
【6.文脈と意味】現代短歌のテキストマイニング――𠮷田恭大『光と私語』(いぬのせなか座)を題材に

(承前)
6-1.言葉の「距離」を測る
6-1-1.「あなた」の共起語ネットワーク
手法
ここまでは語の「量」を計測してきた。次は、語と語の「距離」を分析してみたい。といっても、ある物理的な空間(または平面)のなかで、異なる語がどの地点にあるかを示すのではなく、どの語がどの語と一緒に出現しやすいか(共起性)、ある語と別の語はどれくらい似ているか(類似性)を算出する。
この節では共起度を用いた分析を行った。類似度による分析は次の節で扱う。第1章「わたしと鈴木たちのほとり」のテキストをもとにして、共起語ネットワークを作成した。形態素解析にはginzaを用いた。1文書に同時に出てくる単語の組み合わせを数え上げ、その値を共起度とした。あらかじめ助詞や記号は除外し( ['ADP', 'INTJ', 'PUNCT', 'SCONJ'])、作成した。
距離計算の方法は数多くある。簡単のために、その詳しい説明は省略したい。関心のある方は、ユークリッド距離、コサイン係数、ジャッカード係数、ソーレンセン-ダイス係数、シンプソン係数などを調べてみるといい。
結果
この図は、代名詞「あなた」と共起(一文のなかで同時に出現)する単語のネットワークを描いたものだ。品詞別に色分けしてあり、距離が近いほど、共起度が高い。「あなた」からの距離だけでなく、他の語との距離も考慮されている。

考察
他の語の間の距離を考慮すると、1首を構成する語の結びつきに近いまとまりが形成されるようだと分かる。1首の枠を越えて、「あなた」と一緒によく表れる語群も分かる。
こんな風に、採用する語や考慮する距離をよく吟味して、共起語ネットワークを使えば、1冊の歌集をより綿密に分析するときの、手がかりとなる見通しが、より手軽に得られるのではないか。
展望
なお、今回の分析では、より自然な描画を行うために、類義語をひとつにまとめる、縁語をグループ化するといったことを行わなかった。たとえば、「あなた」ではなく「乗りもの」にまつわる名詞をひと束にして、それらの語群を中心に置いたネットワーク図を描くと、どうなるか。
たとえば、『万葉集』に頻出するとされる「恋ひ(孤悲)」が、どういった語群につながるネットワークを形成しているか、観察するのはおもしろいだろう。2014年には「和歌用語シソーラスの開発と用語空間分析に関する基礎研究」と題して、古典和歌の用語シソーラスを八代集から二十一代集に拡張した研究も公表された。現代短歌でも、歌集や歌人の枠を超えたテキストデータがもし作られたら、さらに多くのことが分析できそうだ。
6-2.単語ベクトルによる類似度の学習
手法
6-2-1.単語ベクトルとは何か
「意味とは何か」を完璧に答えるのは難しい。けれども、ある言葉を別の言葉で「置き換える」「言い直す」ことは日常的に行われる。似た働きをする、文脈が近い、別の言い方ができる、同じことを指す、といった言い回しがなされる。類語辞典はその集積であり、比喩、象徴、暗号、縁語のように、言葉が持つこの働きを用いた技法もある。
言葉の意味は、その語が置かれる文脈のなかで決まる。文脈とは、より大きな言語の総体から、いくつかの語群が選ばれ、何らかの規則に沿って並べられる順番から生まれる。よく似た文脈で扱われる単語は、意味が近いと言える。だとすれば、あるテキストが含むすべての単語が持ちうる文脈を、単語間の「位置」「距離」「角度」として数値化できれば、ひとが目視では気づけなかった、ある語の新しい意味を見出せないか。
このような着想をもとに、単語をベクトル空間内の座標と見なし、ある単語と別の単語の関係を表現したり、類推する技術が考え出されてきた。それらの表現・技術は、「単語埋め込みベクトル」(または、縮めて単語ベクトル)を用いた「分散表現」などと総称される。
6-2-2.どのような表現なのか
ベクトル空間は、分析したい文書に含まれる単語の数だけ増えていき、すぐに数千から数万もの高次元になってしまう。しかも、単語の出現位置はまばらで、どの単語の座標も「ごくわずかな次元でだけ値を持ち、他のすべての次元はゼロとなる」性質を持つ。いってみれば、データ全体のサイズが巨大なわりに、中身はすかすかの状態になりやすい。そこで、単語ベクトル空間を圧縮して濃密にする――数十から数百ほどのより小さな次元に埋め込む方法が考え出された。1986年のことだ。考案者に分散表現と名付けられたこの方法は、のちに単語埋め込みとも呼ばれるようになった。
ところが、現実が追いつかなかった。新しすぎたのだ。大量のテキストデータは流通しておらず、潤沢な計算資源をだれもが気軽に使えるような時代ではなかった。強引に分析しようにも、途方もない計算量が求められるうえ、予測モデルも頑健さを欠いてしまう。そのせいで、四半世紀の間は日の目を浴びなかった。
しかし2000年代に入ると、大規模データ処理技術が発達して、高次元のデータが昔と比べて扱いやすくなった。機械学習の方法が自然言語処理にも応用され、2013年には、ニューラルネットワークを利用する手法が発表された。word2vec(Mikolov et. al. 2013)と名づけられた手法は、研究者たちに驚きを与えた。そしてこの5年間で、新しい手法の発表が相次ぎ、応用研究や社会実装も進んで、いまや多くの科学者やプログラマに利用できるようになった。ほかにGloVe(Jeffrey Pennington 2014)、LexVec(Alexandre Salle 2016)などの分析モデルが知られ、同手法を文書(document)に応用したdoc2vecなどもある。text2vecといって、関連手法をひとまとめにし、Rで使えるようにした総合パッケージも提供されている。
6-2-3.私たちの採用手法
そこで私たちも、この手法を取り入れて、この歌集から単語ベクトルを得る教師なし学習を行うことにした。「教師なし学習」とは、機械学習アルゴリズムによる分析手法のひとつで、基準や正解となるラベル(分類、判定、例示)を用いずに、与えられたデータの特徴や傾向から、分類や推論の枠組み(モデル、パターン、クラスター、セグメント…etc,)を導き出す方法である。近代短歌への適用例は1つだけ見つかった。ほかでもなく、「機械学習で石川啄木を蘇らせる」だ。現代短歌への適用は、日本で初めてかもしれない。日本初ということは、世界初かもしれない。
私たちが採用したfastTextは、facebookが提供するオープンソースの自然言語処理ライブラリだ。ひと言でいえば、その名の通り、word2vecの速いやつである。まとまった分量のテキストを入力すると、単語ベクトルを生成する。
手順
6-2-4.「語義」を2次元に写像する
この歌集をfastTextに学習させた。['特殊', '助詞', ''判定詞']は除外した。約物や活用しない付属語は、テキストの大部分を占めるが、それ自体で意味を構成しづらく、分析結果を解釈しづらくすると考えたからだ。また、分析対象は短歌のみとし、非-短歌だと見なした37行は扱わないこととした。
連作を1単位とした場合と、短歌1首を1単位とした場合。それぞれについて、単語の出現順に学習させた。分散表現のベクトル空間は、そのままでは次元数が多すぎて、人間が認知できる可視化を行えない。そこで、次元削減アルゴリズム「t-SNE」(t-distributed Stochastic Neighbor Embedding, t 分布型確率的近傍埋め込み)を用いて、平面(2次元)に写像して描画した。
注意しておきたいことがある。描画結果は、高次元のベクトル表現を平面に押しつぶしたもので、各点の位置や距離が、分かりやすく何かを意味するわけではない。もちろん、描画結果は、テキストが内在的に持つ特徴から導かれていて、近い意味を持つ。しかしその「本当の意味」を常人は理解できない。もっとも、少なくとも仮説づくりのヒントになる。そう考え、あえて、描画された平面を、そのまま読み、解釈することにした。
結果
6-2-5-1. 連作ごとに学習
500語分の単語ベクトルを抽出し、t-SNEで二次元に描画した。

まず、目につくのは、左隅で孤立している「ぱーじぇーろ」だ(一つの単語として検出できたことが、地味にすごい)。どうやら仲間外れらしい。歌集のなかで1度しか使われず、用法も「ぱーじぇーろ、ぱーじぇーろって時として」と浮いているからか。右端の中央付近をみると、「家具」「山」「世界」「道」が近くにある。それぞれを含む歌には次のものがある。
- 君が山羊、山羊が羊にかわるころ品のよい家具屋で暮らしたい
- 朝刊が濡れないように包まれて届く世界の明日までが雨
- 駅前の道に溢れる宗教のひとびととあふれだす宗教
- あれが山、あの光るのはたぶん川、地図はひらいたまま眠ろうか
単語ベクトル図に戻ると、中心部はごちゃごちゃしている。「あなた」は「わたし」と少し近くて、「私」からは遠い。「私」は「恋人」よりも「電車」に近い。「外国」は遠い。「死ぬ」のと同じくらい遠い。
6-2-5-2.「連作」単位の連作ベクトル
「連作」単位の単語ベクトルを元に、「連作」ごとの距離を計算し、描画した。
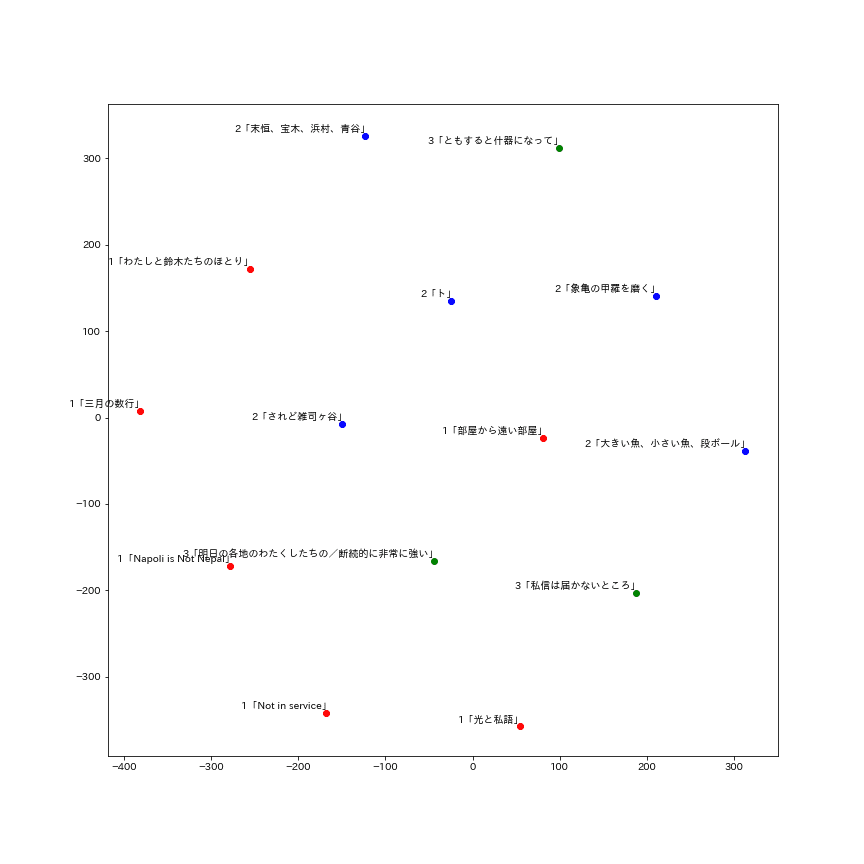
連作間の距離が、なぜ近いのかは、この描画だけでは説明できない。とはいえ、傾向を読みとるなら、第1章の各連作が、ひとつのまとまりを形成していると分かる(図の左下)。第2章も、それぞれの距離が近い(図の中央から右上)。例外は第1章「部屋から遠い部屋」と第2章「されど雑司ヶ谷」で、前者は第2章の連作に、後者は第1章の連作に近い。第3章のうち、「ともすると什器になって」は、第1章より第2章に意味が近い。この歌集では第2章「末恒、宝木、浜村、青谷」「象亀の甲羅を磨く」の次に収録されていて、意味の隔たりが少ないようだ。他方で、「私信は届かないところ」「明日の各地のわたくしたちの/断続的に非常に強い」は、第1章に近い位置にある。
考察
この平面は高次元データを次元圧縮したもので、方向や向きに意味はないけれども、距離には意味がある。この歌集は、第1章と第2章にそれぞれ「まとまり」を形成するような意味が生じていて、第3章では、さらに意味の跳躍が行われる。そういう構成だと言える。著者・編集者が意図した/しないによらず、そのような文脈が生まれている。
6-2-5-3.「あなた」と距離が近い単語

「あなた」と距離が近い単語を20ほど選んで描画すると、このような平面になる。距離が近い「サーカス」「川」「浜村」を含む歌は、次のとおり。
- サーカスのテントが建てばそこからの季節がいやに広々とあり
- あれが山、あの光るのはたぶん川、地図はひらいたまま眠ろうか
- 繰り返す土地にいつしか駅が建つ 末恒、宝木、浜村、青谷
考察
連作ごとに学習したからか、意味の遠近が人間には解釈しづらい。短歌1首ごとに学習させた場合はどうか。
6-2-6. 短歌ごとに学習
6-2-6-1.単語ベクトル(500個を抽出)

「あなた」は「家」「猫」「届く」「買う」に近く、「私」は「ひと」「開く」「住む」に近い。
6-2-6-2.「1首」単位の連作ベクトル
「1首」単位の単語ベクトルを元に、連作ごとの距離を計算し、描画した。

短歌1首ごとに学習させると、連作の位置づけも変わってくる。しかしこの場合も、「三月の数行」を除けば、第1章の連作には一定のまとまりが観察できる(図の中央から右下半分)。第2章も、第1連作「大きい魚、小さい魚、段ボール」を除けば、それぞれ近い距離にある(図の中央から左半分)。第3章「ともすると什器になって」には、やはり第2章の隣接する連作と近い意味が生じていて、続く2つの連作「私信は届かないところ」「明日のわたくしたちの/断続的に非常に強い」は、第1連作に近い距離にある。
考察
連作単位の学習と差分はあるものの、第1章、第2章それぞれに意味のまとまりが生じていること、第3章はそれぞれ別の距離にあることが分かった。この手法を用いれば、連作や章立て、巻数など、やや大きな単位の構成に何らかの制約が働き、結果として意味が生じることを、測定量として表現できるのではないか。また、なぜ学習単位を変えると、「意味が遠い」と見なされる連作が変わるのかも、探求する余地があるだろう。
6-2-7.「あなた」に似ている10の言葉
ある単語とよく似た単語を「選抜」したり、その単語から別の単語の意味を「引き算」することもできる。試しに、この歌集でもっとも頻出する「あなた」の類似語を上位10語出力してみた。
あなた
ある 0.45
アネクドート 0.30
タオル 0.28
つくる 0.27
乾き 0.26
少し 0.25
白い 0.24
聖夜 0.24
場所 0.24
明日 0.23
```
「あなた」が「ある(存在)」と「アネクドート(修辞)」に近い文脈にある、という結果になった。「あなた」から「私」をなくしてみると、どうなるか。
あなた - 私
ある 0.35
暮らす 0.30
繰り返す 0.30
動物 0.29
役 0.29
乾き 0.29
よろしい 0.27
アネクドート 0.25
帽子 0.25
手のひら 0.25
持続を示す動詞(ある、暮らす、繰り返す、乾き)があがってきた。「ある(存在)」と「アネクドート(修辞)」との距離は近いままだ。ひとつの予想として、この歌集では、「私」という語が、「存在(ある)」や「修辞(アネクドート)」に近づくような用法では使われていないのかもしれない。少なくとも、「あなた」ほどには。
二次元に描画してみると、このようになる。

6-2-8.さまざまな単語の類似度トップ10
ほかにも、出現数の多い単語からいくつか選んで出力してみよう。
人
あと 0.33
しみる 0.33
毎週 0.26
東西 0.26
今日 0.25
する 0.25
みどり 0.24
距離 0.24
横たわる 0.24
近づく 0.24
「時期」(あと、毎週、今日)や「移動」(しみる、する、横たわる、近づく、東西)にまつわる語が、「人」という字と近いものだと判定された。
部屋
訃報 0.30
換える 0.29
問う 0.28
右脳 0.28
生きる 0.26
髪 0.26
溢れる 0.24
画面 0.24
右手 0.24
向く 0.24
「部屋」は、向きと勢いを持つ動詞(換える、問う、生きる、溢れる、向く)と似ていて、ひとのからだ(右脳、髪、右手)にも近い。それにしても、「訃報」と「部屋」はなぜ似ているのか。
犬
借り物 0.28
しかるべき 0.28
屋上 0.27
薄い 0.27
会話 0.26
火事 0.26
漁船 0.25
指紋 0.25
池袋 0.24
ローソン 0.23
「犬」は場所(屋上、漁船、池袋、ローソン)とできごと(会話、火事、しかるべき)に似ている。もの(借り物、指紋)にも。ほかの動物や乗り物が出てこないことにも気づかされる。
考察
今回は、試しに「連作」をひとまとまりの文書として学習させた。短歌間のつながりが見れるかなと思ったからだ。そのため、異なる短歌作品だが、前後に配置されている短歌は同じ文脈に出ている。例えば、"Smoking"と"あなた"は同じ短歌には出てこないのに、出てきたりする。
学習の単位をどう指定するかは工夫のしどころになるだろう。「文書」ごとがいいのか、「文章」ごとがいいのか。「文章」ごとで学習して、「連作」ごとになるように、あとで計算してもいいかもしれない。今回の分析では、同じ単語を使っているか、類似する単語として近いものが配置される。さらに、たとえば、作中で何らかの関係を明示的に持たせた言葉が表示できたりすると、面白い。