
【Python】requestsとBeautifulSoupによるWebスクレイピングの基本

はじめに
皆さんは「Webスクレイピング」という言葉を聞いたことがありますか。
ちょうど「Webスクレイピング」を仕事で活用する機会があったので、自分の理解を進める目的も兼ねて記事にしてみました。
本稿では、Webスクレイピングに興味がある方に向けて、PythonのライブラリであるrequestsとBeautifulSoupを用いたWebスクレイピングの概要と具体的な手法を紹介しています。
また、プログラミングに詳しくない方に対しても、Webスクレイピングの雰囲気を伝えられるように心がけて書いています。タイトルの末尾に「*」がある箇所はややプログラミングの知識を要する箇所になっているので、飛ばして読んでみてください。
Webスクレイピングとは何か
Webスクレイピングとは、ウェブページから必要な情報を自動的に取得する技術のことです。
データ解析、機械学習のトレーニングデータ収集、市場調査など、多くの用途で使われています。
実行環境*
本稿では環境構築の手間を鑑み、Google Colabを活用します。
Google ColabではrequestsとBeautifulSoupは既にインストール済みであるため、requestsとBeautifulSoupの導入方法については割愛します。
Webスクレイピングの概要
私たちがWebサイトの情報にアクセスする際に何が行われているのか、非常に簡略的に表すと次の図1のようになります。

大まかに2つの手順がありますね。これから各手順について説明します。
リクエスト
リクエストとは、単純に言えば、ユーザーやプログラムがWebサーバに情報を要求する行為のことです。
このリクエストはHTTP(HyperText Transfer Protocol)というプロトコル(通信を行う際の「合意事項」や「ルール」)を用いて行われています。
リクエストには主に「GET」と「POST」の2種類があります。
GET:サーバーから情報を取得するためのリクエスト。
POST:サーバーに情報を送信するためのリクエスト。
これらのリクエスト方法を使い分けてWebサーバと通信することで、多様な情報をやり取りすることができるのです。
Pythonでのリクエスト*
Pythonでは、requestライブラリを用いることでリクエストを簡単に実行することができます。
例えば、GETリクエストであれば以下のように書くことができます。
import requests
response = requests.get("http://www.example.com")また、key1とkey2という名前のデータをWebサーバに送信するPOSTリクエストであれば以下のように書くことができます。
import requests
payload = {'key1': 'value1', 'key2': 'value2'}
response = requests.post("http://www.example.com/post", data=payload)レスポンス
クライアントからWebサーバへのリクエストの送信が成功すると、Webサーバは必ず何らかの「レスポンス」を返します。
このレスポンスもHTTPプロトコルに従って構築されており、Webサイトの情報や「ステータスコード」と呼ばれる三桁の数字などが含まれています。
このステータスコードには大まかに次の3種類があり、通信の成功/不成功を伝えるために存在しています。
2xx:成功
4xx:クライアントエラー(リクエストに問題あり)
5xx:サーバーエラー(サーバー側に問題あり)
レスポンスの情報を適切に解釈することで、正しくWebページを表示できるほか、サーバーから返されたデータが正確であるか、追加の処理が必要かなども判断できるのです。
Pythonでのレスポンス処理*
Pythonではリクエストと同様に、requestsを用いることでレスポンスの内容を確認することができます。
例えば、ステータスコードを確認する場合は以下のように書くことができます。
import requests
response = requests.get("http://www.example.com")
print(response.status_code)また、WebページのHTMLコードなどが含まれるレスポンスボディを確認する場合は以下のように書くことができます。
import requests
response = requests.get("http://www.example.com")
print(response.text)スクレイピング
先ほど、スクレイピングについて「ウェブページから必要な情報を自動的に取得する技術のこと」と説明しました。
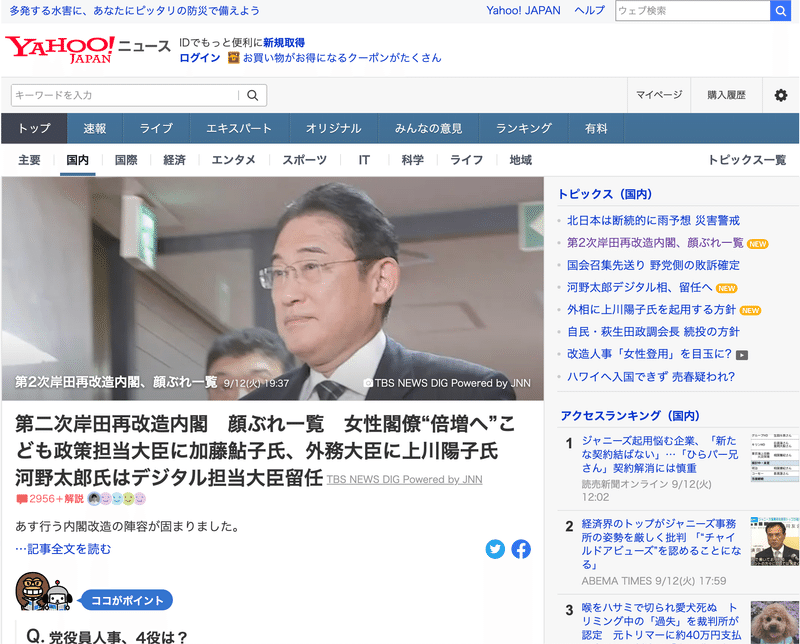
例えば、上図2のYahooニュースの一記事からタイトルを抽出したい、本文を抽出したい、もしくは写真を、投稿日時を抽出したい、といったニーズに対応する技術がスクレイピングです。
しかし、このようなWebページは、実は人間が読みやすい形で表示されています。

コンピュータの視点から見たWebページは図3のように非常に見づらいものとなります。
<!DOCTYPE html><html lang="ja"><head><title>第2次岸田再改造内閣、顔ぶれ一覧 - Yahoo!ニュース</title>しかし、よく見るとニュースのタイトルなど、必要な情報がこの中にも含まれていることが分かりますね。
スクレイピングとは、プログラムを使ってこのようなソースコードから必要な情報を効率的に抽出する手法とも言えます。
Pythonでのスクレイピング*
PythonでWebスクレイピングを行う場合、先ほど紹介したrequestsライブラリでWebページの情報を取得し、その後BeautifulSoupライブラリでHTMLの解析を行うことになります。
BeautifulSoupはHTMLやXMLの解析に特化したPythonのライブラリです。requestsで取得したレスポンスデータを解析して、目的の情報を抽出することができます。
以下のコードは、指定したURLからWebページのタイトルを抽出する簡単な例です。各行にコメントで説明を付けているので参考にしてみてください。
# bs4(Beautiful Soup 4)というライブラリからBeautifulSoupというモジュール(クラス)をインポート
from bs4 import BeautifulSoup
# requestsライブラリをインポート
import requests
# URLにアクセスして、そのレスポンスをresponseという変数に保存する
response = requests.get("http://www.example.com")
# レスポンスボディをBeautifulSoupで解析し、その結果をsoupという変数に保存する
soup = BeautifulSoup(response.text, 'html.parser')
# 解析したHTMLの中から<title>タグのテキスト内容を見つけて、titleという変数に保存する。
title = soup.find('title').text
# 抽出したWebページのタイトルを出力する
print("Webページのタイトル:", title)ベストプラクティスと注意点
ここまで、Webスクレイピングの簡単な流れと実装について説明してきました。
実際にWebスクレイピングを安全に行うためには、更に以下の点に留意しておく必要があります。
ロボット排除規約、利用規約の確認
スクレイピングを行う前に、ターゲットとするWebサイトのロボット排除規約(通常はrobots.txtというファイルで公開されています)や利用規約を確認しましょう。
これらの文書には、サイトがスクレイピングをどの程度許可しているのか、具体的なルールが記されています。
頻繁なアクセスを避ける
Webサイトに短時間で多数のリクエストを送ると、サーバーに負荷をかけることになり、その結果としてIPアドレスがブロックされる可能性もあります。
リクエストの頻度を適切に制限し、必要な場合は適切な間隔を空けるようにしましょう。
まとめ
本稿では、Webスクレイピングの概略と、PythonでrequestsとBeautifulSoupを用いた具体的なスクレイピングの方法について説明しました。
より実践的な内容についても後日改めて記事を書きたいと思っているのでよろしくお願いします!
参考資料
お読みいただきありがとうございます!
ご意見・ご質問などございましたらお気軽にコメント欄に投稿してください。いただいたコメントは全て拝見し真剣に回答させていただきます。
この記事が気に入ったらサポートをしてみませんか?