
J-STAGE WebAPIで「ポルノ」論文567本のデータを取得する【Python】

・所属研究室で「データサイエンスと社会学」講習会が開かれた。講師は、斉藤史朗先生(電気通信大学特任教授・データサイエンティスト協会事務局長)、瀧川裕貴先生(東北大学准教授)。
・その内容の復習の意味も込めて、記事を書いた次第。
・僕は、瀧川先生が担当の後編にのみ出席。Pythonを初めて触った人も、テクストデータを取得、前処理して、Rでトピックモデル分析までできるようになってみよう、という主旨。
・下の記事のようにPythonは触ったことがあるが、独学の限界を感じていたので参加。
・その演習の一環として、J-STAGE Web APIを用いて論文データを取得した。
・J-STAGEは、国立研究開発法人科学技術振興機構 (JST) が運営する電子ジャーナルプラットフォーム。
・APIとは、Application Programming Interfaceのこと。要するに、J-STAGEが「これ使ってもらえれば、うちのデータ取りやすいですよ」という仕様を公開してくれている。
・J-STAGE Web APIの仕様書はこちら。
・リクエスト用URLにパラメータを入れると、XML形式のレスポンスが返ってくる。
・たとえば、「ポルノ」で全文検索して引っかかる論文をずらっと集めたいとする。URLには日本語を含むことができないので、URLにエンコードする必要がある。「ポルノ」は「%E3%83%9D%E3%83%AB%E3%83%8E」らしい。
・「http://api.jstage.jst.go.jp/searchapi/do?service=3&text=%E3%83%9D%E3%83%AB%E3%83%8E」を開いてみると、なんだかうじゃうじゃしたものが書いてある。仕様書のレスポンスフォーマットを見ながら、どの階層に求める情報が書かれているのか調べる。
・著者名が記載されていない原稿がたまにあるので、条件を指定してやらないとエラーが出る。
・先生や先輩の助言を借りてなんとかやる。
from collections import defaultdict
import pandas as pd
import requests
import xmltodict
res = requests.get("http://api.jstage.jst.go.jp/searchapi/do?service=3&text=%E3%83%9D%E3%83%AB%E3%83%8E")
# ポルノ=%E3%83%9D%E3%83%AB%E3%83%8E
xml_dict = xmltodict.parse(res.content)
data_dict = defaultdict(list) # 空のリストをつくる
for article in xml_dict['feed']['entry']:
if not article['author']['ja']: # 著者名がない場合を想定
data_dict['name'].append(None)
else:
data_dict['name'].append(article['author']['ja']['name'])
data_dict['article_title'].append(article['article_title']['ja'])
data_dict['material_title'].append(article['material_title']['ja'])
data_dict['pubyear'].append(article['pubyear'])
df = pd.DataFrame.from_dict(data_dict)
df.sort_values('pubyear')
df.to_csv("porn_list.csv") # csvファイルに保存しておく・結果
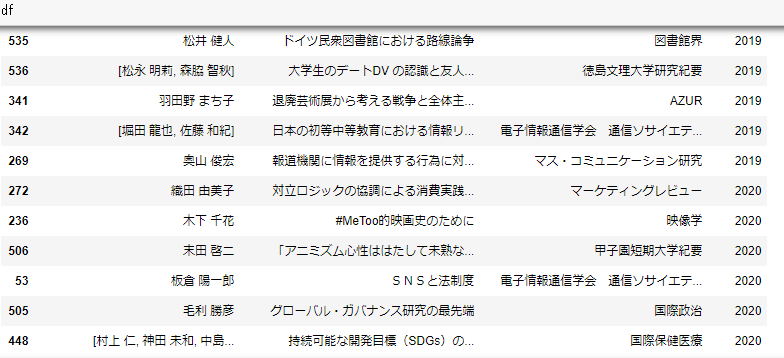
・取れてますね。
・「ポルノ」という対象への接近方法として、社会学的な方法論は、数多あるうちの一つにすぎないということがわかる。
・ちなみに、今回はわざとヒット件数を多くするために「ポルノ」で検索したが、「ポルノグラフィ」で検索すると101件にまで減るかわりに、より焦点の絞られた論文がヒットするように思う。
研究経費(書籍、文房具、機材、映像資料など)のために使わせていただきます。