
Amazon Bedrockを使ってみた

最近、生成AIの盛り上がりにのってAmazon Bedrockを色々と試してみています。
初回となる今回は、Amazon Bedrockの簡単な紹介から始まり、AWSコンソールで使ってみる、というところまで。
次回以降は、実際にアプリとの連携という実務的な部分にフォーカスします。
Amazon Bedrockとは?
Amazon Bedrock(以下、Bedrock)は、2023年9月28日に一般公開され、10月3日より東京リージョンでも利用可能となったAWSが提供する生成AIサービスです。
Bedrockは、フルマネージドの生成AIサービスであり、ユーザーはインフラの構築やスケール、モデルの作成に関わることなく、簡単に生成AIの機能を利用することができます。
呼び出しは、API経由で行われ、AWS SDKやCLIを利用して、実行することができるため、アプリケーションに組み込むことが容易になっています。
Bedrockでは、複数のAIモデルが提供されており、それぞれのユースケースに応じて最適なモデルを選択することが可能です。加えて、ユーザーはファインチューニングを通じて、カスタムモデルの作成や利用が可能になっています。その他にも、RAG(検索拡張生成)という技術を利用することで、より精度の高い情報提供を実現することができます。
セキュリティ面においても、VPCエンドポイントの提供により、安全な環境での利用が可能です。さらに、CloudWatch LogsやS3との連携を通じて、ログの出力も容易に行えるようになっています。
ただし、Bedrockは東京リージョンで利用可能ですが、まだ機能が限定されているため、フル機能を利用するためには、バージニア北部リージョンでの利用を検討する必要があります。
※日本語に対応しているモデルは、現在はAnthropic社が提供しているCluadeのみです。
※ファインチューニングは、東京リージョンではまだ利用はできません
※Bedrockが提供するRAG(検索拡張生成)は、東京リージョンではまだ利用はできないため、Amazon Kendraなどを利用して、構築・実装する必要があります。
生成AIについて
近年、人工知能技術は目覚ましい進化を遂げていますが、特に生成AIは、ChatGPTの登場により注目を集めており、その応用範囲はビジネスから学習、日常的なことまで多岐にわたり、その可能性は日々模索され続けています。
生成AIとは、ユーザーの入力に基づいて新しいコンテンツ(文章、画像、音声など)を生成する技術です。ChatGPTのような会話型AIは、ユーザーの質問に対して自然な文章を生成する能力を持ち、その自然さは驚くべきものがあります。ブログ記事の作成から英語学習、日常の問い合わせまで、生成AIは様々な場面で活用され初めています。
ただし、生成AIはハルシネーションと呼ばれている現象(事実に基づかない情報を生成すること)があり、適切に利用していく必要があります。これは、人や他の情報源と同様に、事実の確認や検証などが必要な点は変わらないということです。
ハルシネーションについては、ファインチューニングやRAG(検索拡張生成)などを用いて、軽減することができ、生成AIの精度を向上させることができます。
Bedrockの利用開始方法
Bedrockを利用するためには、大きく分けると以下の2点を実施する必要があります。
IAM権限の付与
利用したい基盤モデルの有効化
IAM権限の付与
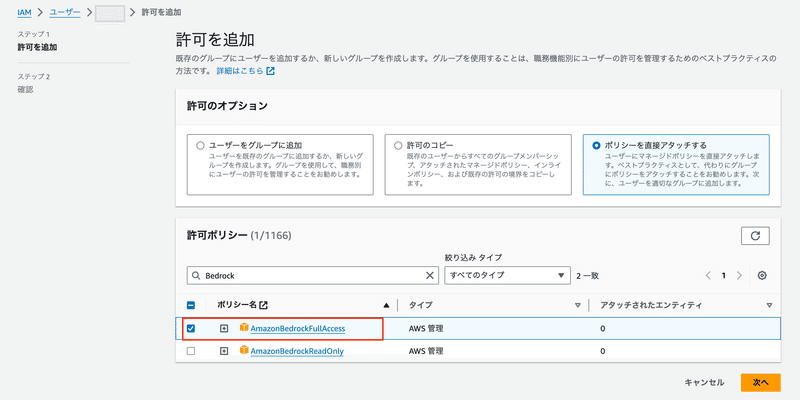
IAMポリシーで該当サービスの利用可能な権限が付与されているかが、AWSにおける最初の確認すべきポイントです。ユーザーやグループ、ロールのポリシーで該当サービスのアクションが許可されているか確認し、無ければ付与します。
AdministratorAccess、PowerUserAccessなどが付与されていれば利用可能ですが、細かく制限している方は、AmazonBedrockFullAccess ポリシーを追加してください。
利用したい基盤モデルの有効化
Bedrockで基盤モデルを利用するためには、利用したい基盤モデルを有効化する必要があり、Model accessというメニューから有効化することができます。

図2の表のAccess statusがモデルのアクセス有効化状態を表しています。
Amazonが提供する基盤モデルTitanに関しては、Available to requestとなっており、有効化のリクエストが可能な状態になっています。
Anthropic社が提供するClaude InstantはUse case details requiredとなっており、これは使用用途を入力する必要があることを意味しています。アクセス有効化などを実施するためManage model accessボタンをクリックして、基盤モデルのアクセス管理画面に遷移します。

今回は日本語対応がされているClaude Instantを利用したいので、使用用途を入力するためSubmit use case detailsボタンをクリックします。

各フィールドを入力しSubmitボタンをクリックしてください。
※私個人のAWSアカウントでは、自分の名前やGitHubのURLで申請してみましたが、特に問題なく利用できるようになりましたので、個人学習などで利用している方は、そういった情報を入力してください。
※この入力フォームについては、AWS Marketplaceを通じて、Anthropic社と契約を結ぶための入力フォームになるようです。契約だからといって固定の料金が発生するわけではないので安心してください。

Access statusがAvailable to requestに変わっていますので、Claude Instantにチェックを入れて、Request model accessボタンをクリックしてください。

Access statusがIn Progressになるので、少し待ち、再度画面を開き直せばAccess grantedになり、利用可能になっています。

以上で、基盤モデルの有効化が完了しました。次は実際に利用してみます。
Playgroundsでの実行
基盤モデルの利用では、CLIやSDKでの利用が基本となりますが、今回は試してみるということで、すぐに試すことができるPlaygroundsというBedrockが提供している機能で利用してみます。

Playgrounds > Chatをクリックして、チャット画面に遷移します。次にSelect modelボタンをクリックします。
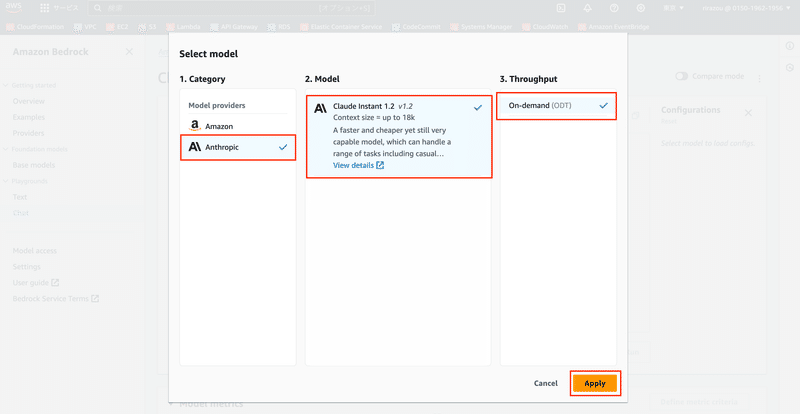
1.CategoryはAnthropicを選択します。
2.ModelはClaude Instant 1.2を選択します。
3.ThroughputはOn-demand (ODT)を選択します。
最後にApplyボタンをクリックします。

画面下部のテキストエリアに、質問したいことを入力してRunボタンをクリックすれば、回答が返ってきて画面に反映されていきます。
Configurationsに関しては、生成する内容を調整するものになりますが、そのままでも問題ありません。各設定項目に関してはインターネットで調べればおおよそ分かるかなと思います。今回は折角なのでCluade Instantに聞いてみます。

それらしい回答が返ってきましたね。こういった形で手軽にお試し利用できるのがPlaygroundsという機能です。
途中で回答が切れてしまったのは、ConfigurationsのLengthという項目が300になっているためです。この値を増やせば一度に出力してくれる文字数を増やすことができますし、続きをリクエストすれば、続きが出力されます。

Lengthについてですが、文字数ではないため少し注意が必要です。Lengthはトークン数という考え方でカウントされます。日本語であれば1文字 = 1トークン未満(1文字 = 0.8、0.9トークンぐらい)ぐらいで考えておくと良いと思います。理由としては、オンデマンドの実行では、トークン数によって料金が決まるため、1文字=1トークンとしていれば、上ブレすることは無いので、思ったよりもかかってしまったという事を防げるためです。
料金について
料金に関しては、AWSの公式サイトを確認しましょう。
オンデマンドとプロビジョンドスループットという2つの料金体系があります。
オンデマンド料金
使用した分だけになり、1トークンいくら、という計算方法になります。特別なことをしない限りは、この料金体系が適用されることになります。
2023年12月時点では、Claude Instantについては以下のとおりです。
入力トークン 1000 個の料金: 0.00163 USD
出力トークン 1000 個の料金: 0.00551 USD
例えば、入力が3000文字なら 0.00163 ✕ 3 で計算しておけば上ブレは無いかなと思います。
注意点としては、チャット形式で利用する場合は、入力トークンには、以前の会話についても基盤モデルに送らないと、今までの会話を考慮した回答が生成されないため、すべての会話を含める必要があり、どんどんと1回あたりのトークン数が増えていくことです。
このあたりはアプリケーション側で制御して、トークン数を抑えることも可能かと思いますが、認識しておく必要があることになります。
出力トークンについては、今までの会話のトークン数は関係なくBedrockが出力する分だけになります。
プロビジョンドスループット
1モデル1時間あたりいくら、のような料金体系です。注意点としてはプロビジョンドスループットは他のサービスであるようなSavingPlanのようなコスト削減に関するプランではなく、大規模に利用する場合など、帯域を確保したい場合に利用する料金体系になるようです。
請求書の見方
請求書に関してですが、請求書の画面では「Amazon Web Services, Inc. - Marketplace サービス別料金」という別枠で料金を確認することができます。

利用したい基盤モデルの有効化の項で、Submit use case detailsボタンをクリック後のモーダルウィンドウで入力しましたが、これはAWS Marketplaceを通じて、Anthropic社と契約をしている形になるためです。
まとめ
Amazon Bedrockの簡単な紹介から始まり、AWSコンソールで使ってみる、というところまでを書きました。
マネージドサービスということもあり、すぐに利用することができるようになりました。実際にアプリなどに組み込むとなると別の大変さが発生しますが、AIを利用するためのモデルの作成などが不要で、かつ利用するためのサーバーやAPIなどの用意が不要なことは分かっていただけたと思います。
次回以降は、アプリに組み込むという実務的な部分で簡単なサンプルを作ってみます。
関連記事
この記事が気に入ったらサポートをしてみませんか?