
1位「香川郡直島町」,2位「上北郡六ヶ所村」,3位「南都留郡忍野村」…これは,何の順位でしょう?

この記事を読んでいただきたい方
* Excel でデータのレポートを作成している人
* Excel で作られたレポートを見る仕事をしている人
* Excel でデータ分析を行っている人
* ALZETA でのデータ処理に興味を持っている人
前回の記事で予告した通り,ALZETA の説明を行いながら,データを動かして自在に活用するということはどういうことかを説明します.今回は,政府から公開されている二つのデータをネタにします.
1. データの取得
『平成28年経済センサス-活動調査 産業別集計(製造業)「市区町村編」統計表データ 』の取得
経済産業省の「役に立つ統計情報」というページから,「経済センサス-活動調査」というページに飛び,「市区町村編」の Excel ファイルをダウンロードします.(ファイル名: h28t_shikutyo.xls)

ファイルの内容は,こうなっています.

かっちり整理されたレポートです.このファイルに手を加えることは少し憚られる気がしませんか?手を加えられることを想定したファイルではありませんので,全く問題ではないのですが,このデータを「死蔵」せず「活用」できるかというとどうでしょうか?
この表はピンポイントの数字を知りたい場合には有効でしょう.たとえば,「東京都大田区」の「電気機械器具製造業」の「事業所数」と「製造品出荷額」を知りたいという要求にはすぐ応えてくれます.
しかし,この表全体を眺めて,何かデータの傾向を読み取ろうとしても,なかなか難しいのではないでしょうか.(例えば,単純に製造品出荷額のカラム「L」でレコードをソートしようとしても,「この操作を行うには,すべての結合セルを同じサイズにする必要があります.」と怒られてしまったりします)
『【総計】令和2年住民基本台帳人口・世帯数、令和元年人口動態(市区町村別)』の取得
先ほどの経産省のデータ一つをあれこれ操作するよりも,他のデータとぶつけると,データ活用の幅が広がります.データをぶつけるというのは,データを動かす中で最もドラマティックな効果が期待できる,大事な行為です.
今回は,総務省の「住民基本台帳に基づく人口、人口動態及び世帯数」というページから,『【総計】令和2年住民基本台帳人口・世帯数、令和元年人口動態(市区町村別)』の Excel ファイルをダウンロードします.(ファイル名: 000701582.xls)

その内容は,下のとおりです.

2. ALZETA 用の前加工
ALZETA には CSV や Excel ファイルのデータを読み込めますが,注意点が三つあります.
* (CSV,Excel 共通)最初の一行目は,データ項目名として解釈されます
* (Excel のみ)拡張子が「.xlsx」である, Excel 2007 以降の形式の Excel ファイルでなくてはなりません
* (Excel のみ)ブックに複数シートがある場合,最初のシートしか読み込みません
これも考慮して,1. でダウンロードした二つのファイルを以下のように加工します.
『平成28年経済センサス-活動調査 産業別集計(製造業)「市区町村編」統計表データ 』(h28t_shikutyo.xls)の加工
シート「第2表」だけにして,1行目の加工を行い,xlsx 形式で保存します.このとき,ファイル名も「平成28年経済センサスー産業別集計(製造業)市区町村編.xlsx」と変更します.

『【総計】令和2年住民基本台帳人口・世帯数、令和元年人口動態(市区町村別)』(000701582.xls)の加工
令和2年の人口/世帯数のデータだけ(G列まで)を取り出し,ファイル名も「【総計】令和2年住民基本台帳人口・世帯数(市区町村別).xlsx」と変更しています.

3. ALZETA へのログイン
ALZETA は Web アプリケーションです.Web ブラウザでアクセスし,ユーザーID,パスワードを入力します.

4. ALZETA へのデータのアップロード
ログインしたら,「データソース管理」→「入力ファイル管理」の「アップロード」ボタンを押しますと,データのアップロードのための対話画面が出てきます.ここで,先ほど作成した「平成28年経済センサスー産業別集計(製造業)市区町村編.xlsx」をアップロードします.

同じように,「【総計】令和2年住民基本台帳人口・世帯数(市区町村別).xlsx」をアップロードします.
結果,二つのファイルが「入力ファイル」として登録されました.ファイルの名前は,アップロードした Excel ファイル名から「.xlsx」拡張子を除いたものになります.

加えて,表中の「選択」欄を操作して,「JOB使用」印をつけておきます.

5. ALZETA でデータを動かす
ここまでくると,ALZETA の中でオリジナルのファイルを全く損なわないまま,データの操作ができます.Excel ではファイルに変更を加えると,それは直ちにデータのオリジナル性が損なわれたということになります.Excel ではこれを嫌って,「読み取り専用」や「変更用ファイルをコピーして作成する」ということをやります.一方,ALZETA ではデータを操作するたびに,内部でファイルを別に作りますので,オリジナルのファイル自体には全く変更がありません.
具体的に,ALZETA でのデータ操作のやり方を見てみましょう.「コックピット」画面を表示し,「ID・CD(入力系)」から「入力ファイル」を選んで,キャンバスにドラッグ&ドロップし,ダブルクリックします.

「平成28年経済センサスー産業別集計(製造業)市区町村編」の「プレビュー」の「通常」の虫眼鏡をクリックすると,データの内容が見られます.なおここで見られるのはデータの最初の100件までです.

プレビューしたら元の画面に戻り,「平成28年経済センサスー産業別集計(製造業)市区町村編」のファイル名部分をクリックして,当該データを使用すると決定します.(決定したら,アイコンの名前が変わります)

ここで,普段目にしない「産業分類(コード・名)」というデータ項目に注目して,一体どのような分類があり得るのか見てみます.
「並替」を接続してダブルクリックし,項目「産業分類コード」「産業分類名」を選択します.

その先に「ソート」を接続し,項目「産業分類コード」「産業分類名」でソートするよう設定します.

最後に,「ユニーク」を接続し,その先に「中間ファイル」をつなげてダブルクリックします.

すると,以下のような結果が得られます.このプレビューの表示上限は100件ですが,今回表示されたデータは25件(スクリーンショットでは25件目だけ表示範囲外です.スクロールすると見られます)なので,「産業分類(コード・名)」のバリエーションはこの25通りだということがわかりました.

今回「ソート」を挟みました.なぜでしょう.ソートを挟まずに,「ユニーク」を接続して「中間ファイル」でプレビューしてみます.

出てきた結果は,所望の結果と異なります.例えば1件めの「00 製造集計」が19件目にも出現しています.

これは,「ユニーク」の動作原理によります.「ユニーク」は上からレコードを読んでいき「ひとつ前のレコードと,今のレコードを比較して,内容が違っていたら(ユニーク:唯一のデータだと判断して)出力する」という動作をします.もちろん,全レコードを読み込んだ後に,全レコードを互いに比較してユニークなレコードを出力するという動作原理もあり得ますが,この方法だと2レコードづつ比較を行うだけで処理が完結するという計算量と,一度に高々2レコードしかメモリに記憶しなくて良いというメモリ使用量上のメリットがあります.
参考までに,「ソート」だけを通過した状態を「中間ファイル」で見てみましょう.


一目瞭然かと思います.
なおここまでで,2系統余計なフローの分岐を作ってしまいましたが,最初に良い結果を得た本流のフローの動きはそのままで,何ら影響を受けません.このように,処理の随所で違う処理を分岐させて違うパターンのデータ処理を試したり,「中間ファイル」を接続して,自由に処理の様子を観察できるのも,ALZETA の特徴の一つです.Excel で同じようなことをやろうとすると,一つのブックにワークシートが幾つもできてしまい,難儀すると思います.
確認のために作ったフローの分岐を取り外し,最後に「Excel出力」を接続して,このデータを「産業分類一覧.xlsx」に保存するようにします.

また,JOB名を『「平成28年経済センサスー産業別集計(製造業)市区町村編」の調査』としていったん保存します.

「JOB一覧」画面で当該JOBを確認し,三角の実行ボタンを押すと,出力データ「産業分類一覧.xlsx」がダウンロードできます.

6. 都道府県レベルのデータを分別する
さて,またコックピットに戻ってデータを眺めてみますと,このデータには異質なレコードが混在していることがわかります.それは,自治体の階層の話で,「市区町村名」に「北海道」や「札幌市」や「札幌市中央区」という異なる自治体レベルのレコード(暗黙の中計レコード)が共存しているということです.
ちょっと居心地が悪いので,自治体レベルごとにデータを分けてしまいましょう.「条件分割」で「市区町村コード」が100未満(二桁)かそうでないかで,「都道府県レベルのデータ」と「市区町村レベルのデータ」に分けることができます.

「都道府県レベルのデータ」を「中間ファイル」でプレビューすると,

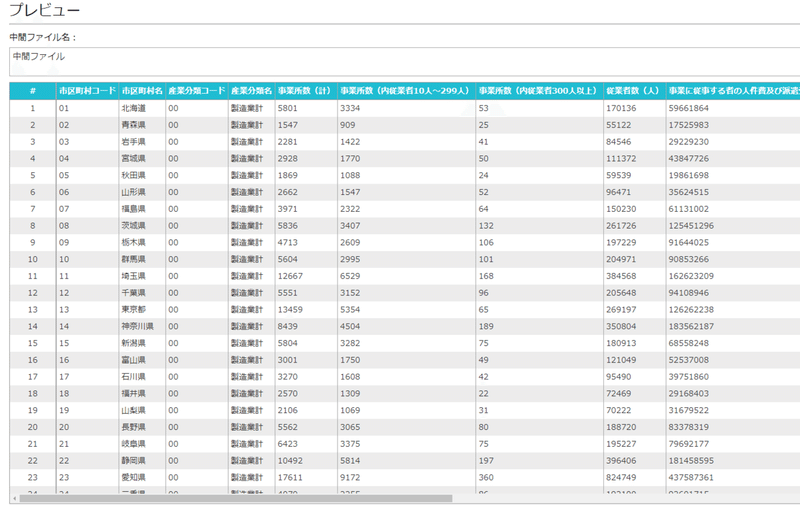
良さそうです.
7. 政令指定都市,東京都特別区のデータを分別する
次は,「札幌市」(区なし)などの政令指定都市全体を分離します.東京についてはどうなっているでしょうか…「市区町村名」が「東京」で始まるものを,こっそり見てみましょう…

「条件抽出」で「市区町村名」が「contains」の「^東京」(^ は先頭の意味)であるものを抽出しますと,

やはり,「東京特別区」のデータがありました.では,政令指定都市と「東京特別区」をどうやって分離するか?というのが次の課題です.(市区町村コードの3〜5桁目が "100" であれば,という簡単な決まりがあれば良いのですが,残念ながら1都道府県に政令指定都市が複数ある場合は,"100" 以外にも,二つ目以降の政令指定都市の "1xx" が何になるかは決まりません!)
こういう場合,そういった特別なレコードは「何らかのルールを使って分類」するのではなく,「特別なレコード群をデータで用意してぶつけて分類」という手が使えます.早速やってみます.
Excel で下のような小さいデータを作り,「政令指定都市と東京特別区.xlsx」というファイルに保存して,ALZETA にアップロードします.

結合とは
次に 6. でできている「市区町村レベルのデータ」とこのデータを「ぶつける」わけですが,ぶつけるという操作は「結合」で行います.「結合」とは,二つのデータ(データA とデータB)で共通に持っている「キー項目」が同じレコードを取り出して,それらの非共通項目をマージしたレコードを作成して,新しいデータC を作る,というものです.
IPOC の場合,この二つのデータを主データと副データという呼称で区別しています.副データは主データを「修飾する」項目が入っているという位置付けです.
以下は,「社員番号」をキー項目に指定して,データA(主データ)とデータB(副データ)を結合した例です.
データA(主データ)
社員番号 氏名 年齢
0001 山田太郎 40
0002 川田二郎 36
0003 谷田三郎 28
0004 海田四郎 24データB(副データ)
社員番号 携帯電話番号
0002 0A0-7876-1095
0003 0B0-6909-6630データC(内部結合の場合)
社員番号 氏名 年齢 携帯電話番号
0002 川田二郎 36 0A0-7876-1095
0003 谷田三郎 28 0B0-6909-6630データC(外部結合,欠損値を「携帯なし」と指定した場合)
社員番号 氏名 年齢 携帯電話番号
0001 山田太郎 40 携帯なし
0002 川田二郎 36 0A0-7876-1095
0003 谷田三郎 28 0B0-6909-6630
0004 海田四郎 24 携帯なし内部結合の場合は,主データのうち,副データにも存在するレコードしか生成しません.外部結合の場合は,主データにあって副データにないレコードについては,欠損している項目に代わりになる欠損値を入れてデータを埋めます.
また,内部外部問わず,ALZETA では結合するデータは,主データとも副データとも,あらかじめキー項目でソートしておく必要があります(先述の「ユニーク」の場合と同じ理由です).
さて,では結合を行います.

あらかじめ,双方のデータをソートしてから,外部結合します.外部結合により,政令指定都市(の合計)と東京特別区(の合計)以外については項目「政令指定都市または東京特別区である」の値が「N」となるように欠損値を設定しています.

この外部結合までのデータを,もう一度「市区町村コード」でソートし直してプレビューすると,

1番目のレコード「札幌市」については「政令指定都市または東京特別区である」が「Y」で,続く「札幌市中央区」以降は「N」になっていることがわかります.あとはこの値によってデータを分割すればよく,
「Y」→「政令指定都市ごと・東京特別区の合計」
「N」→「自治体最小単位のデータ」

とします.「政令指定都市ごと・東京特別区の合計」をプレビューしてみると,想定通り分離できていることがわかります.

8. 市区町村レベルのデータを人口のデータと結合する
さて,ここまでできた「自治体最小単位のデータ」を総務省の人口データを結合してみましょう.
「【総計】令和2年住民基本台帳人口・世帯数(市区町村別)」
「自治体最小単位のデータ」
を見比べると,市区町村コードと市区町村名が共通項目です.ただ,ここではコードの方を信頼して,市区町村コードをキーとして結合を行います.また,「【総計】令和2年住民基本台帳人口・世帯数(市区町村別)」では項目名が「団体コード」になっているのと,コードの最後に CD がついて6桁になっていますので,ここから左5桁を取り出してまず「市区町村コード」を作ります.

さらに,そこから不要項目を「並替」で削除し,結合を行います.

ここまでのデータをプレビューすると,
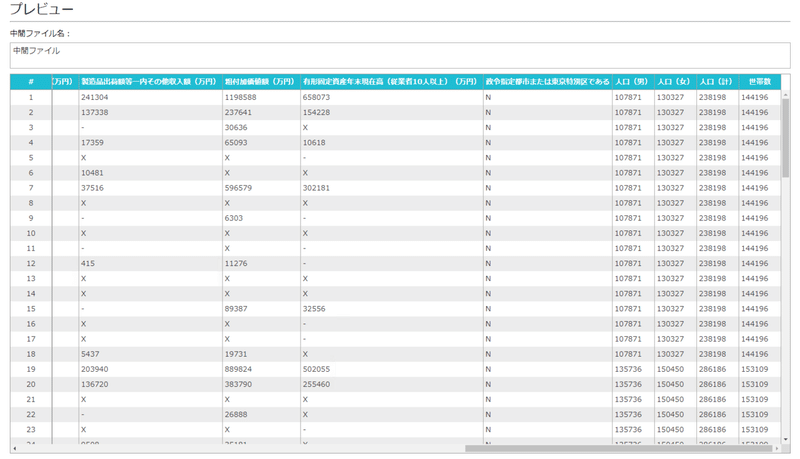
経産省のデータの右に総務省の人口データが付いていることがわかります.
9. どの市区町村が XXX なのか計算してみる
ここまでくると市区町村ごとに「人口あたりの XXX」を計算して比較することができます.
たとえば,人口あたりの「粗付加価値額(万円)」を計算して,上位市区町村を洗ってみます.先ほどまでのフローに4つ処理を追加して,下のようなフローを作りました.
* 「内部結合」の後の「条件抽出」で「産業分類(コード・名)」が「00 製造集計」であるものだけ取り出します(自治体によっては,この「00 製造集計」しかない自治体があるから)
* 「演算」で「粗付加価値額(万円)」を「人口(計)」で除算して,『人口あたりの「粗付加価値額(万円)」』を産出
* 「並替」で不要項目を取り除き,興味のある項目を順に並べる
* 「ソート」で『人口あたりの「粗付加価値額(万円)」』の数値降順にデータをソート

得られた結果はこの通りです.

というわけで,冒頭(表題)の順位は,「人口一人当たりの製造業の粗付加価値額(万円)が大きい」自治体でした.
寡聞にして,香川郡直島町のことを全く知らなかったのですが,三菱マテリアル社の直島製錬所があり,電気銅,貴金属の精錬,リサイクルのメッカだそうです!
上北郡六ヶ所村は,エネルギー産業で有名ですし,南都留郡忍野村といえば,ファナック社ですね.
まとめ
最後はすこし余談めいた話もしてしまいましたが,今回は政府が集計して公開しているオープンデータ二件を題材にして,ALZETA で「データを動かす」ということを具体的にご説明しました.ALZETA で操作することで,殻に閉じこもったデータが解きほぐされて,価値ある知見を産む様子がご覧いただけたかと思います.(また特に「結合」を修飾データの付加だけでなく,データ抽出/分類に使用するというデータ操作のハイライトの部分もご覧いただきました.)
いわゆる BI ツールであれば,今回のような分析はあるいは,おまかせで手間なくできるのかもしれませんが,そういった受動的なデータへの接し方では,データの素性を知り,活用を模索するモチベーションは得られないのではないかと思います.一方,ALZETA を操作してデータをプレビューしたり,項目(カラム)の吟味をしたり,処理を分岐させたりしていると,次々にやりたいことが出てきて,能動的にデータに処理を加えていきたくなるのが面白いところです.
さて,今回は分析用途に ALZETA でデータを動かしてみましたが,次回は,業務データ処理に ALZETA がどう活用できるかを見ていきたいと思います.
この記事が気に入ったらサポートをしてみませんか?