
AI Labの立ち上げから1年が経ちました

こんにちは、imaimaiです。
12月になり、CADDi AI Labは一年を迎えました。せっかくなので振り返りをつらつらと書いていきます。
AI Lab立ち上げまで
私が入社したきっかけは、プラットフォームとしてのCADDiに貯まるデータの特異性と活用の幅の広さゆえでした。入社当時(2021年1月)、その頃MLエンジニア(MLE)やデータサイエンティストは一人もおらず、私が時間の合間に探索していた程度です。それで書いたのがこのnote。
そしてこれに反応してくれたばんくし(@vaaaaanquish)こと河合に対し、ただフォロー・フォロワー関係だっというごく薄い関係から私が強引にDMを送りカジュアル面談にこぎつけたのが始まりです。河合の入社も決まり、CEOの加藤からの力強い言質後押しの言葉も得て、2021年12月にCADDi AI Labは誕生しました。

発足当初に、Missionを設定しました。今もこれらを合言葉に日々取り組んでいます。

OKRで振り返るCADDi AI Lab
さて、CADDiでは目標設定として、会社全体でOKRを採用しています。この一年を振り返ろうと思い、どうしようかなと過去のOKRを振り返っていたのですが「それをこのまま並べたら良くないか?」という事に気づいたので、AI Labがメインで携わったOKRを公開します。
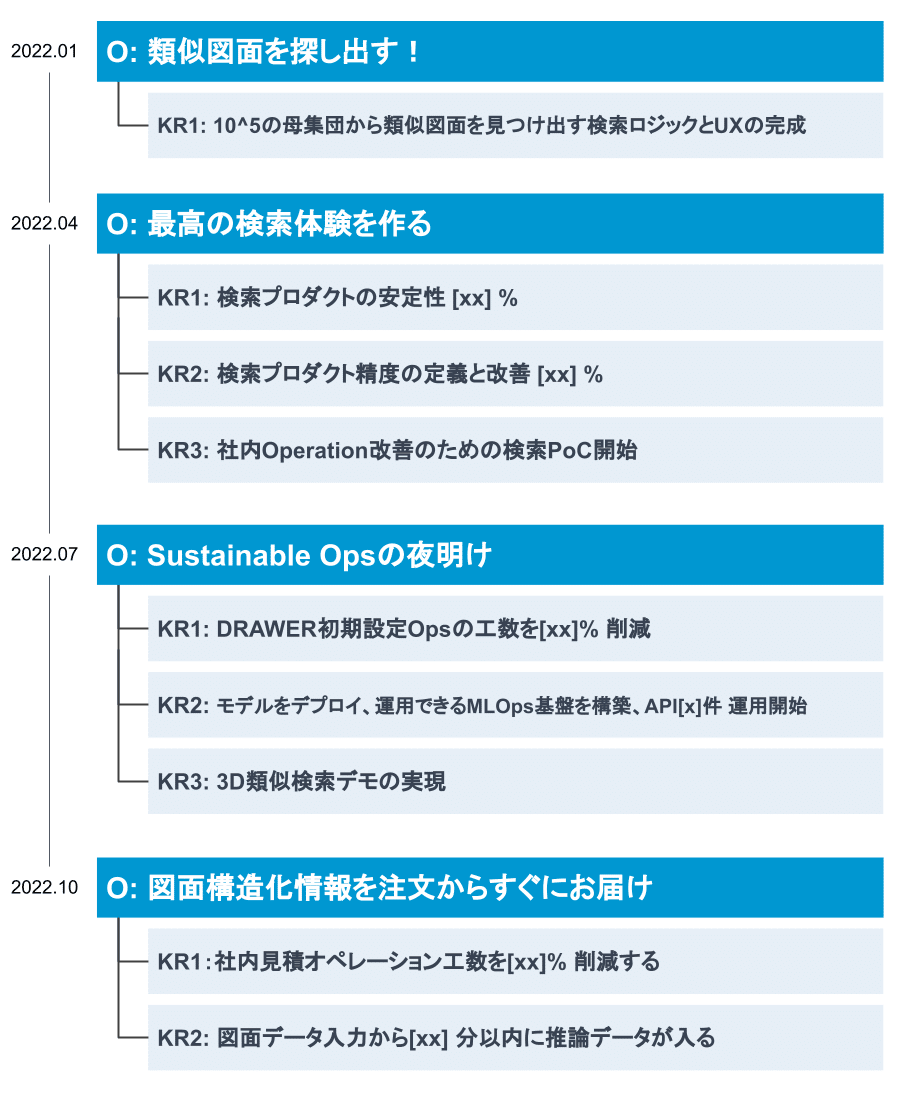
OKRで意識していたのは、
☑ "作ったけど使われない"にならないよう、提供する価値で語ること
☑ R&D的な探索と価値提供のバランスを保つこと
☑ 形骸化しないよう、日々の開発で達成への強度を保つこと
です。振り返ってみると、CADDiのSaaSであるDRAWERのコアアルゴリズムの検証から始まり、徐々に社内オペレーションなどへの価値提供の幅を広げつつ、MLOpsなど、価値提供を素早く行う基盤も整ってきて、一年前と比べると見違えました。
また、個人的には毎度かなりの無茶振りをし、高い水準で設定しているOKRですが、上記のOKR達成率の平均は87%となっており、非常に高いです。それを支えているのはML / MLOps Engineersです。この一年、採用にも非常に力を入れており、実力のあるメンバが次々にJoinしてくれました。

正直、「このメンバでモデリングができなかったらそれはデータか問題設定が悪い」と言い切れるほど良いメンバが集まってくれました。非常に頼もしい限りです。(プロダクトマネージャとしてはそれはそれでドキドキするのですが)。
これからのAI Lab
さて、このように順風満帆に見せかけていますが、課題は山積みです。技術的な課題は今後AI Labのメンバから最高にイケている記事がでてくると思いますので任せるとして、オペレーションや組織、プロダクトの面から書いていきます。

データを活用可能な"アセット"へ
代表加藤のnoteにもあるように、データアセットはキャディ事業推進のエンジンです。
私は最も重要なサプライチェーンアセットは「データアセット」だと考えています。具体的には後述しますが、これは上述した「部品にあった装置の設定の仕方のノウハウ」などを含む広い意味でのデータをもとに、同じ思考・同じ作業をしなくていいようにしていくためのアセットです。
1年前は私が適当にいじっていただけの社内データに対し、MLEが増えたことでよりスコープが当たるようになりました。それに伴い「モデルの結果を見ていたら、推論結果よりもデータの方が間違っている」という声を聞くようになりました。こちら、入力のヒューマンエラーもあるのですが、実際はそれ以上に複雑な問題があります。
CADDiの事業が絶えず変化する中では、作るべき製品も変わります(データドリフト)。また、データを入力するオペレーションルールも事業変化を反映し、変更されます(コンセプトドリフト)。実際に「その時の」オペレーションを回すためだけならば問題はないのですが、後々分析や学習に使うときに、データを信頼して取り扱うことができなくなります。これではアセットではなく単なるキャッシュとしてデータが使われているだけにとどまってしまいます。一年前にやったことを今日のオペレーションに活用するにはまだ壁があります。

AI Labは「データを最も活用する組織」という立場から、信頼性の高いデータを集められるように仕組みづくりをしていく必要があります。この実現には、社内データ集積オペレーションの共通化、バージョニング、そして変化を検知するシステムなど、いわゆる「データエンジニアリング」がいよいよに重要になってきています。また、共通プロトコルとして"MO CAD"という独自のCADフォーマットを作るプロジェクトも始動し、入り口からデータをきれいにする動きも並行して進んでいます。
キャディの中では始まったばかりである真の意味でのデータのアセット化。チャレンジしていくメンバを募集しています
機能組織から、より"プロダクト志向"の組織へ
価値提供を意識した目標設定にしてきたものの、うまくいっていることばかりではありません。今年の10月から実際のオペレーションチームと連携して目標を追っていますが、Opsのいち部分にMLを導入するという形になっています。これ自体も効果は出せるのですが、本当に正しいのか?と考えることもあります。
理想的には、依存関係は逆で、「MLを元にしたOpsを全体で設計し、その検証、導入を進める」になるべきだと思います。そのためにはより事業に深く潜り込み、価値提供を実現していくチームを実現する必要があります。プロジェクトによりAI活用の信頼を勝ち取るとともに、tech全体としてこのような体制を取れるように動く必要があります。

そのためにも、事業価値とMLをつなぐTechnical Product Manager / ML Product Managerは今後ますます必要になってきます。より本質的な改革を目指すメンバを募集しています。
図面から"製造業のデータ"へ、眠っているデータを活用
図面は製造業におけるコミュニケーションの媒体です。そのため、解析をして情報として構造化することが各工程において価値創出の源泉となります。一方で、図面データは「媒体」でしかなく、「実績」を伴って始めて洞察を得られるアセットとなります。
例えば、サプライパートナー(SP)の製造の効率化を行おうとすると、製造実績が必要になったり、品質の強化だと実際の検査のデータが必要になります。今後の事業成長のためには図面メインの解析から巣立ち、更に大きな「製造業全体の実績データ」へ羽ばたく必要があります。
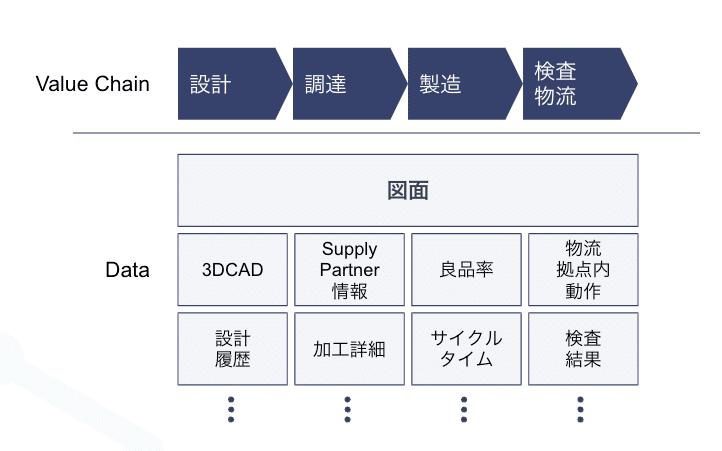
すでに製造・検査に関してもデータの収集をし始めています。これらのすべてが構造化されているわけではありません。溜まったデータを料理し、価値へと変えていくことが重要になります。
また、これは組織課題でもあります。全体事業でフォーカスが定まっている中で、このような「探索」を推奨し非連続な価値を産み続けられる体制にしていくためにはどうすればよいか。このあたりの議論もtechチーム全体で進め始めました。
非連続的成長を起こすR&Dの実行や組織設計に興味のあるMLEやEMを募集しています。
最後に
立ち上げて一年ですが、楽しいメンバーと面白いデータ、ヒリヒリする事業課題に囲まれて楽しく過ごしています。
私は今の時代、ソフトウェアエンジニアがずっと同じ組織にい続けるとは思っていません。私も含め、どこかのタイミングで新しい挑戦をするでしょう。ただ、いつか振り返って「あの頃のCADDi AI Labは最強だったよね」と言える組織とプロダクトをチームで作っていきたい。そのためになら何でもやるつもりでいます。AI Lab 2年目も頑張っていきます、よろしくおねがいします!
サポートいただけると励みになります! よろしくおねがいします!!