
“ラベルレス飲料”のメリットって何? 第3回 ~データを”パーティション”する:ラベルレスを推奨する人/推奨しない人の属性は~

増川 直裕
■探偵のように
アンケート調査では、総合的な満足度に影響を及ぼすような、回答者の属性や回答を調べるといったことがあります。
例えば、飲料会社が新しい飲料のアンケート調査を行う際、「この飲料を他人に勧めますか?(勧める/勧めない)」といった満足度に関する選択肢があったとき、ある程度の回答が集まっていれば、勧めたいと答えた人はどのような属性の人なのかを知ることができるのです。
分析した結果として、”30代以下の女性で、過去に同社の類似製品を買っていて、普段から健康に気をつけている方“ の満足度が高いといったようなことが分かります。
ラベルレス飲料に関する記事は、今回で3回目になります。前回の第2回では、主成分分析から得られる回答者の主成分スコアを求めることにより、ラベルレスの推奨度をスコア(値が高いほど、ラベルレスを推奨している)で考えることにしました。下図の列「主成分1(ラベルレススコア)」がそれに該当します。

今回は、このスコアを用いて、ラベルレスを推奨する人は(または推奨しない人は)どのような属性の人なのかを、統計手法を用いて探索的に調べていくことにします。
以降の分析における目的変数(Y) と説明変数(X) は、次のようにします。
目的変数(Y) : ラベルレススコア(連続値)
説明変数(X):性別、年代、業界(食品/飲料業界、それ以外)、ラベルレス飲料を知っていたか、ラベルレス飲料の購入歴
このとき、目的変数(Y) に影響を及ぼす説明変数(X) を見つけていくことになります。そのための統計的なアプローチとして、回帰モデルをあてはめる、機械学習的な複雑なモデルをあてはめるなど、さまざまなアプローチが考えられますが、ここでは、JMPのパーティションという手法を用いることにします。
この方法、何といっても、犯人捜しに向いているのです・・・。
パーティションは、一般的な統計手法名ですとディシジョンツリー、または決定木分析と呼ばれている手法に相当します。
オフィスにあるパーティションを連想してください。パーティションを使うことにより、空間を小さく分けることができますよね。
同様に、探偵が何かを発見するために、手がかりを使って捜索範囲を狭くするような感覚なのです。
そう、分析者が探偵になったかのように、原因を見つけてみましょう。

■パーティションの実行
パーティションで、Yの変数とXの変数を指定し、最初に表示されるレポートを示します。
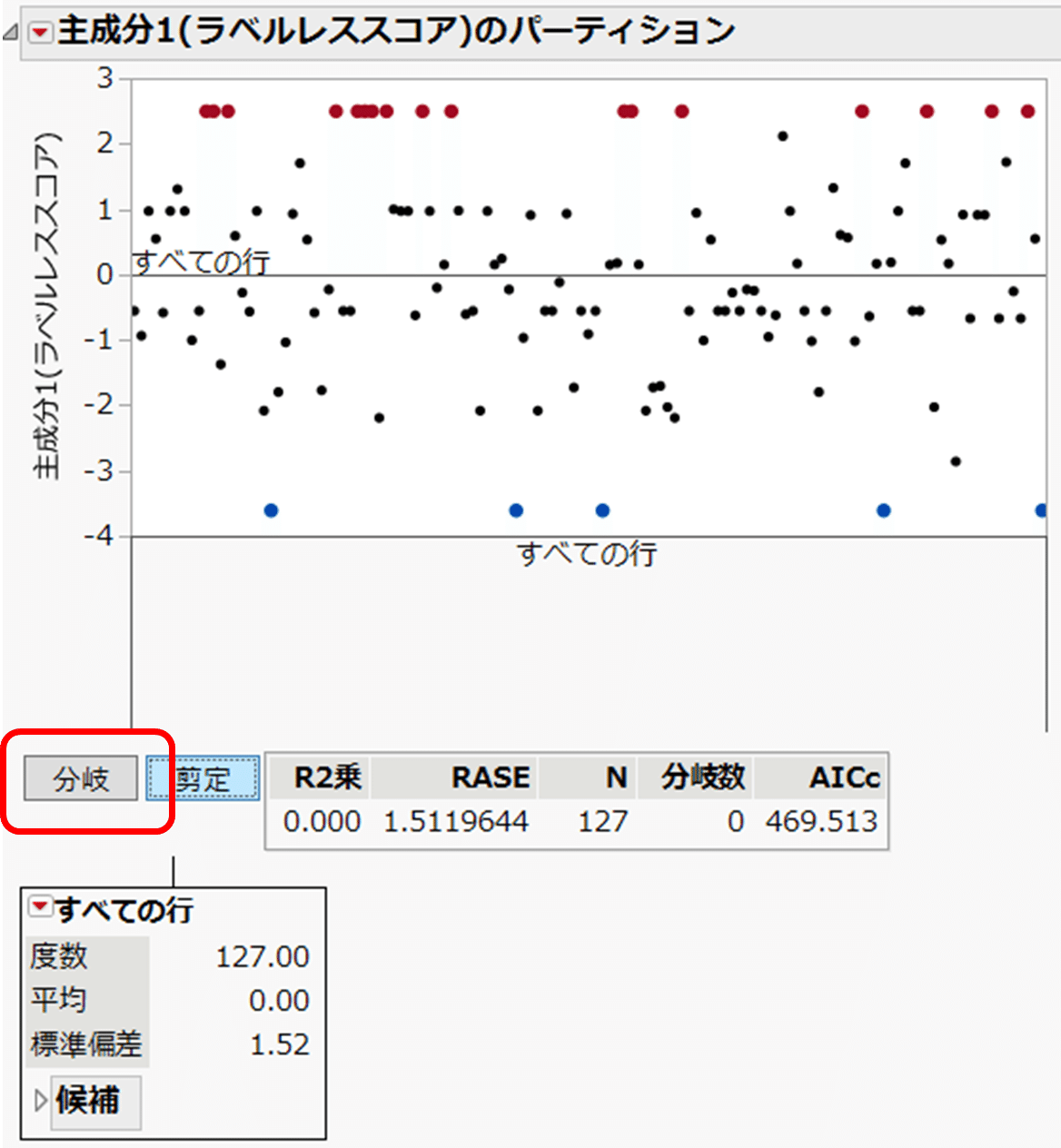
上側に表示されるグラフは、各回答者のラベルレススコアを縦軸に示したものです。現時点で横軸に意味はありません。Y=0に参照線が引かれていますが、ラベルレススコアの平均値になります。(主成分スコアの平均は0になるように基準化されているからです。)
左下の「すべての行」は、127人が1つのグループにまとまっている状態を示しています。これから、このグループをどんどん2つのグループに分けていくのです。
赤枠で示した [分岐] ボタンを1回クリックしてみます。

上側のグラフでは、横軸が年代で分かれたのが分かりますね。(20代、30代、40代) の参照線と、50代以上の参照線のY座標に差が出てきていますね。これが、2つのグループに分けた結果なのです。
赤枠で示したのが、2つのグループに分けた結果です。
右側のグループ:50代以上、該当する回答者は31名で、ラベルレススコアの平均は、 -0.59
左側のグループ:20代~40代:該当する回答者は96名で、ラベルレススコアの平均は、0.19
左側のグループと右側のグループでは、スコアの平均に隔たりが出てきています。実際にJMPでは、(統計的検定における)平均の差が大きくなるような、変数とその値を見つけ、2つのグループに分けるのです。
ということは、年代がラベルレススコアに影響している変数とも考えられます。
50代以上だとラベルありの方がよく、それ未満だとラベルレスでも良いといったことが考察できます。
■さらに分岐してみると
もう1回、[分岐] ボタンをクリックしてみます。
今度は、50代以上のところが、さらに2つのグループに分かれました。

上図の赤枠で囲んだグループは、(50代以上) かつ (食品/飲料業界以外)の回答者です。この時のラベルレススコアは -1.08 とかなり低くなります。このグループは、ラベルレススコアが低いので、ラベルありの方が良いと考えていることになります。
“食品/飲料業界で年配の方は、ラベルありの方が良いと回答された” という結果は、あまり筆者の直感にはした。
このように、分岐を繰り返していけば、分析者で自分の知識や直感と照らし合わせて、その結果は妥当なのか、それとも今まで知らなかった見解なのか考えながら、いわば探偵のように要因を見つけることができるのです。
さらに分岐を行い、6回分岐した時のレポートを示します。
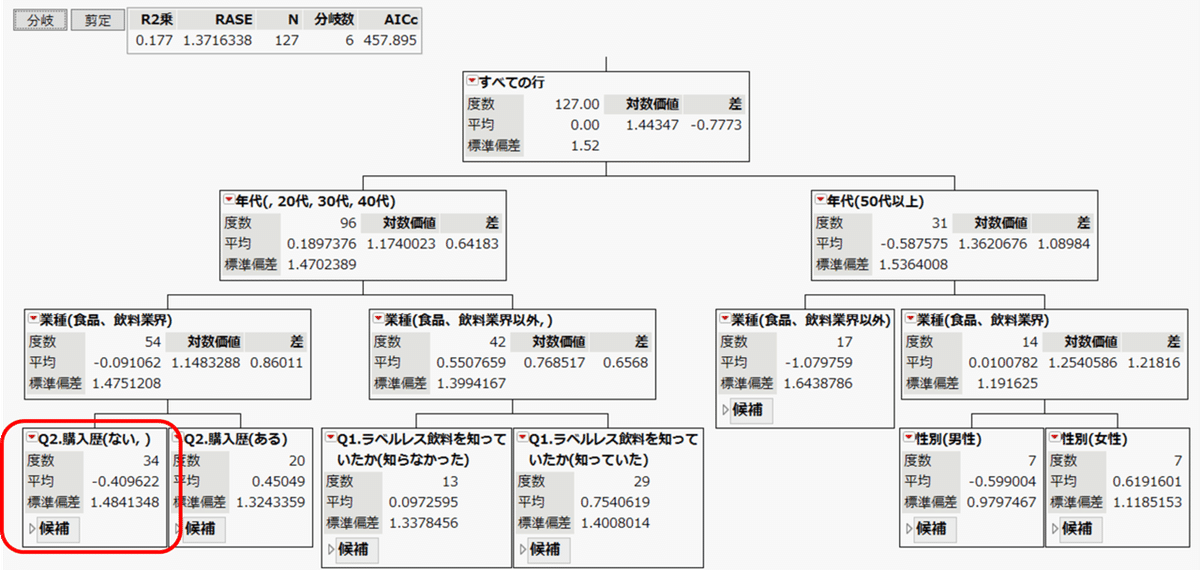
左下の赤枠で囲んだグループは、食品/飲料業界の20代~40代で、ラベルレス飲料の購入歴がない方で、ラベルレススコアの平均は -0.41 となります。
購入歴がないグループと、購入歴があるグループで比較した場合に、購入歴があった方がラベルレススコアは高くなるというのは納得がいきそうです。もともとラベルレスを推奨していたから、購入したとも考えられますが。
■結局、どの変数が影響しているのか
これまでに示したように、JMPのパーティションでは、分岐ボタンをクリックすることによって、対話的な要因分析を行うことができたのですが、何回も分岐すると、結局のところ、どの説明変数(X)が目的変数(Y)に影響してるのか、よくわからなくなってしまいます。
そのようなとき、「列の寄与」というオプションを使うと、分岐に関する統計量を用いて、各説明変数の寄与割合を示すことができます。

右側には寄与割合が表示されていますが、これによると業種、年代、購入歴、性別、ラベルレス飲料を知っていたか の順にラベルレススコアに影響していることを示しています。
パーティションの統計的背景は少し複雑なのですが、結果を解釈するだけであれば、非常に分かりやすい手法なので、多くのJMPユーザの方が活用しています。
是非とも、読者の皆様のデータでも、試してみてください。そう、探偵になったつもりで。
さあ始めましょう。最新版JMP 15 のダウンロードは下から!
この記事が気に入ったらサポートをしてみませんか?