
♡恋愛で学ぶ統計学♡(No.15 共分散構造分析・SEM: モデルフィットの指標; 私たちの相性っていいの...?)

こんにちは。
今回も、恋愛のシチュエーションを例に挙げて
一緒に統計学を学んでいきましょう!
この記事で取り上げるのは、「共分散構造分析」や「SEM」と呼ばれる統計分析(以下はSEMに統一しますね)に使われるモデルフィットの指標です。
そもそもSEMとは何なのか?
SEMは「Structural Equation Modeling(構造方程式モデリング)」の頭文字をとったものです。
このSEMは、「多変量解析」に分類されます。
SEMを用いることで、通常では測定できない「やる気」や「頭の良さ」などという概念も含めた相関関係や因子分析を行うことが可能になるのです。
もう少し詳しく知りたい!という方は下の記事も合わせて読んでいただけると嬉しいです。
それでは、本題の「モデルフィットの指標」についてです。
モデルフィットの指標のことを「適応度指標」と表現することがあります。
SEMでは、自分が考えるモデルを作成します。
例えば、下のようなモデルを作りました。

これは、私が勝手に作ったものです。
「勝手に作る」というのは、私の持論のもと仮説を作って、その仮説を表すモデルを作ったという意味です。
SEMでは、自分が考える事象の構造を仮定し、データをもとにモデルを作ります。
私のモデルだと、コミュニケーション能力(コミュ力)は「話をきくのが好きかどうか」、「話をするのが好きかどうか」、「SNSのフォロワー数がどのくらいか」で測定できると考えています。また、モテ度(どれだけモテるのか)は「これまで付き合った人数」と「ヴァレンタインでもらったチョコの数」で測定できると考えています。
こんな風に、普通測れない「コミュ力」や「モテ度」をも、データを用いてその関係性を分析しようとするのがSEMです。
そして、気になるのは、このモデルが妥当なものかということです。
自分の持論やこれまで同じようなことを考えてきた人の意見を参考にして仮説を立てたこのモデルが、実際に集めてきたデータから考えると、どの程度妥当かを判断できないといけません。
このモデルはあくまで「勝手に」考えたものです。
ですので、モデルが見当違いの構成になっていたら、仮説が間違っている可能性があるのです。
もう少しかみくだいて考えてみましょう!
例えば、あなたは、最近お付き合いをはじめたパートナーがいるとします。
私とパートナーの相性は、ものすごくいいんじゃないかな!と予想をしました。本来なら数値化なんてできませんが、無理やり数値化しましょう。

性格は90%、趣味は80%、笑いのツボは95%と予想しました。
かなりいいですよね!
SEMでは、このようにデータを行列で考えます。
では、実際に一緒に過ごしてみて、予想ではなく実際の相性がだんだんわかり始めます。それを行列で表してみましょう。
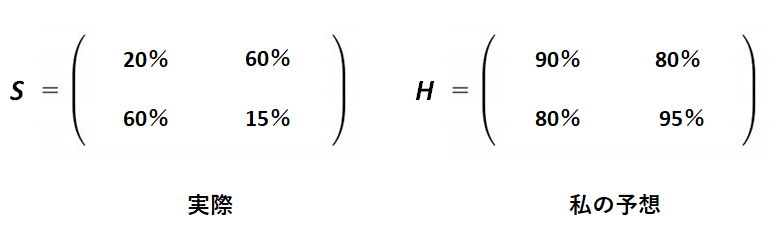
かなり、実際と予想に乖離がありますね、、、
悲しいです、、、、
もちろん、私の予想というのは、実際の状況から予想しているものです。
ですが、数値で計算すると、私の予想したものと実際の数値は、値として違いすぎます。
ですが、パートナーとはとても仲良く生活していて、何の問題もありません。
ですので、今回考えた「相性のモデル」を「性格」、「趣味」、「笑いのツボ」で考えたのがいけなかったのではないかと考えることができます。
もしかすると、「相性」というのは、ほかのもので測った方がいいのでは?と別の仮説を考えることができるのです。
では、ここでまた統計学に少し戻りましょう。
先ほど、例に挙げた、実際の行列というのは、私たちが統計で集めたサンプルデータの情報と考えられます。
統計学では、それを標本共分散行列(S)と考えられます。
また、私の予想の行列は集めたサンプルデータを用いて推定をした結果の行列と考えます。統計学では、∑(θハット)で表し、推定値の行列と捉えます。
これらの行列の情報や自由度を用いて、自分の考えたモデルが実データとフィットしているのかを考えるのです。
それが、「モデルフィットの指標」です。
では、具体的に、どんな指標があるのかを見てみましょう。

かなり多くの指標があります。
近年では、1つの指標だけでモデルを判断せず、いくつかの指標を総合的に見て判断するようになっています。
また、指標ごとに、その算出方法がかなり異なります。
例えば、カイ2乗であれば、次のような式になります。
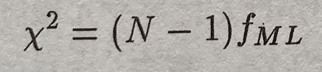
Nはサンプル数で、fMLは適合度関数(推定値を算出するための関数)のことです。
これをみるとカイ2乗の値はサンプル数が多ければ多いほど、その値が大きくなってしまいます。つまりサンプル数にかなり依存をしています。また、その値が大きいほどモデルは悪いと判断されてしまいます。
ですので、大きなサンプルを対象にした分析の場合、この指標はあまりあてにならないと言えます。
ほかにも、RMSEAの式は以下のようになります。

これをみると、カイ2乗が出ていますが、分母にNがあります。
つまり、サンプルが大きくなりχの2乗が大きくなっても、分母のNも大きくなるため、Nに依存しない指標と言えます。
またCFIの指標は、こう表せます。
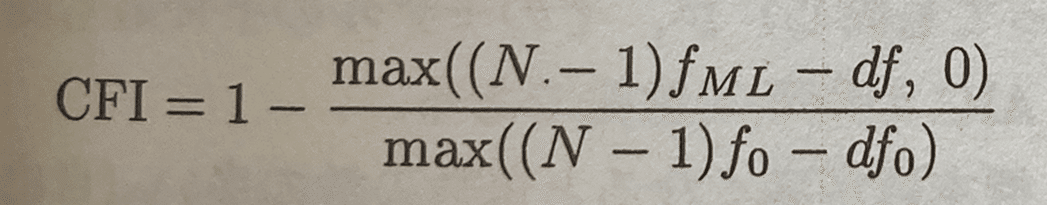
これは、推定したモデル(fML)と独立モデル(f0)とを比較して、考える指標です。
こうした、いくつかの指標をもとに、自分が考えたモデルがどの程度よいものかを判断することができます。
しかし、そのモデルの適応度は、あくまであなたが集めたデータから言えることです。ほかのデータで行った場合、また別の結果がでることもあります。
しかし、だからといって意味のないものではありません。
社会の構造や人の心というような捉えようのないものを考えれば、例外があるのは当たり前です。
ですが、このようにSEMを使って、その考えた構造やモデルが、「自分が調べた範囲では」考えることができた。と言えるのです。
しかも、定量的にです。
なんの根拠もなく、私の仮説は正しい!というよりはよっぽど、いいですよね!
それにしても、、、
パートナーとの相性を決めるモデルなんてあるのでしょうか、、、
そんな研究があったら、ぜひ参加してみたいです(笑)
この記事が気に入ったらサポートをしてみませんか?