
グロービスにおけるデータ基盤のアーキテクチャについて

はじめに
はじめまして!!
株式会社グロービスのデジタル・プラットフォーム部門、データサイエンスチーム、データエンジニアリングユニットにてソフトウェアエンジニアをしております、爲岡 (ためおか) と申します。 (肩書きが長くてすみません。)
グロービスには当初、機械学習エンジニアとして入社しましたが、現在は機械学習や分析に利用するためのデータ基盤の開発・運用をメインで担当しています。
この記事では、グロービスのデータエンジニアリングユニットが運用しているデータ基盤のアーキテクチャについてご紹介できればと思います。
グロービスについて
突然ですが、皆様はグロービスに対してどのようなイメージをお持ちですか?
特にテクノロジーの領域で働く方々にとって、そもそもグロービスという企業を知らない、という方が大半なのではないか、と思っています。
また、もしご存じだとしても、経営大学院や研修事業など、テクノロジーとは関連の無い領域で事業を展開している企業、というイメージの方も多いかと思います。
しかし、実はグロービスは、日本を代表する Ed-Tech 企業を目指しており、テクノロジーを利用した様々なサービスを提供しています。
ビジネスの原理原則を体系的に学べる動画サービスです。2021年11月時点で有効会員数20万人を突破しました。
「グロービス学び放題」の海外版になります。
グロービスのオウンドメディアで、ビジネストレンドやテクノロジーに関する記事を掲載しています。
ビジネスパーソンの能力を客観的に測定するテストをサービスとして提供しています。
この他にも、eラーニングでビジネスについて学べる eMBA2.0 や、学習管理システム (Learning Management System) を提供する GLOPLA LMS など、toB、toC 向けに多くの Web サービスを提供しておりますので、是非、エンジニアやデザイナーの方々に興味を持っていただけたら幸いです。
データ基盤のアーキテクチャ
早速ですが、我々データエンジニアリングユニットが開発・運用している、データ基盤についてご紹介します。
データ基盤のアーキテクチャの概要を表した図は下記になります。
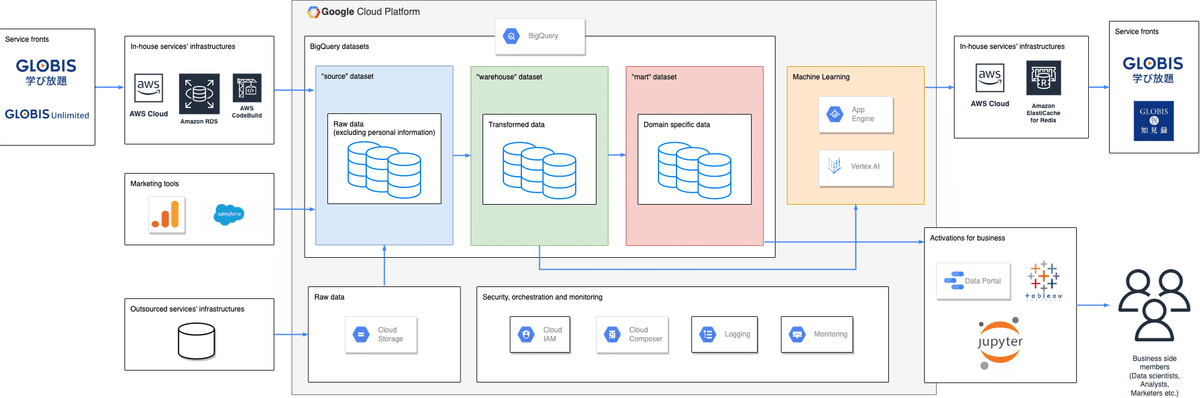
概要
グロービスのデータ基盤では、パブリッククラウドとしては Google Cloud Platform (以降 GCP と略します) を採用しており、BigQuery を利用した ELT (not ETL) を行っています。
具体的には、まずサービスからデータを抽出 (Extract) し、BigQuery にデータを取り込み (Load)、その後加工 (Transform)、最後に必要があれば用途に合わせて整形 (Specify) する形をとっています。
書籍『Google Cloudではじめるデータエンジニアリング入門』によると、ELT の方式は、下記のように BigQuery を利用する際には推奨されています。
Google Cloud Next '19 でのセッション「Data Warehousing With BigQuery: Best Practices」で、 Google CloudのBigQueryをDWHとして使用する際は、ETLではなくELTをできる限り採用することが推奨されています。 その理由として、以下が挙げられています。
・BigQueryはスケーラブルなDWHであり、大規模なデータの変換処理を実施できる
・SQLを書くだけでデータの変換処理を実施でき、別途、ETL処理を開発、運用する必要がなく、データ処理のパイプラインをシンプルにできる
・ETLを実行するサービス(DataprocやDataflow)では、クラスタやジョブの立ち上げのオーバーヘッドが発生するのに対して、BigQueryでジョブを実行すると、オーバーヘッドが発生せず、すぐに大規模並列処理として実行できる
これらの工程に合わせて、BigQuery 内のデータセットを、 source、 warehouse 、 mart という名前で分けています。この区分に関しては データ基盤の3分類と進化的データモデリング #DPCT / 20190213 を参考にさせていただいておりますので、そちらをご覧いただければと思います。
また、現状データ基盤で実現しているのは基本的にはバッチ処理のみで、機械学習で利用する一部のデータ以外は日次、もしくは月次で ELT を実施しています。
これ以降は、各処理の中身について詳細に説明します。
Extract
抽出対象のデータソースとして、大きく分けて3つのコンポーネントがあります。
In-house services
グロービス社内で開発・運用しているサービス群です。
グロービス学び放題、GLOBIS Unlimited などが当てはまります。
内製サービスはすべて AWS 上で開発・運用しています。
サービスには AWS、データ基盤には GCP と、利用するパブリッククラウドを分けている理由は、端的に言えば、データ基盤に BigQuery を利用したかったためになります。 データ基盤の構築当初は Amazon Redshift Serverless がリリースされておらず、インフラレイヤの管理コストや、その利用しやすさの観点から BigQuery を選択するに至りました。
Marketing tools
各サービスにおけるユーザの行動ログや顧客管理を行うためのマーケティングツール群です。
Google Analytics や Salesforce などが当てはまります。
Outsourced services
外部ベンダに開発・運用を委託しているサービス群です。
GMAP などが当てはまります。
データの連携方法としては、各サービスから Google Cloud Storage にデータを push してもらい、それを Google Cloud Composer を利用してデータ基盤に pull する運用としています。
Load
各種サービスやマーケティングツールから得られたデータから、個人情報を匿名化した上で BigQuery の source データセットに格納しています。
データコネクタが利用可能なサービスに関してはなるべく利用するスタンスです。例えば、Google Analytics は version 4 から BigQuery へのコネクタが用意され、データ連携が非常に容易になりました。
コネクタが用意されていない各種サービスに関しては、Cloud Composer を利用してジョブ管理を行い、Pull 型でデータ連携を実施しています。
ただし、内製サービスに関しては、歴史的経緯から AWS CodeBuild を利用して Push 型のデータ連携を実施しています。権限や利用ツールの違いなど、管理コストがかかるので、いずれはすべて Cloud Composer を利用した Pull 型に移行していきたいと考えています。
Transform
データソースから得られたテーブルを利用して機械学習や分析に利用しやすい形に整えた上で、 warehouse データセットに格納しています。主に、個人情報を含まないユーザ情報の詳細や契約の詳細、行動ログなどを整理して格納しています。
Specify
主にダッシュボードなど、ビジネスにおいて特定の用途で利用するデータを、複雑なクエリを書かなくても利用できるように整形した上で mart データセットに格納しています。
データ活用の方向性
warehouse データセットや mart データセットに格納したデータを、主にプロダクトとビジネスの2つの方向性で活用しています。
プロダクト
機械学習によるレコメンドを、グロービス学び放題やグロービス知見録などのサービスの機能として提供するために、データを利用しています。
現時点では学習・推論のために Google App Engine を利用していますが、Vertex AI を利用した serverless な環境に移行しつつあります。
ビジネス
ビジネス分析や各種 KPI のダッシュボードのためにデータを利用しています。
ツールとしては Jupyter Notebook や Google Data Portal, Tableau などを利用しています。
今後取り組みたいこと
このように、グロービスにおけるデータ活用は徐々に進んできてはいるものの、まだまだ解決すべき課題が残されています。その中で、今後主に取り組んでいきたい領域は下記の3つです。
データマネジメント
データ活用成熟度 (『実践的データ基盤への処方箋』 3-1 節より引用) を高める活動の一環として、下記を実現したいと考えています。
データアーキテクチャの可視化、課題抽出
社内データ統合の推進
メタデータ管理
Infrastructure as Code
データ基盤の様々な設定を Terraform を利用してコード化することによって、下記を実現したいと考えています。
権限管理の効率化と、それによるセキュリティの向上
データ基盤の検証環境の実現
MLOps
MLモデルの継続的な改善を効率良く行い、ビジネス課題に対する施策の実施〜評価のサイクルを素早く回していけるようにするため、下記を実現したいと考えています。
Vertex AI 上でのモデル学習および推論実行環境構築の自動化による、モデル開発の速度の向上
Feature Storeによるデータと特徴量の管理の自動化による、モデルのパフォーマンスモニタリングやモデル改良時の特徴量生成プロセスの効率化
おわりに
最後に、グロービスの事業について、より詳細なご説明をさせていただければと思います。
グロービスは国内のみならず、海外でも事業を展開している企業です。
上海、シンガポール、バンコクに加え、2021年10月にはアメリカのサンフランシスコにも支社を設立し、様々な事業展開を進めています。それらの事業の中には、海外向けの動画サービスである GLOBIS Unlimited も含まれており、テクノロジーを利用して世界中に価値を提供することを目指しています。
組織としても、現在はエンジニア、デザイナーを含む開発組織の人数は100名を超え、それに伴いテクノロジー分野で様々な取り組みを実施しています。 (この note もその取り組みの1つです。)
グロービスに根付いている「自由と自己責任」の組織文化のもと、テクノロジー領域の人材がのびのびと働ける環境を提供しています。
Wantedly にて、働き方を含むグロービスの会社情報を掲載しております。
開発組織は約2年で1人→40人に たった1人からはじまった、グロービスのエンジニア組織の裏側
VPoE の末永さんの記事になります。グロービスの組織文化について深く言及されています。
GLOBIS Advent Calendar 2021 - Qiita
2017 年より、Qiita Advent Calendar に毎年参加しています。
現在も運用している機械学習によるレコメンドのサービス導入の記事になります。
データサイエンスチームのメンバーである菅沼さんが書いた記事になります。
また、個々のチームにおいても、それぞれのミッションや行動指針を重要視しています。
データサイエンスチームの行動方針やこれまでの取り組み、メンバーについては、是非下記の資料をご覧ください。
そんな我々データサイエンスチームでは、一緒に働く仲間を絶賛募集中です!!
この記事を読んで、グロービスで働くことにご興味をお持ちになった方がいらっしゃいましたら、是非お気軽に @zettaittenani までご連絡ください!!
お読みいただきまして、誠にありがとうございました!!
参考資料
参考書籍
この記事が気に入ったらサポートをしてみませんか?