
自動運転や先進運転支援で標準技術になりつつあるBEVパーセプションの解説

はじめまして。ギリアで機械学習エンジニアをしている王と申します。
自動運転などで、最近はBEVパーセプションという技術が主流になりつつあります。BEVパーセプションは、従来の画像空間パーセプションと比較してマルチモーダルデータの利活用や後続タスクの組み込みやすさなどの点で優位性があり、オープンデータセットでSOTA(State-of-the-Art)を次々と達成しています。
今回はこのBEVパーセプション技術を解説したいと思います。
BEVパーセプションとは
BEV
BEVとは、鳥瞰図(Bird’s Eye View)のことを指します。鳥瞰図のメリットは物体のスケールがほぼ一定であることです。カメラの透視図(Perspective View)の場合は、奥行きがあり、近くにいる物体が大きく、遠くにいる物体が小さく映るので、物体のスケールの変化が激しくなります。
パーセプション
パーセプション(Perception)とは、認識のことを指します。我々の脳の外部情報に対する反応でもあります。
BEVパーセプション
以上より、BEV空間においての認識ということで、主に画像認識の文脈におけるものです。通常の透視図空間においての認識では、例えば、同じ人を認識する場合は遠くにいる人も近くにいる人も同じように認識したいので、受容野を意識したマルチスケールの特徴変換が求められます。一方、BEV空間上の認識では、同じ人であればスケールがほぼ同じなので、認識の難易度が下がります。

FIERY: Future Instance Prediction in Bird’s-Eye View from Surround Monocular Cameras から抜粋 *1
BEVパーセプションのタスクは通常のCV(Computer Vision)分野で実施されてきた物体検出、セグメンテーションなど全部が対象です。
BEVパーセプションの入力データとして主に利用されているのは、カメラ、ミリ波レーダー、LiDARなどのセンサデータがあります。

BEVパーセプションのデータ
画像データ
画像データはカメラで撮影し、3次元の世界を2次元の画像平面に投影したものです。画像の最小単位はピクセルで通常RGBの値が格納されていますが、その他の形式もあります。画像データのメリットは、テクスチャがリッチで収集コストが低いといった点です。画像データに対して様々なCVタスクが実施されてきて、各タスクにおいて性能の良いディープラーニングモデルが多数存在します。

LiDARデータ
LiDARデータは基本、点群という形式となっています。点群は点の集合のことで、最小単位が3次元の点です。点群データは順序がなく、スパース(sparse)である3D表現です。順序がないというのは、点群は画像のように整列されておらず、あくまで点の集合だということです。スパースとは、3D空間上、点のない空白のエリアが大半のためです。

ミリ波レーダーデータ
ミリ波レーダーデータは、通常、センサとの相対角度、相対距離、視線速度 [引用*5]のセットとなります。LiDARと比べて、速度をダイレクトに取得できるのが特徴となります。
データの収集方法
NuScenes [引用*6]というデータセットは、下図のような計測車両を採用して、走行データを集めました。計測車両に搭載されたセンサは、カメラ6基、ミリ波レーダー5基、LiDAR1基とIMUとなります。IMUは慣性計測装置のことで、加速度や回転角度を計測できます。
後ほど説明しますが、BEVパーセプションのモデルは複数のカメラ画像データ、LiDAR、ミリ波レーダーデータを融合して利用します。融合する時はデータを同じ座標系に変換しないといけません。そのため、カメラの内部・外部パラメータ、LiDARとミリ波レーダーの外部パラメータなどが必要になります。キャリブレーションに関しては様々なツールや手法があります。例えば、openCalib [引用*7]というツールを使用すれば各種センサのキャリブレーションが可能です。

BEVモデルの特徴
センサフュージョン
車載センサは、通常複数種類・複数基の設置となり、これらのセンサはそれぞれ長所と短所があって、情報を補い合うという観点でデータの融合が必要です。このデータ融合をセンサフュージョン、またはMulti-sensor information fusion (MSIF)と呼びます。
BEVパーセプションが流行る前のセンサフュージョンは、主にEarly Fusion (Data Level Fusio )とLate Fusion (Object Level Fusion)に分かれます。Early Fusionは、センサの内部・外部パラメータを使ってキャリブレーションを行い、同じ空間・座標系に変換する手法です。例えば、LiDAR点群をカメラ視点に変換して深度図を作成する方法は、Early Fusionに該当します。他には、カメラで撮影した画像をSemantic Segmentation [引用*8]で処理し、セグメンテーション結果をLiDAR点群に投影する方法もあります。
Early Fusionの問題点は、キャリブレーションの精度に強く依存することと、情報のロスが発生することです。

Late Fusionは、各センサデータを別々に処理し、タスクの予測結果を融合する手法です。例として、画像から予測した2D領域とLiDAR点群からの物体検出結果を重ね合わせて、最終的な予測結果を出す方法があります。
Late Fusionは、 マルチモーダルなセンサデータを利用して検出を行うのではなく、 各々が独自に結論を出して後処理的に融合するため、どのセンサの結果を信用すれば良いかというジレンマがあり、検出結果が不安定です。

BEVパーセプションモデルが主に採用しているのは、Deep Fusion (Feature Level Fusion)というもので、特徴レベルの融合手法となります。Deep Fusionにおいて、センサデータはそれぞれ別々のパイプラインで処理し、特徴を生成し、この特徴を融合します。カメラ画像の場合はCNNなどのモデルで、LiDARデータはPointPillars [引用*10]やVoxelNet [引用*11]などのモデルで特徴を生成できます。
Deep Fusionは特徴レベルの融合で、どの特徴を重要視するかなどは学習されるため、データ量が十分にある場合はEarly FusionとLate Fusionよりも高い精度が実現できます。欠点としては、モデル内部の処理が重くなり計算時間が長くなることです。

BEVモデルがセンサフュージョンにより精度を改善できることは、NuScenesが公開しているLeaderboardからも見てとれます。mAP指標で降順に並べてみると、上位にくるモデルはすべてセンサフュージョンを採用したものとなります。

BEVモデルの構造
近年のBEVモデルはVision-Centric、つまりカメラを中心とする設計を採用しています。カメラは安価で入手しやすいですし、撮影した画像データもテクスチャがリッチなため、非常に優秀なセンサです。しかし、カメラは空間を平面に投影してしまうため、3D空間のモデリングには不向きです。この問題点を解決するために、撮影エリアが一部重なるよう複数のカメラを設置するサラウンドビューや、3Dモデリングに向いているLiDARセンサなどの追加などの方法が必要です。
まず、BEVモデルはどうやって画像データを処理するかを見てみましょう。
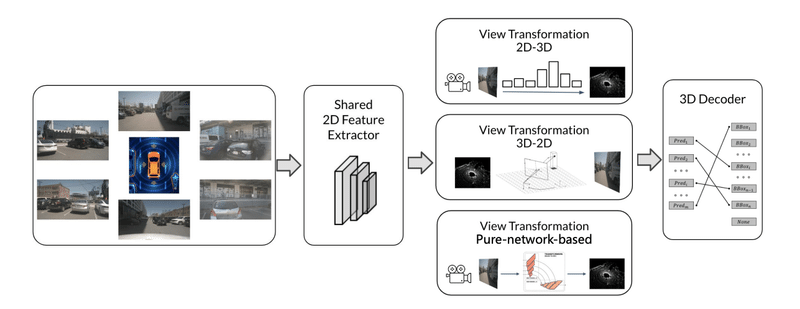
左側は、入力データで6基のカメラから撮った画像となります。Shared 2D Feature Extractorは、事前学習済みのCNNなどのbackboneモデルで、6枚の画像に対して同じモデルを適用するのでSharedとなります。backboneモデルで画像を特徴マップに変換し、その次のステップはView Transformationというものです。View Transformationは視点変換で、2Dの画像特徴と3D空間表現との相互変換が必要です。変換後の特徴は次の3D Decoderに渡され、最終的に検出結果が出力されます。
Vision-CentricのBEVモデルの核心となる部分は、View Transformationです。この部分のモデリング手法の違いでモデルの精度が大きく変わります。
Backbone
Backboneに関して、画像の場合は事前学習済みモデルがよく採用されています。代表的なものとして、ResNet [引用*14]やSwin Transformer [引用*15]などがあります。これらの学習済みモデルの最終層の特徴マップを使ってもいいですが、マルチスケールの特徴をFPN [引用*16]的な構造と組み合わせて使用するとより精度が向上するでしょう。
点群データの場合は、PointNet [引用*17]、PointPillars [引用*10]やVoxelNet [引用*11]などのモデルに近い構造がBackboneとして採用されます。
2D→3D変換
下図は透視投影によるカメラモデルを表現したものです。カメラは3D空間を2Dの画像平面に落とし込んだ3D→2D変換です。図から分かるように、CXというピンク色の線分上の全ての点は、画像平面上のxに変換されます。深度が分からない限り、逆変換の2D→3Dは1対1の関係性ではないため、数学的には不可能です。

数学的には不可能ですが、人間は片目でものを観察するときは正確でなくてもある程度距離が分かります。それは、影の向きや照明など画像上に様々なヒントがあるからです。実際、深層学習において単眼深度推定は重要な研究分野の1つです。
複数視点の画像があり、撮影範囲が一部重なった場合は、より正確に深度推定ができるはずです。
次に、BEVモデルとして非常に有名なLSSモデル [引用*19]の変換モジュールを見ていきます。

LSSの変換モジュールは、各ピクセルに対して4〜45メートルの1メートル刻みの深度の確率分布をモデリングします。決定論的な難しい学習ではなく確率分布のため、緩い学習ができ、推定の難しい箇所を引きずるようなこともあまりありません。
3D→2D変換
3D→2D変換は、3D変換後の特徴量を2DのBEV空間に変換するための処理です。
ここでは、BEVFormer [引用*20]モデルの構造を見てみましょう。

BEVFormerモデルの変換モジュールはTransformer [引用*21]モデルで、具体的にはTransformer Decoderを採用しています。BEVFormerは、物体検出でお馴染みのobject queryベクトルを利用してBEV空間を構築します。Object Queryに関してはDETR [引用*22]モデルが提唱した仕組みで、近年のTransformer系Visionモデルでよく採用されます。
BEVFormerの変換モジュールにはTemporal Self-AttentionとSpatial Cross-Attentionの2つの機構が入っています。Temporal Self-Attentionは、過去フレームから生成されたBEV特徴と現時刻のBEV Queryを結合して、現時刻のBEV QueryだけをQueryとしたSelf-Attentionです。ここでは、Deformable Attention [引用*23]が採用されています。Spatial Cross-Attentionは、いわゆる2D→3D変換と3D→2D変換をまとめた処理で、暗黙的に2Dの画像特徴を3D空間に変換し、更に縦方向を潰して2DのBEV空間に落とし込んでいます。
センサフュージョン
次に、画像とLiDARのセンサフュージョンの仕組みを見ていきたいと思います。View Transformationにより画像はBEV空間の特徴に変換される処理を説明しましたが、LiDAR点群の場合は元々3D表現のため、センサの外部パラメータを使用すれば点群特徴を簡単にBEV視点に変換できます。同じBEV空間の画像特徴と点群特徴の融合として、1番簡単なのはChannel次元の結合になります。ここでは、BEVFusionで採用されているSqueeze-and-Excitation [引用*24]ベースのAttentionによる融合を解説していきます。


BEVFusionでは、画像と点群からそれぞれBEV特徴を生成し、Dynamic Fusion Moduleという機構で特徴の融合を実施しています。Dynamic Fusion ModuleはSqueeze-and-Excitation Moduleから発想を得て、特徴をAttentionによる取捨選択を行います。まず、画像特徴の次元は(X, Y, C1)で、X、YはBEV空間の縦と横の長さです。同じく、点群特徴の次元は(X, Y, C2)となるでしょう。C1、C2はそれぞれ画像特徴と点群特徴の特徴次元です。Dynamic Fusion Moduleでは、まず画像特徴と点群特徴をC次元方向で結合し、Conv 3x3を行います。次に、処理が分岐して、上のルートはGlobal Avg Pool、Conv 1x1、Sigmoidを順に適用し、C次元方向で0〜1範囲の重要度を表すゲートを生成します。下のルートは素通りで、最後にゲートとアダマール積 [引用*26]を計算し出力します。Dynamic Fusion Moduleにより、特徴を取捨選択して融合することができます。
最後に
今回は、自動運転や先進運転支援で定番になりつつあるBEVパーセプションという技術の基礎を解説しました。Teslaをはじめ様々な完成車メーカーやサプライヤーは、すでにBEVパーセプション技術を製品に組み込み、大幅に性能が向上した自動運転や先進運転支援機能を実現しています。しかし、全ての課題が解決されたわけではありません。ロングテール問題 [引用*27]、悪天候、暗所による精度低下問題、Out-of-Domain問題(地域毎に単独な訓練が必要)など、解決しなければならない課題はまだまだあります。Occupancy Network [引用*28]、リアルタイムHDマップ構築、マルチエージェント走行軌跡予測など、これらの課題の対策になりうる技術も次々と出てきていますが、まだまだこれからです。これらの技術研究により、いつかは無人運転が当たり前になる世界が訪れると信じています。
引用元
*1 FIERY: Future Instance Prediction in Bird’s-Eye View from Surround Monocular Cameras
https://arxiv.org/pdf/2104.10490.pdf
*2 Delving into the Devils of Bird’s-eye-view Perception: A Review, Evaluation and Recipe
https://arxiv.org/pdf/2209.05324.pdf
*3 Panoptic Segmentation
https://arxiv.org/pdf/1801.00868.pdf
*4 Index Coding of Point Cloud-Based Road Map Data for Autonomous Driving
https://www.semanticscholar.org/paper/Index-Coding-of-Point-Cloud-Based-Road-Map-Data-for-Chu-Magsino/a560ee4a08b51bcaa0badab4170b3afb051585b9/figure/0
*5 視線速度
https://ja.wikipedia.org/wiki/%E8%A6%96%E7%B7%9A%E9%80%9F%E5%BA%A6
*6 nuScenes
https://www.nuscenes.org/nuscenes#data-collection
*7 openCalib
https://github.com/PJLab-ADG/SensorsCalibration
*8 An overview of semantic image segmentation.
https://www.jeremyjordan.me/semantic-segmentation/
*9 Multi-modal Sensor Fusion for Auto Driving Perception: A Survey
https://arxiv.org/pdf/2202.02703.pdf
*10 PointPillars
https://openaccess.thecvf.com/content_CVPR_2019/papers/Lang_PointPillars_Fast_Encoders_for_Object_Detection_From_Point_Clouds_CVPR_2019_paper.pdf
*11 VoxelNet
https://arxiv.org/abs/1711.06396
*12 nuScenes detection task Leaderboard
https://www.nuscenes.org/object-detection?externalData=all&mapData=all&modalities=Any
*13 Delving into the Devils of Bird’s-eye-view Perception: A Review, Evaluation and Recipe
https://arxiv.org/pdf/2209.05324.pdf
*14 ResNet
https://cvml-expertguide.net/terms/dl/cnn/cnn-backbone/resnet/#:~:text=ResNet%20(Residual%20Neural%20Networks)%E3%81%A8%E3%81%AF%EF%BC%8C%E6%AE%8B%E5%B7%AE%E6%8E%A5%E7%B6%9A,et%20al.%2C%202016a%5D%EF%BC%8E
*15 Swin Transformer
https://qiita.com/m_sugimura/items/139b182ee7c19c83e70a
*16 FPN
https://cvml-expertguide.net/terms/dl/object-detection/fpn/
*17 PointNet
https://arxiv.org/abs/1612.00593
*18 カメラモデル (Camera Model)と透視投影 (Perspective Projection)
https://cvml-expertguide.net/terms/cv/camera-geometry/camera-model/
*19 Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D
https://arxiv.org/pdf/2008.05711.pdf
*20 BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
https://arxiv.org/pdf/2203.17270.pdf
*21 Transformer
https://crystal-method.com/topics/transformer-2/
*22 DETR
https://www.ogis-ri.co.jp/otc/hiroba/technical/detr/part2.html
*23 Deformable Attention
https://qiita.com/wakayama_90b/items/7a3b761e3c6b36851b45
*24 Squeeze-and-Excitation
https://qiita.com/daisukelab/items/0ec936744d1b0fd8d523
*25 BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework
https://arxiv.org/pdf/2205.13790.pdf
*26 アダマール積
https://ja.wikipedia.org/wiki/%E3%82%A2%E3%83%80%E3%83%9E%E3%83%BC%E3%83%AB%E7%A9%8D
*27 ロングテール問題
https://arxiv.org/pdf/2110.04596.pdf
*28 Occupancy Network
https://www.thinkautonomous.ai/blog/occupancy-networks/
この記事が気に入ったらサポートをしてみませんか?