【8.文体と語彙】現代短歌のテキストマイニング――𠮷田恭大『光と私語』(いぬのせなか座)を題材に

(承前)
8-1.品詞構成の比較(他ジャンルとの)
8-1-1.文体とは何か
手法
「文体とは何か」という問いには、文章表現史のなかで多くの回答が試みられてきた。たとえば、表記や字体によるもの、単文の長さや句読点によるもの、(敬語や語尾を含む)文末処理によるもの、文法構造によるもの、文節パターンによるもの、語選択の難易度や特異性によるもの、単語や構文の出現頻度によるもの、単位あたりの論理や運動、印象の展開の傾向によるものがある。日本語圏では、漢語/和語の分量や、漢字・かな・英字の配分などにも注目される。あいまいな印象に頼った評言もあれば、個人的な体験に基づく判定もあり、何らかの基準を当てはめることも、明らかな数量の差を求めることもある。
その著者/読者が属する文化圏によって、良しとされる「文体」は異なる。古風な文体分析は、いくつかのテキストから数文をサンプリングした、一種の抜き取り調査として行われる。手軽さと分かりやすさから、この方法はいまでも主流だ。
なぜか。なぜだろう。わずか数文ほどの文章であっても、厳密には一文ごとに文体が変わる。少ない試料の調査では、あるテキストが内包する文体の変質を捉え損られない。それに、通常の識字能力を持つ自然人は、テキストを一文ずつしか読めない。テキストが長くなればなるほど、全体の性質をくまなく理解するのは不可能に近いし、その労力に見合うものが得られない。
これらの困難を乗り越えるために、聖書や古典の解釈学から出発して、「文体」を謎めいた神秘としないための学術研究が積み重ねられてきた。その歴史は100年ほど昔まで遡れるという。諸学問は、計量文献学、統計文体学、計算言語学、自然言語処理などと呼ばれ、コンピュータの導入も早くから試みられてきた。そして近年、機械学習アルゴリズムが、大規模なデータをより複雑に処理できるようになるにつれ、目覚ましい進歩を遂げている。持続的な言語コーパス開発が重要であることの理解も進んでいる。私たちもその恩恵にあずかって、1冊の歌集が内包する文体を、俯瞰して理解する方法を考え出せないかと考えた。
8-1-2.よくある課題
しかしいわずもがな、分析に採用する視点、母集団の選び方、サンプルの抜きとり方、評価対象、結果の表現は、評価者の立場や経験、考えによって変わる。そのばらつきこそが、評価者の人となりや、世界に対する態度を示す、ひとつの「話芸」だとされ、その枠組みに沿った消費が暗に推奨され、評判や収益を左右もする。さらには「評価者」もひとつのテキストの集積であって、ある著作(というテキスト)に、ある評価者(というテキスト)をあてがうだけでも、その采配を決めた編者の狙いが示される。
こうなると、個々の「文体」の分析にはほとんど意味がなくなって、いきおい評価者の「人数」や評の「字数」がそのテキストへの反響を示す指標にさえなる。「文体とは何か」という問いは置き去りにされて、その共同体の権威や慣習、流行、気分こそが、「文体とは何か」を代弁するようになる。ひとつの共同体そのものが、ひとつの分析装置として機能し始める。評価基準の相容れない共同体は分裂し、細分化して、複数の似通った文体を雑多に内包する、流動的なテキスト群として再編成されていく。通俗的にいえば、それらは〇〇文学、▲▲話法、××文体、□□系と総称されて、ひとつの流派やトレンド、モード、スタンスを示す記号として、社会のなかで通用していく。政治的な、あるいは部族的な対立を助長しもする。
このように、文体分析をとりまく諸問題はややこしく入り組んでいる。だとすれば、1冊のテキストが持つ文体を理解するには、その1冊だけを分析するだけでは足りないのだろう。むしろ、より多くのテキスト群のなかで、その1冊が何に近く、何から遠く離れているかを分析したほうがよさそうだ。
8-1-3.私たちの採用手法
そこで私たちは、『現代日本語書き言葉均衡コーパス』(BCCWJ)と『国立国語研究所報告 8 談話語の実態』(『日本語話し言葉コーパス』(CSJ)から孫引き)の語彙表(品詞別含有率)を用いて、文書群ごとの名詞率、用比率、相比率を集計し、BCCWJコーパスの全体平均との差を計算した。それぞれのコーパスの特徴は後述する。
8-1-4.語彙表の性質
BCCWJについて
『現代日本語書き言葉均衡コーパス』(BCCWJ)は、「現代日本語の書き言葉の全体像を把握するために構築したコーパスであり、現在、日本語について入手可能な唯一の均衡コーパス」だ(国立国語学研究所「書き言葉均衡コーパス 概要」より)。新聞、書籍、雑誌、教科書などの出版物から、短歌・俳句全集からサンプリングした「韻文」、Yahoo!ブログ、国会会議録、ベストセラー、法律、白書など、さまざまなスタイルの文書群に取材している。1986年以降に東京都内の公立図書館が収蔵した図書114万冊を母集団とし、ジャンルによって、159件から91,445件までランダムに文章を抽出し、収録している。
研究機関に属さない一般企業が営利目的でこのコーパスを使うには、合計60万円(税別)の費用がかかる。そのため今回は、研究・教育用途に限って無償利用できると明記された公開情報のうち、「語彙表」は「BCCWJ品詞構成表(Version 1.1)」の品詞別統計だけを用いた。
なお、収録された書き言葉の生産年代は、ジャンルごとに異なることをご承知おきいただきたい。書籍、雑誌、新聞は、2001年から2005年の刊行物を対象とする。「教科書」は2005年から2007年もので、「Yahoo!ブログ」は2004年から2005年まで、「広報紙(自治体)」は2008年のみだ。つまり、21世紀初頭と比較的新しいけれど、ソーシャルメディアが世界的に普及する前に書かれた言葉から採集されている。他方で、「白書」「ベストセラー」「法律」「国会会議録」は1976年から2005年までを対象期間とする。これらのコーパスの分析結果からは、年代ごとの特徴よりも、時代を超えた傾向が色濃く出る可能性がある。
CSJについて
『日本語話し言葉コーパス』(CSJ)は、「日本語の自発音声を大量にあつめて多くの研究用情報を付加した話し言葉研究用のデータベースであり、国立国語研究所・ 情報通信研究機構(旧通信総合研究所)・ 東京工業大学 が共同開発した、質・量ともに世界最高水準の話し言葉データベース」である(国立国語学研究所「話し言葉コーパス」より)。学会発表やスピーチ、ニュース解説、テレビバラエティ番組などに取材し、661時間・752万語を収集する。分節音やイントネーション、係り受け情報などのメタデータも付されるなど、すさまじい品質水準の言語資源情報である。このコーパスも、私企業による営利利用は75万円(税別)かかるため、今回は、報告書『日本語話し言葉コーパスの構築法』第3章「形態論情報」(P170)所収の統計表(表3-7)だけを引用することにした。「ニュース」「ニュース解説」「日常談話」の品詞別含有率の要約である。
なお、この統計表は、CSJ本体ではなく、『国立国語研究所報告 8 談話語の実態』(1955、国立国語研究所、秀英出版)による。CSJは、話し言葉に含まれる要素をより厳密に分類するため、通常の品詞分類による統計を行っていない。そのため今回は、簡単のために、CSJが先行研究として参照した同報告書の統計データを参照した。
余談だが、その報告書の調査は1952年に行われた。元データは、おおむね東京都内で暮らす「N家雑談」「じいさんばあさん」「井戸端」「絵画館おばさん」「三鷹女工」「職安男子」といったひとたちの、さまざまな地区・場所・性・年齢・教養・相手の談話を記録した録音テープから作成されている。録音機器の普及した昨今とちがい、データ収集はかなり大変だったようだ。
1952年7月初旬から9月末日までの間に,資料としてのテープ80巻の採集を終った。折あしく当時は電力事情が悪く,また作業員が大都会での採集に不慣れであって,混入する雑音についての知識と経験とがとぼしかったため,電力低下・雑音混入により,多くの使用不能のテープを生じ,かろうじて分析に堪える明瞭度に録音されたものは60巻に過ぎなかった。
「多くの使用不能のテープを生じ」た「作業員」が、敗戦から7年後の「大都会」で味わっただろう悲しみには、同情せざるを得ない。当時、「三越美容室」で談話した「年齢:若」の「性:女」が20歳だったとしたら、彼女は2020年に88歳になる。「作業員」は、もしまだ存命だったとしても、90歳以上だろう。ほかの話者も、いまでは例外なく高齢者で、多くはすでに故人かもしれない。つまり、「日常談話」の数値は、私たちの祖父母~曾祖父母世代が話した言葉に関する、かろうじて現代まで残された、ごくわずかな情報であり、最近の私たちの話し言葉のそれではないことをご承知おきいただきたい。
手順
文書群ごとの名詞率、用比率、相比率を集計し、BCCWJコーパス全体との比較を行った。各比率について、

を算出し、各文書群について全体からのずれを求めた。
各比率に含まれる品詞の種類
名詞率 = ['名詞', '代名詞', '感動詞']
用比率 = ['動詞']
相比率 = ['形容詞', '副詞', '連体詞', '形状詞']
結果
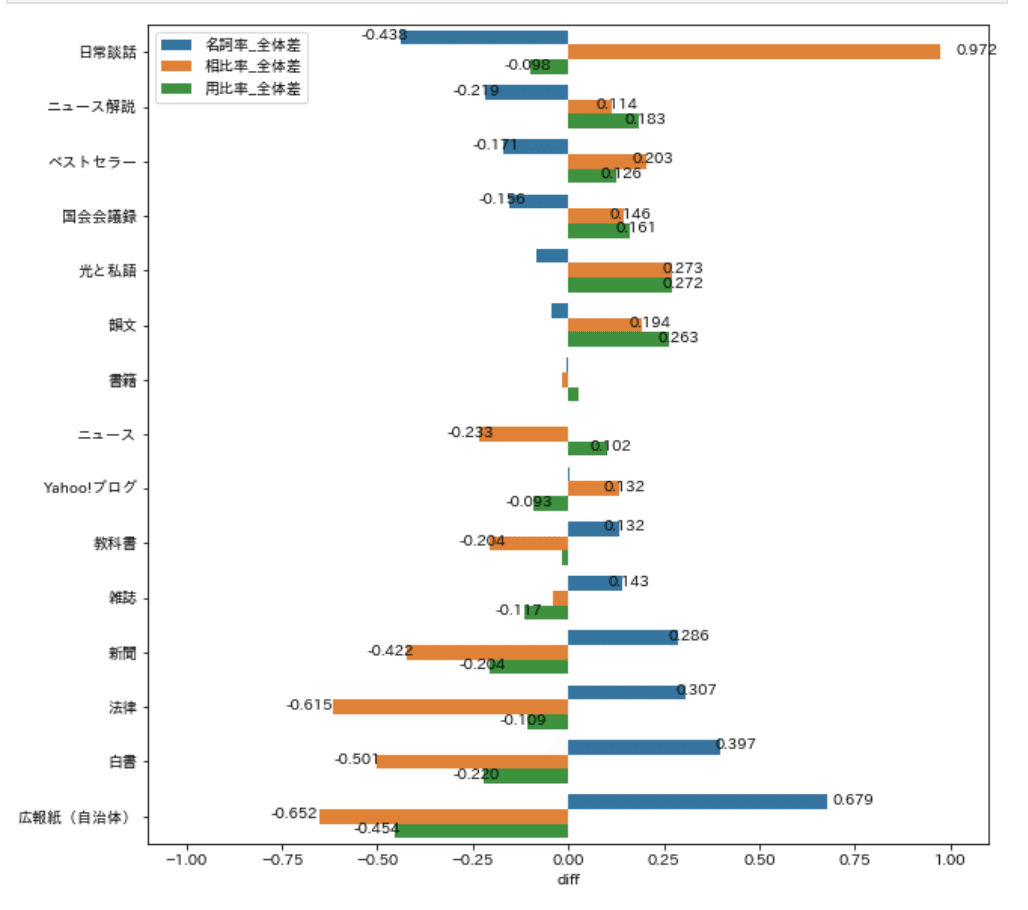
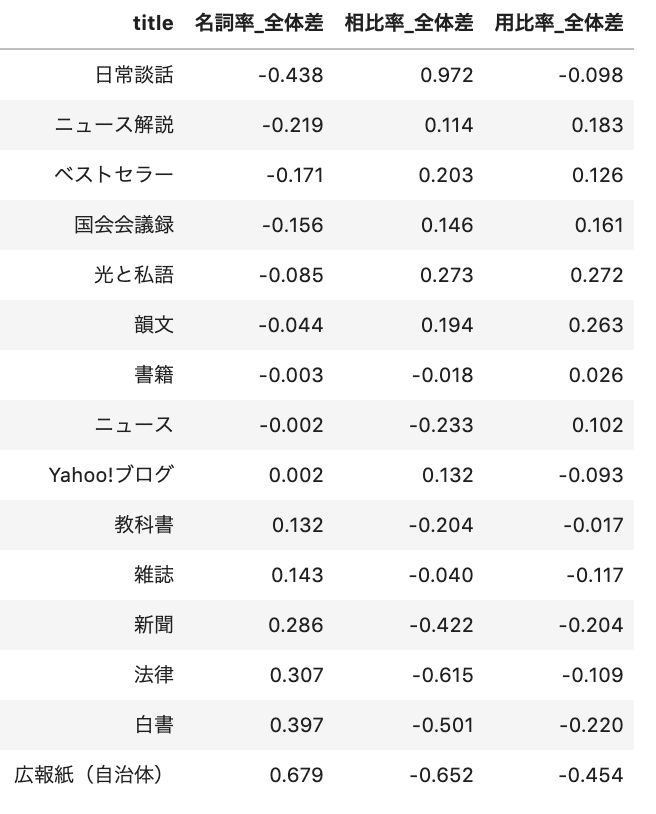
縦軸は各ジャンルの名称であり、横軸は変化率である。名詞率の高さで昇順に並べ替えた。値が大きいほど、全体より品詞が多く含まれ、値が小さいほど品詞が全体より少なく含まれる。
- グラフ
- 数表
考察
8-1-5.名詞率の傾向
名詞率は、白書、法律、新聞が高い。いわゆる「硬い文章」だと言ってよいだろう。さらに、それらを上回って、広報紙(自治体)の名詞率がもっとも高い。広報紙(自治体)はたとえば次のような文章から成り、名詞(とりわけ漢語の複合名詞)が多いと分かる。文章の「硬さ」には、名詞の含有率がいくらか作用しているのかもしれない(予想)。
11月の入居者募集から、定期使用住宅の入居制度が拡充されます。/■対象者の拡充/ひとり親世帯(原則、親が40歳未満)も対象に/■入居期間の延長/入居期間は原則10年とし、10年目に同居する子供がいる場合は、末子が18歳に達する日以後最初の3月31日まで
(出所:東京都「広報東京都 令和元年11月号」所収「子育て世帯にとって都営住宅がより使いやすくなります」より)
逆に、日常談話は名詞率がもっとも低い。ベストセラーが国会会議録によく似た性質を持ち、雑誌や新聞よりも日常談話に近いことも注目に値する。よく売れるテキストには、読み原稿や、話すように書かれた言葉が多いのかもしれない。
8-1-6.用比率の傾向
用比率は、広報紙(自治体)がもっとも低く、韻文がもっとも高い。大まかにみて、用比率が上がるほど、名詞率は下がる(Yahoo!ブログ、日常談話など例外はあるが)。先ほどの予想に絡めていえば、「硬い、書き言葉」になるほど動詞が減り、「やわらかい、話し言葉」になるほど動詞が増えるようだ。ひとまず、「韻文は動詞が多い」と言えるだろう。さらに、「動詞を増やせば韻文らしくなる」と言えるかは、検証する価値があるだろう。
8-1-7.相比率の傾向
書籍、雑誌は、平均並みの相比率だった。広報紙(自治体)、白書、法律が低い。新聞も、教科書も低い。逆に、Yahoo!ブログ、国会会議録、韻文が高い。ベストセラーが(書き言葉では)もっとも高い。また、日常談話が他に群を抜いて高い。
8-1-9.『光と私語』の位置
ここまでに述べた傾向を踏まえて、『光と私語』は、さまざまな言語表現(の共同体を構成するテキスト群)と比べて、どのような立ち位置にあると言えるのか。
・『光と私語』は全体と比べて名詞率が低く、用比率、相比率が高い。もっとも似たジャンルの文書は、(やっぱり)韻文だった。
・しかし、韻文と比べて、用比率が高い。名詞率、相比率は低い。韻文のコーパスは、次の3種類のテキストからサンプリングして作られている。
短歌: 『現代短歌全集』(筑摩書房、2002年刊) 第14巻~第17巻
俳句: 『増補現代俳句大系』(角川書店、1980年~1982年刊) 第8巻~第15巻
詩: 「現代詩文庫」シリーズ(思潮社、1986年~2005年刊) 118冊
つまり、直近30年間に公刊された現代俳句・現代短歌・現代詩と比べて、『光と私語』は動詞が多く、形容表現が少ないということだ。このことが、この歌集の何らかの「読み心地」を決定づけているだろう。
他に似たジャンルには、ベストセラー、国会会議録があげられる。常識的な理解に反して、韻文(詩歌の言葉)は国会会議録(政治の言葉)やベストセラー(通俗の言葉)によく似ている。『光と私語』がそれらと似た性質を持つことは興味深い。ポピュラーであるとは言い切れないまでも、読み上げやすい文体であるとは言えるだろう。
『光と私語』は、どちらかといえば硬めの、話すように書く言葉に近い。とはいえやはり韻文の文体であり、韻文と同等かそれ以上に形容表現が多い。「短歌らしくなさ」は、名詞の少なさと動詞の多さを手がかりに説明できるかもしれない。
8-2.品詞率を用いた指標(MVR)による文書分類
手法
前節では、『光と私語』の文体分析を行うべく、(1970年代後半から2000年代の言葉から成る)日本語書き言葉均衡コーパスと、(1950年代に作られた)話し言葉コーパスとの比較を試みた。他の韻文と比べて、動詞が多く、名詞と形容表現が少ないと分かった。このことを踏まえて、この歌集の内容により踏み込んだ分析を行う。
前節から引き続き、品詞別含有率を用いる。ただし、この分析では、1965年に考案された指標MVRの算出を行い、連作ごとのちがいを表現できるか確かめる。MVR(Modifier Verb Ratio:相用比)の定義は次のとおり。
樺島・寿岳(1965)は「100×相の類の比率/用の類の比率」で求められる MVR という指標を提案し,MVR と名詞の比率との組み合わせから,名詞の比率が大きく MVRが小さければ要約的な文章,名詞の比率が小さく MVR が大きければありさま描写的な文章,名詞の比率が小さく MVRも小さければ動き描写的な文章と考えられるとしている。
(冨士池優美・他「長単位に基づく『現代日本語書き言葉均衡コーパス』の品詞比率に関する分析」(2011)より)
改めて説明すると、「用の類の比率」とは、コーパスに含まれる「動詞」(Verb)の割合のことだ。略して「用比率」と言われる。「相の類の比率」は、コーパスに含まれる「形容詞・形容動詞・副詞・連体詞」(Modifier)の割合をいう。こちらも単に「相比率」と言われる。MVRは、この2つの値と名詞率を組み合わせて、文体の評価を行う指標として考え出された。次のようにまとめられる。
- 要約的文章:名詞率が高く、MVRが低い
- 有様描写的:名詞率が低く、MVRが高い
- 動き描写的:名詞率が低く、MVRが低い
手順
連作ごとに名詞率、用比率、相比率を算出した。さらに、名詞率とMVRの多寡をもとに4象限を作って、それぞれの連作をマッピングした。なお、数値の判定は、本歌集全体の平均より大きければ「高い」、小さければ「低い」とした。他の文書との比較ではなく、このテキスト内での相対比較であることにご注意いただきたい。
予想
ちなみに、『光と私語』と『現代日本語書き言葉均衡コーパス』(BCCWJ)の全体平均は次のとおりだった。

書き言葉一般(BCCWJの全体平均)と比べて、『光と私語』は用比率が高く、相比率がやや高く、名詞率が低い。樺島・寿岳(1965)の分類によれば、(b)有様描写的な連作や、(c)動き描写的な連作が多く含まれると予想される。
結果

連作ごとの数値(品質別)は次のとおり(連作番号は、章番号と掲載順の組み合わせ)。

考察
・第1章、第2章、第3章ともに、特定の象限に偏った分布はしていない。
・章ごとに、連作が進むにつれて、おおむね名詞率が高まる。
・「ト」は韻律のない、ト書きのような単文が多く、動き描写的な文章だとの判定に整合する。
・樺島・寿岳(1965)の3分類に当てはまらない、未分類の連作がある。いずれも名詞率が高く、用比率が高い一方で、相比率が低い。いわば、形容表現に禁欲的な、「硬い、書き言葉」に近い連作である。
展望
・連作ごとに特徴が異なることが分かる。MVRを用いると、その差が分かりやすく描画できる。
・第4象限を名指す定義がなく、MVRは評価指標として改善の余地がありそうだ。MVRは1965年に考案された。約55年間に渡って、このことが気づかれなかったのはなぜか……。
・日本語は名詞と助動詞の割合が高い言語で、動詞や形容詞の分量との差が大きい。含有率を計算するとき、ばらつきをうまく表現できるような工夫を行う余地がある。
・指標を構成する品詞を入れ替えれば、テキストを比較する基準はほかにも考えうる。用言だけで比較軸を作ると、名詞の出現量に依存しない、テキストの動的な性質を理解する基準が作れるかもしれない。
・もっとも含有率の高い「名詞」も、種類別に分解すれば、さらに詳しい解析が行える。例えば、『日本語語彙体系』は、名詞を一般名詞(主体、場所、具体物、抽象物、事、抽象的関係)と固有名詞(地域名、自然名、施設名、人物名、組織名、年号などその他)に分けて整理する。この区分を応用きるかもしれない。
8-3.異なり形態素比率と語彙の豊かさ
8-3-1.語彙の多さ
手法
最後に、他の作品との比較を行う方法を試しておきたい。 240文から成り立つこの歌集は、どれくらい多様な語彙で作られているのか。文章に用いられる語彙の多さは、その文章の優劣をただちに決めるものではない。わざと少ない語彙で書く著者もいるし、第二言語で書く著者の語彙は、母語の著者よりも比較的少ないだろうから。けれども、書き手が「いろいろな言葉を知っている」と見なす手がかりにはなる。「同じ言葉を何度も使いたくない」こだわりがあるのかと、想像するのも楽しい。
そこで、「この歌集に使われた語彙の多さ」を示す指標を計算してみることにする。文体診断ロゴーン(2009)では、この指標を「異なり形態素比率」と呼んで、青空文庫に収録された64の著者の文体評価に用いている。その(統計データ)をもとに、この歌集を位置づける。
まず、形態素解析の結果から、次の3つを算出した。第8章でも用いた指標だ。
- 総形態素数:この歌集から切り出せる、すべての形態素の数。
- 異なり形態素数:総形態素数から、くり返し使われた形態素の重複を除いた数。
- 異なり形態素比率:[異なり形態素数]÷[総形態素数]* 100. 総形態素数に占める異なり形態素数の割合。
さらに、大まかな傾向を知るために、「文体診断ロゴーン」の解析結果と比較した(厳密には、「文体診断ロゴーン」はYahoo!ジャパン独自の日本語形態素解析APIを用いているから、juman++を用いた私たちの分析とは数値が異なる可能性があることに注意)。
結果
3つの指標は次のようになった。
- 総形態素数:2,324
- 異なり形態素数:1,198
- 異なり形態素比率:51.54(%)
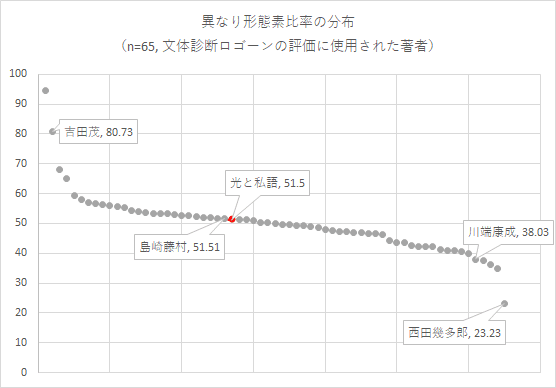
また、「文体診断ロゴーン」の解析結果と比較すると、下図のようになった。
考察
両極には政治演説と哲学論考がある。数値が2番目に高い吉田茂「第18回国会所信表明演説」は、「ここに政府は昭和二十八年度第二次補正予算案を提出いたしましたが、政府は、経済の自立達成上、従来ともに健全財政の堅持、通貨価値の安定を中核としてインフレ傾向の抑制に万全の配慮をなして来たものであり」といった調子で、1,200字ほどのごく短いテキストのなかで話題を次々と変えていく。その分、異なり語数も増えてくる。数値がもっとも低い西田幾多郎「絶対矛盾的自己同一」は、「時が何処までも一度的なると共に、現在が時の空間として、現在から現在へと、現在の自己限定から時が成立すると考えられる如く」といった語りで、これが5万字ほど続き、論理命題の展開によって同語反復が連続する。異なり語数が少ないのは、そのためだろう。
そして、40%-60%区間にほとんどの文芸書が含まれている。ここから2つのことが言える。まず、私たちが分析しているこの歌集は、とくに奇を衒って語彙を大きく見せたり、少なく見せようとしていない。スタンダードな語彙が選ばれていると言ってよい。
展望
「語彙の豊かさ」は文芸書を評価する初歩的な指標みたいに思われがちだけれど、どうやらそれは不正確な理解なのだろう。私たちがあるテキストに「語彙の豊かさ」を感じるとき、それは「実際に多くの語彙が用いられていること」ではなく、別の「何か」にその印象を抱いているのかもしれない。
この記事が気に入ったらサポートをしてみませんか?