2) の時、アサートします。
stackLo[0..99] なので、spが100の時にmpush()するとオーバーフローします。
spが98の時、本whileループでは、mpop()が1回、その後にmpush()が3回発生するのでspが99でmpush()することになります。
まだオーバーフローする段階ではないですが、余裕をもってアサートしているものと思われます。
ちなみにアサート時はexit()でプログラムを終了します。
648: mpop ( lo, hi, d );スタックからlo、hi、dを取り出します。
lo、hiはソート対象の領域の下限と上限です。ptr[lo .. hi] の範囲をソートします。
dは、先頭から何文字目を比較するかを表します。文字 block[ ptr[j] + d ]を比較します。
649: if (hi - lo < MAIN_QSORT_SMALL_THRESH ||
650: d > MAIN_QSORT_DEPTH_THRESH) {ソート対象の数(hi-lo)が、MAIN_QSORT_SMALL_THRESH(20)未満の場合、もしくは先頭からの一致文字数がMAIN_QSORT_DEPTH_THRESHより大きい場合、対象のソート方法をmainSimpleSotr()に切り替えます。
ソート対象の数(hi-lo)が小さい場合や、一致部分が長くなると、クイックソートよりもシェルソートの方が高速になるために、切り替えていると思われます。

651: mainSimpleSort ( ptr, block, quadrant, nblock, lo, hi, d, budget );シェルソート mainSimpleSort () を実行します。
652: if (*budget < 0) return;budgetは、ソート中に比較する2つの行の内容が同じ場合(入力データが同じ値や、同じパターンが繰り返される場合など)に、減算されるカウンタです。
初期値は BZ2_blockSort()でセットされ、mainGtU()で減算されます。
同じデータが繰り返される場合、高速化のために呼び出し元のmainSort()ではなくfallbackSort()を使用します。
したがって、budgetが0より小さくなった場合にmainQSort3()でのソートをやめ、BZ2_blockSort()まで戻り、fallbackSort()を実行します。
653: continue;ptr[lo..hi]の範囲について、mainSimpleSort()でソートが完了したので、スタックに積まれている次の範囲をソートするためにcontinueします。
654: }
655: 以下は、mainSimpleSort()ではなく、クイックソートする処理です。
656: med = (Int32)
657: mmed3 ( block[ptr[ lo ]+d],
658: block[ptr[ hi ]+d],
659: block[ptr[ (lo+hi)>>1 ]+d] );
660: med はmedium(中間)だと思われます。
中間値medを基準値(ピボット)として、ピボットより小さい領域、ピボットに一致する領域、ピボットより大きい領域、の3つに分割して、それぞれに再度クイックソートを適用します。
block[ptr[lo]]、block[ptr[hi]]、block[ptr[(lo+hi)>>1]]はそれぞれ、
ptr上での、下限、上限、中間((lo+hi)/2)の位置の(巡回行列の)行の先頭ブロック番号を指します。
dは行の先頭からの距離で、今回比較を行う文字を指定します。
dの初期値(mainQSort3()の引数)は2となり、先頭から0,1,2 と3バイト目の文字を比較します。
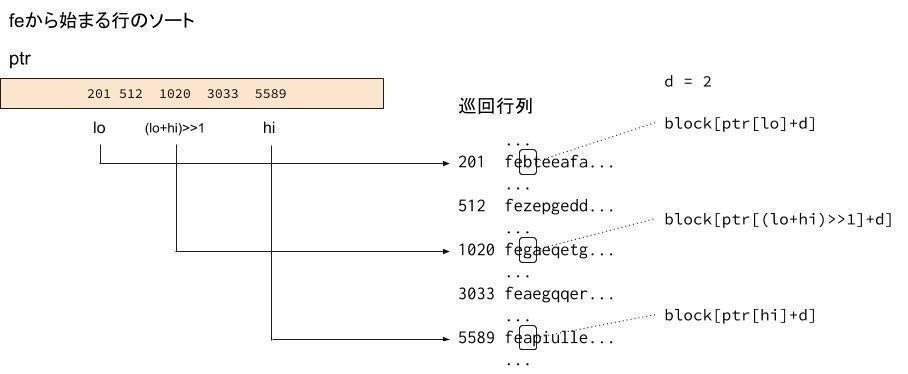
図では、説明を簡単にするために、シンボルをアルファベットに限定しています。実際は、0〜255の値となります。
図では、block[ptr[lo]+d] の b、block[ptr[(lo+hi)>>1]+d] の g、block[ptr[hi]+d] の aとなっています。これを mmed3(b, g, a)とすると、中間値 b が得られます。
661: unLo = ltLo = lo;
662: unHi = gtHi = hi;
663:

3つの領域に分割するための区切りの変数unLo、ltLo、unHi、gtHiの初期値をセットする。
664: while (True) {ここでは、4つの領域(ピボットと一致、ピボットより小さい、ピボットより大きい、ピボットと一致)に分割する。
このループを抜けたところで、最初と最後のピボットと一致する領域を結合し、3つの領域(ピボットより小さい、ピボットと一致、ピボットより大きい)にします。
最初の4つの領域に分割するこの方法は前述の論文を参考に実装されています。
665: while (True) {
666: if (unLo > unHi) break;
667: n = ((Int32)block[ptr[unLo]+d]) - med;
668: if (n == 0) {
669: mswap(ptr[unLo], ptr[ltLo]);
670: ltLo++; unLo++; continue;
671: };
672: if (n > 0) break;
673: unLo++;
674: }

ptr[unLo]に対応する文字(block[ptr[unLo]+d])がmedより小さい場合、unLoを右に進めます(673行目)。この時、ltLoはmedより小さい文字を指しています。
medに一致する場合(668行目)、unLoとltLoを入れ替えます。unLo>=ltLoとなっているので、medに一致する値はlo側にセットされ、medより小さい値はunLo側にセットされます。
medより大きい場合、ループから抜けます(672行目)。

unHiを超えた場合、そこはすでにmedより大きい領域、またはhi(hi=unHiの時)を超えた領域なので、ループを抜けます。
直感的には、medより小さい、medに一致の順に並べ替えますが、ここではmedに一致、medより小さい、の順に並べ替えます。696行目でmedより小さい、medに一致の順に並べ直します。
675: while (True) {
676: if (unLo > unHi) break;
677: n = ((Int32)block[ptr[unHi]+d]) - med;
678: if (n == 0) {
679: mswap(ptr[unHi], ptr[gtHi]);
680: gtHi--; unHi--; continue;
681: };
682: if (n < 0) break;
683: unHi--;
684: }

ptr[unHi]に対応する文字(block[ptr[unHi]+d])がmedより大きい場合、unHiを左に進めます(683行目)。この時、gtHiはmedより大きい文字を指しています。
medに一致する場合(678行目)、unHiとgtHiを入れ替えます。unHi<=gtHiとなっているので、medに一致する値はhi側にセットされ、medより大きい値はunHi側にセットされます。
medより小さい場合、ループから抜けます(682行目)。

unLoを超えた場合、そこはすでにmedより小さい領域、またはlo(lo=unLoの時)を超えた領域なので、ループを抜けます。
直感的にはmedに一致、medより大きい、の順に並べ替えますが、ここではmedより大きい、medに一致、の順に並べ替えます。697行目でmedに一致、medより大きいの順に並べ直します。
685: if (unLo > unHi) break;unLo > unHi が成立する時、領域に振り分ける要素がないので、whileループを抜ける。
686: mswap(ptr[unLo], ptr[unHi]); unLo++; unHi--;
686行目の時点で、ptr[unLo]はmedより大きい、ptr[unHi]はmedより小さい、となっています(図の上部)。
unLoとunHiを入れ替えると、medより小さい領域とmedより大きい領域をそれぞれ拡張することができます(図の下部)。
687: }
688:
689: AssertD ( unHi == unLo-1, "mainQSort3(2)" );
690: 上記のwhileループを抜けた時は、unHiとunLoは隣接し、unLo > unHi となることが期待されます。これを満たさない場合、アサートします。
691: if (gtHi < ltLo) {
692: mpush(lo, hi, d+1 );
693: continue;
694: }
695:

gtHi < ltLoとなるのは、loからhiまでの全てのソート対象がmedに一致した場合です。
この場合、同じ領域(lo..hi)にたいして、次の文字を比較する必要があるので、d+1としてmpush()し、continueして再度クイックソートを行います。
696: n = mmin(ltLo-lo, unLo-ltLo); mvswap(lo, unLo-n, n);


medに一致する領域とmedより小さい領域を入れ替えます。
medに一致する領域のサイズ(ltLo-lo)とmedより小さい領域のサイズ(unLo-ltLo)の小さい方のサイズ分だけ入れ替え対象とします。
697: m = mmin(hi-gtHi, gtHi-unHi); mvswap(unLo, hi-m+1, m);
698:


medに一致する領域とmedより大きい領域を入れ替えます。
medに一致する領域のサイズ(hi-gtHi)とmedより大きい領域のサイズ(gtHi-unHi)の小さい方のサイズ分だけ入れ替え対象とします。
大きい方のサイズで入れ替えても、動作に支障は起きませんが、無駄な入れ替え(一致する領域から一致する領域への入れ替え、大きい領域から大きい領域への入れ替え)が発生してしまいます。
699: n = lo + unLo - ltLo - 1;
700: m = hi - (gtHi - unHi) + 1;
701:
702: nextLo[0] = lo; nextHi[0] = n; nextD[0] = d;
703: nextLo[1] = m; nextHi[1] = hi; nextD[1] = d;
704: nextLo[2] = n+1; nextHi[2] = m-1; nextD[2] = d+1;
705:

3つの領域を配列にセットします。
medより小さい領域: next*[0]
medより大きい領域: next*[1]
medに一致する領域: next*[2]
medより小さい領域のサイズはunLo-ltLoです。medより小さい領域の先頭はlo、最後はlo+unLo-ltLo-1(=n)となります。
medより大きい領域のサイズはgtHi-unHiです。medより大きい領域の最後はhi、先頭はhi-(gtHi-unHi)+1(=m)となります。
medに一致するサイズの先頭は、medより小さい領域の最後の要素の次。つまり、n+1となります。
medに一致するサイズの最後は、medより大きい領域の先頭の要素の前。つまり、m-1となります。
medより小さい領域と大きい領域では、同じ位置の文字を比較するので、nextD[0]、nextD[1]をdとします。
medに一致する領域では、文字列の次の文字を比較するので、nextD[2] に d+1としています。
706: if (mnextsize(0) < mnextsize(1)) mnextswap(0,1);
707: if (mnextsize(1) < mnextsize(2)) mnextswap(1,2);
708: if (mnextsize(0) < mnextsize(1)) mnextswap(0,1);
709:

next*[0]に一番大きい領域、next*[2]に一番小さい領域になるように入れ替えします。
上記図の上部では、領域のサイズの順番を、medに一致する領域 > medより大きい領域 > medより小さい領域、としています。
上記図の下部は706〜708行の処理を行った後のnext*配列の内容です。
next*[0]にmedに一致する領域、next*[1]にmedより大きい領域、next*[2]にmedより小さい領域をセットしています。
710: AssertD (mnextsize(0) >= mnextsize(1), "mainQSort3(8)" );
711: AssertD (mnextsize(1) >= mnextsize(2), "mainQSort3(9)" );
712: 706〜708の入れ替えが正常に行われなかった時、アサートします。
713: mpush (nextLo[0], nextHi[0], nextD[0]);
714: mpush (nextLo[1], nextHi[1], nextD[1]);
715: mpush (nextLo[2], nextHi[2], nextD[2]);706〜708 の入れ替えにより、mpush()される順序は領域のサイズが大きい順番([0]、[1]、[2])となります。逆に、次回のwhileループでmpop()してソートする順番は領域が小さい順番([2]、[1]、[0])になります。

サイズの小さい領域を優先的にソートすることで早めにソートを完了させ、スタックに積む回数が増えないようにしていると思われます。
716: }
717: }
まとめ
マルチキークイックソートを使って、巡回行列をソートする方法を紹介しました。
次回はシェルソートによる比較方法を紹介します。
ご覧下さりありがとうございます。いただいたサポートは図書館への交通費などに使わせていただきます。