
生成AI時代を生き抜きたい!データアナリストのLLM活用術

こんにちは、Gotaです。普段はデータアナリストとしてリテール業界の意思決定支援の分析を中心に、データ利活用支援、BI構築、ツール作成等の業務を行っています。
業務を効率的に行うには生成AIの活用が欠かせなくなっており、chatGPT(最近はもっぱらGPT-4oモデル)の制限がかかるとClaude 3 Opusに、Claude 3の制限がかかるとGeminiへとツールをハシゴしながら仕事しています。
本記事では、データアナリストの普段の生成AIの活用方法、特にchatGPTやClaude等の対話型AIサービスの活用方法を、データ分析プロセス別に具体的にご紹介します!(一部プロンプトも公開してます)
データ系職種では特に、LLM(大規模言語モデル)のビジネス利用における個人情報や企業秘密の漏洩リスクはありますが、部分的に使うだけでもかなり楽になりますので、参考になれば嬉しいです。
参考になれば是非「いいね」していただけると喜びます!
問題の定義:目的設定

データ分析の成功は問題の定義段階以前で全て決まるといっても過言ではありません。このステップには全力を注いでいます(他の段階がテキトウなわけではないよ)。
この段階の自動化ができれば全自動AIデータアナリストが実現出来そうなのですが、どうしても要件に過学習したような分析ストーリーの生成や網羅的な問題定義となってしまい、AIエージェント化に苦労しているところです。解決策を模索中ですが、それでもLLMの使い所は多いです!
ステークホルダーのリテラシーや意図・背景理解
意思決定支援のデータ分析においてまず必要なのは、分析プロジェクトの全体像把握です。特に意思決定のキーパーソンとステークホルダーの全体像把握と、利害関係を解き明かすことには時間をかけています。極論ですが、意思決定のキーパーソンと仲良くなればデータ分析せずとも意思決定してもらえます。
そのため、 その意図・背景理解に生成AIを使って観点のヌケモレがないかをチェックしてもらっています。
問題定義の分解&要素のヌケモレチェック
問題定義を自分自身の頭だけで行うとヌケモレが発生する可能性が高いです。要素のヌケモレをなくす目的でLLMを使っています。

データ理解・収集
データ品質評価
新しいデータセットやテーブルを利用する際、データ品質評価やデータ理解に時間をかけますが、テーブルにより要件が異なるため思った以上に時間がかかることも多いです。
そこで最近自律型データ品質評価エージェントを作りましたので、後日記事化します。生成AIを活用していくにあたって、切実にデータ品質評価の自動化、データカタログ導入やメタデータ管理を進めていきたいところです。
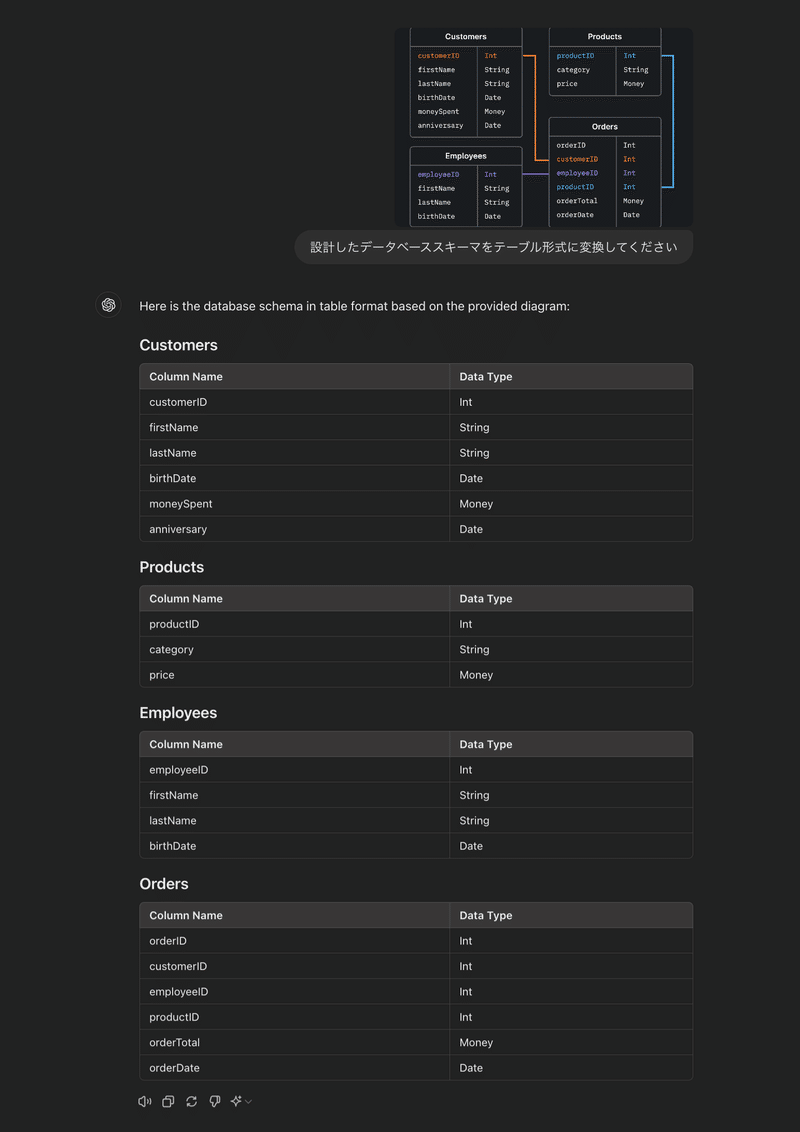
データスキーマの設計&文書化
データマート作成をするとき、データスキーマを作成する必要があります。
LLMを使えば、要件を満たすデータスキーマ設計の下書きを作ることもすぐ出来ます!
またGPT-4oやGemini 1.5 Proでは、設計書のスキーマをスクショで撮影し、それをドキュメントに適した形式に変換することも簡単に出来ます!
データ生成
不足している学習データの生成等に使いたいのですが、如何せんあんまり分かってないので、データ拡張含めて学びたいトピックです。
商品レビューのデータ生成についての論文読んでみましたが、機械と人間が作成した文章には明確な違いがあるとのこと。
データ分析
データ分析実行段階では、ほとんど全ての業務で生成AIを使っています!本当に実務が楽になりました!
その分「ディレクション」「ビジネス要件の全体像整理」「目的に沿った評価指標の設定」「End-to-Endのシステム実装」の重要性が相対的に上がっているなと感じています。
分析を行う詳細な要件定義作成
データ分析は途中走りながら修正をかけていくことも多いのですが、ビジネス要件を分析要件に落とし込むことが必要です。
売上の定義一つとっても、「税抜」vs「税込」、「値引き後」vs「値引き前」、「インフレ調整前」vs「インフレ調整後」と様々な定義が存在します。定義が明確であれば困らないのですが、基本的に定義がフワフワしていることのほうが多いです。
問題定義段階で定義した内容をより詳細な指標、集計単位に落とし込む際に必要となるのが分析要件定義となります。
GPT-4oでのプロンプト例:
あなたのタスクは、シニアデータアナリストとして分析設計を行うことです。
## 分析課題
英語学習アプリの売上が下がっています。
その問題の一つとして「顧客維持率が下がっているのでは」という仮説が上がりました。
## 検証したい問い
- 顧客維持率が実際に下がっているかどうか
- 主要な解約ポイントがどこか
## 制約
- 検証したい問いごとに、具体的な分析設計を行う
- 分析設計は作業者がすぐ実行できるように作成する
## 分析設計
SQL生成
データアナリストの集計業務にはSQLを主に使っています。
SQL生成では使用するテーブルのスキーマ情報を加味する必要がありますが、GPT-4oが出てからスキーマを雑にスクショして、それを読ませてクエリを書いてもらってます。
とはいえデータ分析用、特にアドホック分析のSQLはとにかく複数テーブルのJOINが発生し長くなりがちで、思った程の精度が出ていません。が、ゼロからクエリを作らなくて良いだけで本当に気持ち的にも時間的にも楽になりました!
どのテーブルを使うかを自身で選ばなければならないや複雑なクエリの精度が高くないなど課題はありますが、Text-to-SQLやSQL実行エージェントは個人的には葬送のフリーレンと同じくらいホットな話題です。今後記事にまとめます。
Claudeでのシステムプロンプト例:
以下の自然言語のリクエストを有効なSQLクエリに変換してください。次のテーブルとカラムを持つデータベースが存在すると仮定します。
<table>
Customers:
- customer_id (INT, PRIMARY KEY)
- first_name (VARCHAR)
- last_name (VARCHAR)
- email (VARCHAR)
- phone (VARCHAR)
- address (VARCHAR)
- city (VARCHAR)
- state (VARCHAR)
- zip_code (VARCHAR)
</table>
<table>
Products:
- product_id (INT, PRIMARY KEY)
- product_name (VARCHAR)
- description (TEXT)
- category (VARCHAR)
- price (DECIMAL)
- stock_quantity (INT)
</table>
<table>
Orders:
- order_id (INT, PRIMARY KEY)
- customer_id (INT, FOREIGN KEY REFERENCES Customers)
- order_date (DATE)
- total_amount (DECIMAL)
- status (VARCHAR)
</table>
<table>
Order_Items:
- order_item_id (INT, PRIMARY KEY)
- order_id (INT, FOREIGN KEY REFERENCES Orders)
- product_id (INT, FOREIGN KEY REFERENCES Products)
- quantity (INT)
- price (DECIMAL)
</table>
自然言語のリクエストに基づいてデータを取得するSQLクエリを提供してください。
SQLへのコメント追加
アドホック分析用に作成したSQLは長くなりがちです。クエリの中で何が行われたかを将来の自分(もしくは同僚)に伝わりやすくかつ可読性を高めるため、各CTEにコメントを記載しています。自分で日本語を書くのが面倒くさいため、LLMでコメントを入れてもらってます。

自然言語処理
精度はともかく、生成AIを使うとデータアナリストでも感情分析やエンティティ抽出があっという間に出来ます。それもABSA (Aspect-Based Sentiment Analysis)等の複雑なエンティティ抽出も出来るため、スピードを求められるビジネスシーンかつざっくりと意思決定をしたいときには役立ちます。
実務では、アンケート調査の自由回答欄のタグ付けや感情分析の定量化をGPT-3.5-turbo APIを用いて行い、BI化するプロジェクトを行いましたが、ビジネス側からかなり好評でした!
コード生成 - Python
データアナリストではありますが、データ可視化や分析ツールの作成と自動化、意思決定のための統計的モデルやXAI(説明可能なAI)機械学習モデルの作成、因果推論等でPythonコードを書くことも多々あります。(というかほとんど毎日書いてる気がする)
ローカルで作業するときには、Cursorをエディタとして愛用しています!
コード生成 - データ可視化
chatGPTが登場するまで、スライドに利用するようなデータ可視化を作成するために、公式リファレンスやソースコードとにらめっこしながら微調整をかけていましたが、chatGPTが出てからはほぼ自然言語だけでX軸やY軸のラベルの調整や、グラフ領域内の細かい調整のコード生成を全て丸投げできるようになりました!まじで神!

エラーハンドリング
Stack Overflowを使う機会が減りました。
プロンプト例:
あなたのタスクは、提供されたPythonコードスニペットを分析し、存在するバグやエラーを特定し、これらの問題を解決するコードの修正版を提供することです。
元のコードで見つかった問題点と、修正によってそれらがどのように解決されたかを説明してください。
修正後のコードは、機能的で効率的であり、Pythonプログラミングのベストプラクティスに準拠している必要があります。コードレビュー SQL/Python
レビューで他人のコードを読むのはなかなか骨が折れる作業です。そのため、コードレビューのコード理解のために生成AIを活用しています。
いずれはレビュー工数を減らせるように効率化できればなと画策中です。
BIのUIデザイン
最近少し使ってますが、もう少し使い込みたい
結果の評価と解釈
上記で作成したデータ可視化の画像をマルチモーダル生成AIにインプットし、可視化の結果と解釈の言語化をやってもらっています。特に複雑な画像になると、自分で文章書くのも面倒くさいのでまずは言語化してもらったあとに、解釈を考えるようになりました。文字を書く労力を減らせるだけでこんなにも楽になるのかと…
これはGemini APIを通して行うことが多いですが、chatGPTやClaude上でも出来ます。(GPT-4oは精度が高くて驚きます)

提言と報告、意思決定…
スライド生成サービスとかありますが、全然使ってません。
Copilotをパワーポイントで使った感じですと、現段階だと特定のテンプレートの利用やグラフ作成がまだまだ難しく実用には足らないかなと感じていますが、時間の問題でしょう!
個人的にはパワポを作る必要がない世界線が理想です。
データアナリストとして重要な意思決定を変えるスキルは、人が意思決定する以上生成AIの出番はまだないかも
プレゼンでの顧客の質問を予測する
プレゼンの事前準備では大活躍してくれます。プレゼンの疑問点や質問を事前予測することができれば、事前準備も楽にできます!
その他
分析に限らないドキュメントのドラフト作成
ドキュメントのドラフト作成はLLMに頼りきりです。もう自分で文章を書けないかも…
最近だと、分析研修を実施する資料構成の叩きを作ってもらったりと何でもかんでもドラフト作成に使っています。
メール作成・謝罪文作成
謝罪文は生成AIに書いてもらうのが一番!
まとめ
データ分析プロセスの生成AI活用方法を備忘録的に紹介しましたが、書けば書くほどデータアナリストの将来的な役割は大きく変わる+なくなるなと実感してます。いち早くデータ分析の全工程を丸っと自動化して、静かな失業状態を実現したいものです!(あと、最近データアナリストっぽい業務をしていない気がするのは気のせいなのか….)
参考になれば是非「いいね」と実際に活用してみたフィードバックくれると嬉しいです!他にこういう使い方をしているよなどあれば、是非是非教えて下さい!
これからはGPTsだけでなく、データ分析やRAG、AIエージェントの記事も積極的に書いていきますのでいいねとフォローお願いします!
この記事が気に入ったらサポートをしてみませんか?