
【10.おわりに】現代短歌のテキストマイニング――𠮷田恭大『光と私語』(いぬのせなか座)を題材に

(承前)
10-1.感想
私たちは今回、形態素解析とその計量によって、「作品」全体の俯瞰を試みました。たのしかったです。簡単な集計でもたくさんのことが分かりますね。むしろすぐにできて、分かりやすい。それを起点として、探索的な考察も深められます。豊富なテキストデータがあるなら機械学習を行えるでしょう。もし少なくても、ドメイン知識を活かして、作れる統計を作ってみることが大切です。
分析の目的もひとつではありません。たくさんあって分類が大変だとか、読むのに楽したいとか。読み方の提案を受けたいとか、第三者意見がほしいとか。新しくて難しいことに、無理していつも挑まなくてもいいのです。必要に応じて、求められることをやるだけでも、役立つことはたくさんあるのですから。
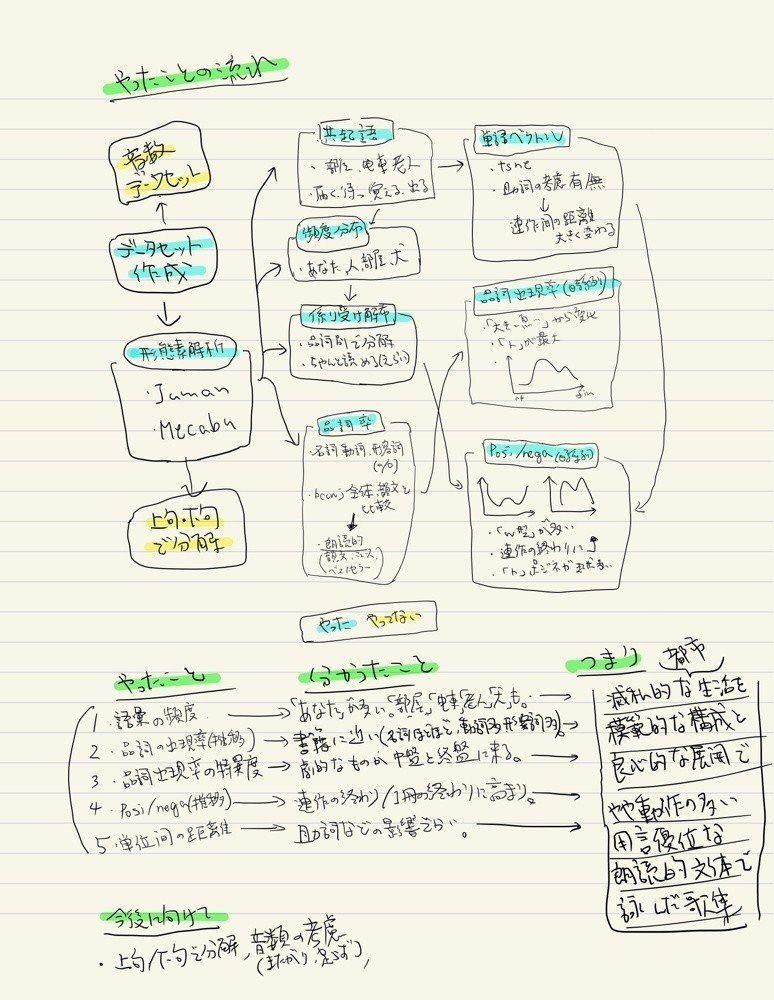
10-2.分かったことのラフイメージ
分析作業のなかで分かったことをまとめた、手書きのメモも残しておきます。途中経過を書き出したもので、細かいニュアンスはちがっているものの、何かの参考になればと思います。
10-3.さらなる分析のために
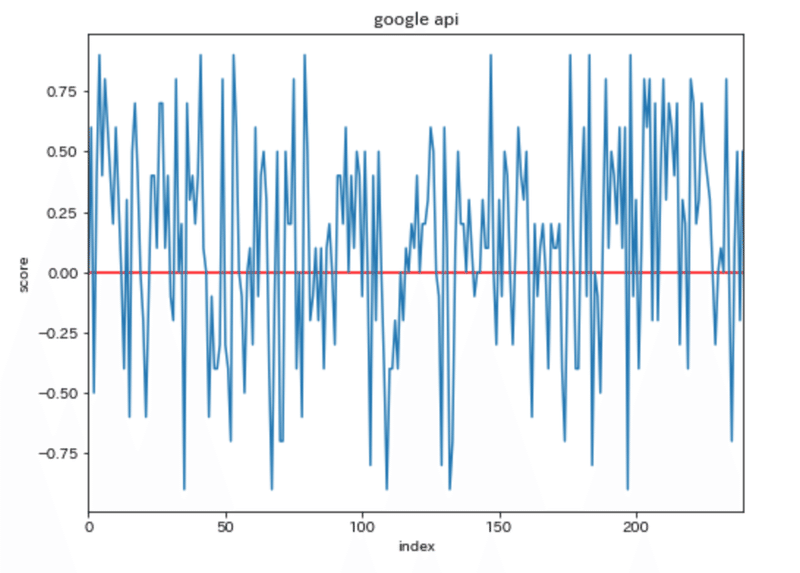
分析アプローチを考え、実践することで、初めてわかることもありました。歌集の構成要素が見えてきました。機械学習アルゴリズムの癖も分かってきました。たとえば、極性分析(ポジネガ分析)は奥が深いです。指標の算出式や、判定のもとにするコーパスによって結果が変わります。「何をどのように学習させるか」の選択には、すでに意図が生じるということでもあります。今回はGoogleのAPIを採用しましたが、他にも2つの判定器を試しました。テスト結果は次のとおりです。横軸は1文の出現順に番号(index)であり、縦軸は極性スコアを表します。スコアが0となる位置に赤い直線を引いています。
GoogleのAPIによる極性スコア算出
単語感情極性対応表による極性スコア算出
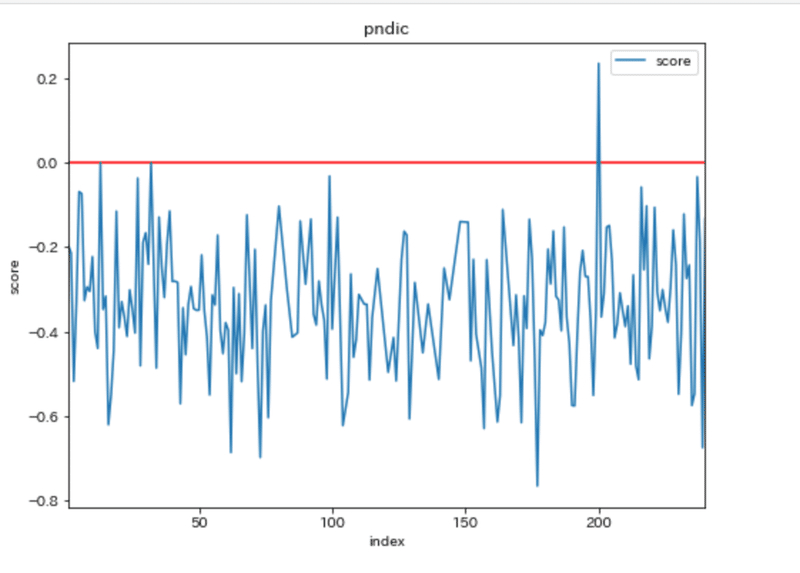
使用:単語感情極性対応表(出典)
asariによる極性スコア算出
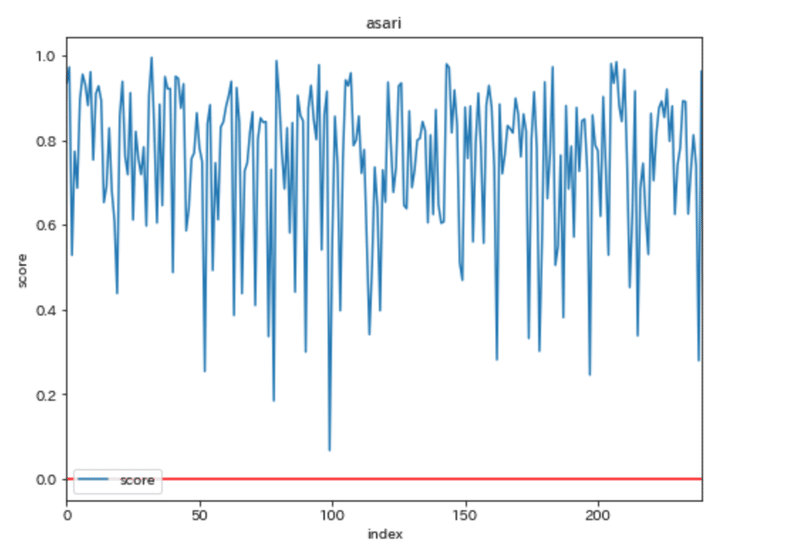
使用:asari(出典)
10-4.考察(分析全体を通して)
それぞれのポジネガ辞書の設計思想や計算方法を調べることで、物語(ストーリー、シナリオ、プロット)とは何かをめぐる、新しい視点が見いだせるかもしれません。題名や目次・構成から感じる印象も考慮できると、さらにいいですね。
単語埋め込みベクトルは、今回の分析結果を、他のテキストと比較しないとなんとも言えません。どれがどれに「近い/遠い」と言われても、だからなんだという気もします。単独著者の単著はどうしても似てしまいがちです。複数人による編著や、様々なテキストを包括する文書群に適用したほうが、思いがけない意味のつながりを見つけやすいかもしれません。歴史的な影響力の大きい流派ーー例えば、アララギ派の諸作と比べると、どうなるでしょう。ある視点で、ある単語が果たす役割がみえるとおもしろいですね。「赤い」とか「電車」とか。重要文書抽出による、作品の推薦にも応用できます。
品詞構成率は、ジャンルごとの基準値を算出して、全体と比べて月並みであるとか、突出しているといったことが言えるとおもしろいでしょう。分類を行うなら、一致度を表示できると参考になりそうです。作品全体がもたらす、なんとも言いがたい印象を、いくつかの指標に基づいて可視化し、判断できると楽しいですね。新しい作品解説の方法としても役立つでしょう。
今回は、約物やかな・仮名変換など、表記レベルの分析には踏み込みませんでした。かっこや一字空け、改行の効果を分析する余地はあります。句切れの判定や、係り受け構造との関係も重要でしょう。単語の出現順やページ数などの、時系列を考慮した分析も行いませんでした。
ひとことで「作品」と言っても、単語、文節、一文、連作、章、全体といった切り口によって、その性質は大きく変わってみえます。さらに進んで、概念レベルの異なる関係性を評価できると、より多くの発見が得られるのでしょう。たとえば、ある単語の出現傾向が、連作の流れをどう方向づけているのか。いくつかの手法がすでに提案されています。文芸書の著者/読者にとって、何が分かると嬉しいかを先に考えたいところです。
10-5.作図NG集
試しに出力してみたけれど、使わなかった図もあります。
共起語ネットワーク(失敗)
まるで「あなた」が一点透視図法の消失点みたいだし、たくさんの言葉が放射速度線のように「あなた」から飛散しているようにも見えます。そう見えるのは、出力設定のバグのせいなのだけど、ちょっとおもしろいですね。
1首あたり単語数(連作別バブルマップ)
1首あたりに用いられた単語数も計算できますから、その描画も試してみました。この図は、縦軸に連作名(昇順)、横軸に収録順(通し番号)をとって、1首あたりの語数が多いほど、大きなバブルマップになるよう出力したものです。
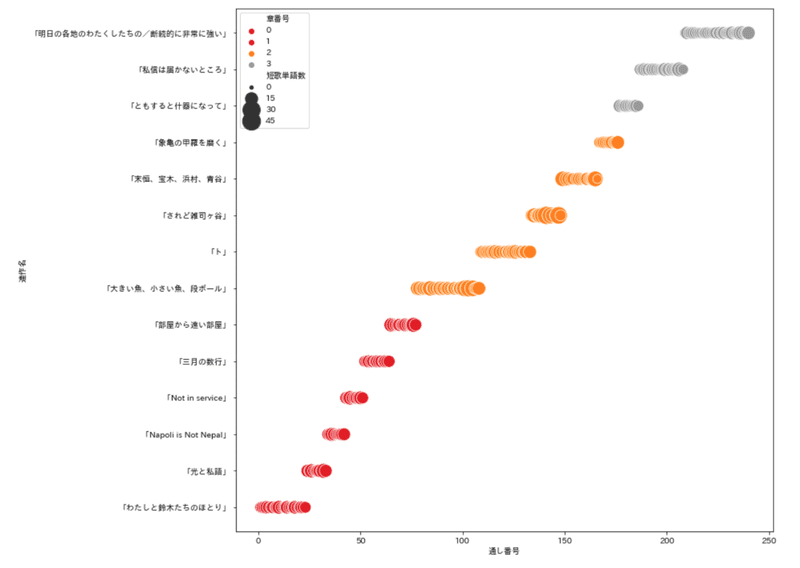
1首あたりの文字数がほぼ変わりませんから、これといって際立った差は見られません。分析単位ごとに語り手や登場人物数のちがうテキストをこの方法で表示すると、どこでモードチェンジが起きたか分かりやすいでしょうか。
1首あたり単語数(ヒートマップ)
1首あたりの単語数を、色の濃淡で示すこともできます。四角く切り出された木星のような出力になりました。136首から148首区間で、単語数が色濃くなるところがあります。
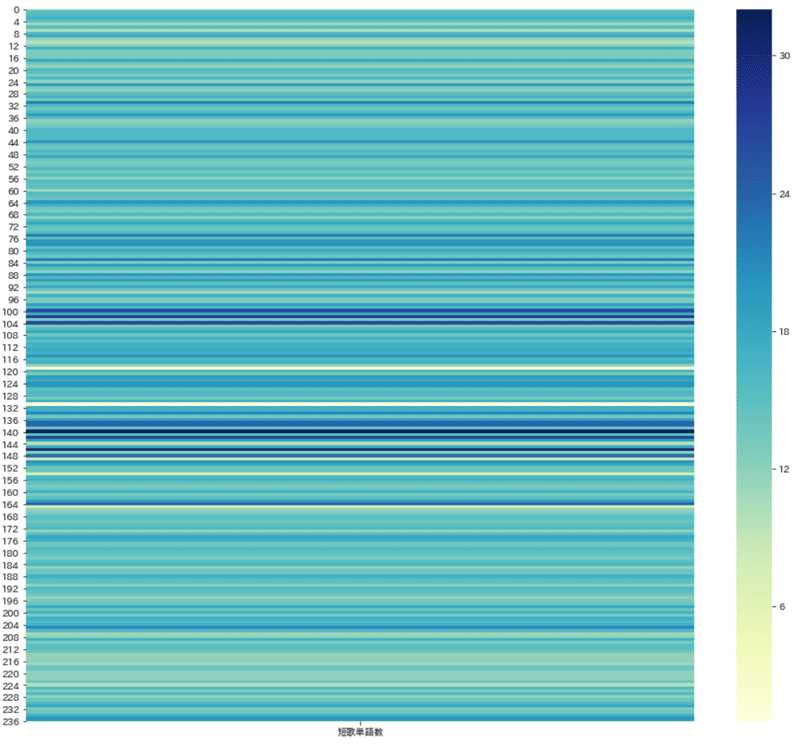
この方法は、十分に編集された短いテキストよりも、ある書き手が長い間かけて書き続けた、未整理のテキストに用いたほうがよさそうです。外国語の上達だとか、言葉づかいへの注意深さの変遷が浮かび上がるでしょう。
10-6.みんなで使えるテキストを集めたい
最後に、データセットの構築について述べます。近年の著作権法の改正によって、情報解析や機械学習のための著作物使用は、著作権者の同意を得ずに行っても適法とされました。とはいえ、電子テキストで流通する歌集は少なく、有償コーパスは個人研究には高価です。一般公開されていても、商用利用が許容されないこともあります(利用交渉すればいいのですが)。データの調達が難しいと、テキスト分析を気軽に始めづらいでしょう。歌集を刊行する出版社が合同で、テキストデータのデジタルアーカイヴを構築し、学術研究のために専門家へ提供する仕組みが作られないものでしょうか。長い歳月をかけて、古典籍の研究がそうなったように、現代短歌の分析も、まだまだ発展できるところが大いにあります。
そのためには、何はさておき、信頼できるまとまった量の書誌データが欠かせません。母集団にしうるデータは、openBDから取得できます。版元ドットコムと株式会社カーリルが共同で提供するものです。けれど、そこから短歌に分類できる著書を抜き出すのは骨が折れます。出版社の枠を越えたリストの元データが、研究者向けに開放されるだけでも意義はあります。市販書ならそれで事足りるとして、結社誌や同人誌、個人制作はさらに難しそうです。『短歌年鑑』の目録でカバーしきれない、新聞投稿欄の選歌はどうすればいいのでしょう。課題は尽きません。裏返せば、将来にできることは、まだ山ほどあるということです。
この記事が気に入ったらサポートをしてみませんか?