
漫画バンクの分析


2022年の漫画バンクについて、分析したことを書いていきたいと思います。
主にデータの分析についてです。
過去 6 ヶ月間、ひたすらひとつの違法マンガサイトを見ていた。
ずっと見ていたのは公開されたマンガコンテンツではなく、サイト運営者が作ってるデータをひたすら見ていた。
11 月の 4 日、15 時くらいにサイトをたたんだのを確認した。
2021/11/17 はこんな状況 https://pastebin.com/fTcHK0ti

記事
Manga Publisher Wants to Sue Huge Piracy Network, Needs Google's Help * TorrentFreak
https://torrentfreak.com/manga-publisher-wants-to-sue-huge-piracy-network-needs-googles-help-211101/
'Shueisha’s application and proposed orders/subpoenas can be found here (1,2,3,4 pdf)' の書類が興味深い。
翻訳記事
https://gigazine.net/news/20211104-manga-shueisha-googles-piracy-mangabank/
おそらく、この翻訳記事 (2021年11月04日 14時00分)が公開されたことで、サイト運営者が違法性を自認して、サイト閉鎖を決定したのではないかと思われる。
2021.12月中頃、mangabank.org とはまた別のドメインで再開している。
画像ファイルのあるアドレスのドメインを whois したところ、cloudflare の管轄のホストではなさそうな感じ。

または、cloudflare 。
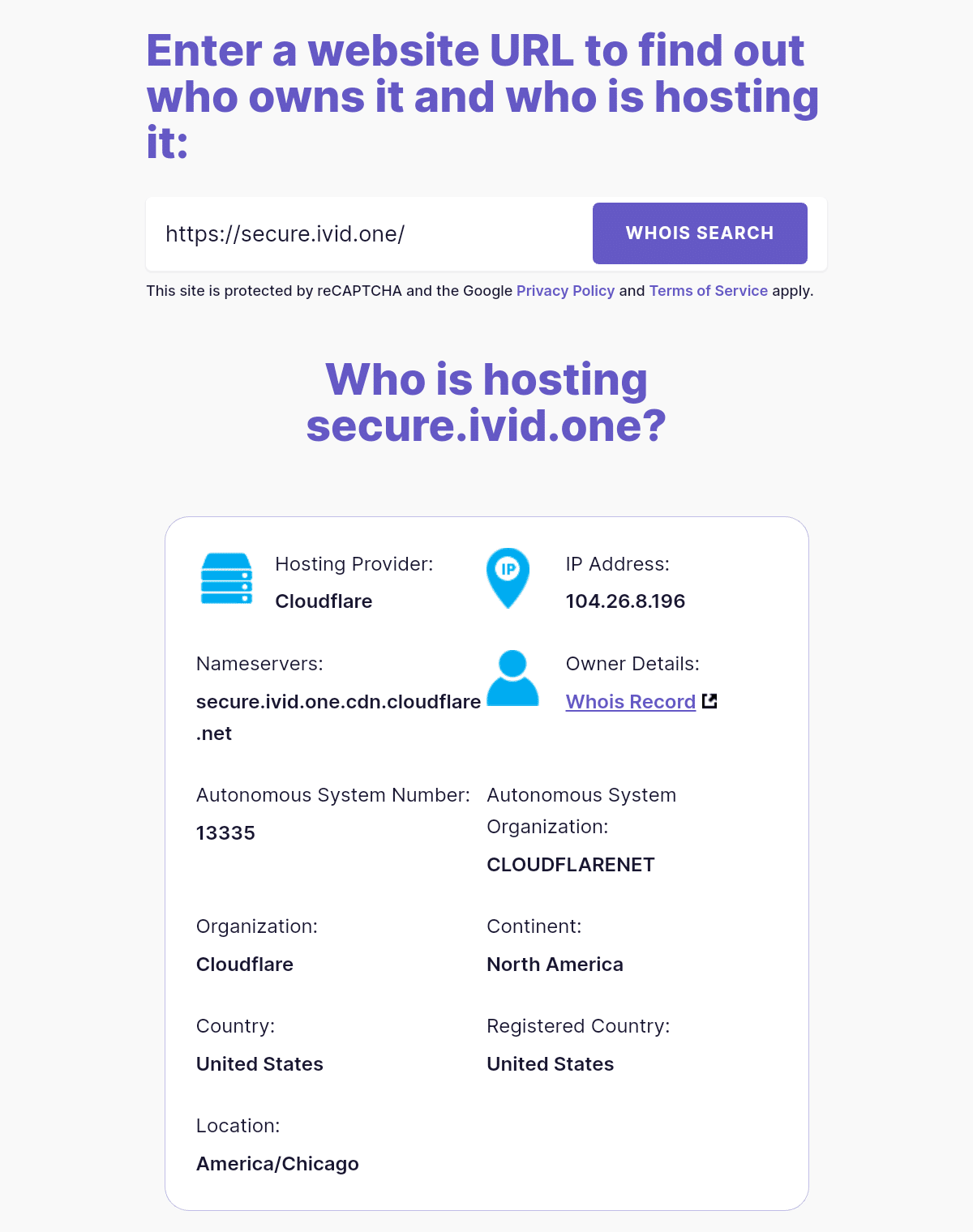
example: https://digital.com/best-web-hosting/who-is/#search=i4.skyly.org参照: https://crieit.net/boards/manga-B
過去に書いたこのような記事は、当時、宣伝につながらないように配慮して明記しなかったが、全て漫画 BANK についてのことだった。
以下、2021年11月04日 以前
https://qiita.com/dauuricus/items/563cbcc9776f66cb672e
6 月の時点では 5 万ページぼどだと思っていたが 10 月には 6 万ページ以上あることがわかった。
この 6 万ページというのはマンガコンテンツの漫画の総ページ数のことではなくて、URL のことで、そのひとつの URL に 30 点から 300 点ぐらいの画像ファイルの URL が埋め込まれている。
その画像一枚が、漫画のスキャン画像ファイルの一点に相当する。

画像点数にすると、空想すると数えたことないおおきな数になるので、いずれいつか数えようと数えなかったが、その 6 万ページについては 著者 / 漫画のタイトル / 公開されていた URL / アップデート日時の情報 / 付与されていたタグ のデータのセットを記録した。
スキャン画像のファイルが漫画 BANK の見ているページに読み込まれるようにページのソースの中に URL が埋め込まれていて、観測した限りのその URL は、全てが cloudflare がホスティングしているドメインだった( 2021年 7月の調べ )
これが全てではないが、数千のアドレスから集計すると、こちらのドメインに収束した。
0 ssl.appx.buzz
1 ssl.asiax.cloud
2 ssl.stagingy.store
3 ssl.lsw.buzz
4 ssl.advx.cloud
5 ssl.appuru.store
6 ssl.lss.buzz
7 ssl.remon.store
8 ssl.lsq.buzz
9 ssl.lsb.buzz
10 ssl.appsx.cloud
11 ssl.lsh.buzz
12 ssl.raichi.store
13 ssl.lsr.buzz
14 ssl.akaax.com
15 ssl.axax.cloud
16 ssl.lsk.buzz
17 ssl.lsy.buzz
18 ssl.zqap.cloud
19 ssl.skyly.cloud
20 ssl.akax.cloud
21 ssl.zmqx.cloud
22 ssl.lssaq.cloud
23 ssl.lsm.buzz
24 ssl.nexc.store参照: 🥝ページの中から lazy load の画像 URL を抽出する。
画像の著作権情報[#1]と、公開されている cloudflare のドメインの画像ファイルアドレスのリストがあれば、すんなり停止できるのだろうなと考えていた。
[#1]: 本の ISBN 情報なしに、本の題名から書籍データを抽出したいということ。 と、ここにある記事を参照。
[Rf]: 違法と思われるマンガ Thank(仮称)の HTML の構造をよく確認する
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?