
"MaskGIT: Masked Generative Image Transformer"を読んだ

株式会社GA technologies、AI Strategy Center(以下AISC)の岩隈です。
2022年11月に開設したAISCブログですが、AISCをもっと知ってもらうために2023年はより色んなコンテンツで盛り上げていこうと思っていますので、本年も何卒よろしくお願いします!
今回の内容
今回はCVPR 2022でGoogle Researchから発表された"MaskGIT: Masked Generative Image Transformer"[1]を紹介しようと思います。
取り上げた経緯としては、今年の年始にTwitterで「拡散モデルや自己回帰モデルベースの手法と同等のクオリティでより効率的にtext-to-imageを行える新しい手法」としてGoogle Researchから”Muse”[2]が発表されたと知ったことがきっかけです。
こちらの”Muse”に関しては社内勉強会で取り上げさせてもらったのですが、関連研究を整理するにあたって”Muse"の画像生成部分に当たる”MaskGIT”(Masked Generative Image Transformer)が特に面白いなと思ったのでブログでも取り上げることにしました。
ということで、今回はMaskGITについて手法を中心に簡潔に紹介します!
注意
本編では、正確ではない表現や筆者(岩隈)の理解不足による間違いが含まれている恐れがあります。
質問・感想はもちろん、ご指摘を頂けると励みになります!
本編: "MaskGIT: Masked Generative Image Transformer"
概要
画像生成を目的に、画像をトークン化したvisual token系列の分布を学習する生成モデルとして、従来のcausal language modelingによる自己回帰モデルではなく、bidirectional transformerを用いたmasked modeling(論文ではmasked visual token modelingと呼んでいる)による非自己回帰モデルを使用することを提案。
これにより双方向のコンテキストの利用と並行デコーディングが可能になり、自己回帰モデルベースの手法と比べて画像生成の品質向上と効率化を達成、拡散モデルやGANベースの手法と比べても同等の画像品質を示した。
また、image manipulationやimage extrapolationなどの応用にも簡単に拡張できる。
背景
GANを用いて生成された画像は高品質な一方で多様性が低かったり、敵対的学習の不安定さによりスケールしないなどの課題があります。そのため、近年では拡散モデルや自己回帰モデルを用いた、尤度最大化によって学習を行う画像生成モデルが注目を集めています。
自己回帰モデルを用いた画像生成の場合、直接ピクセル値の分布を学習することが難しいので、エンコーダを用いて画像を潜在変数に変換した後、その潜在変数の分布を学習するという方法が一般的です。潜在変数の分布を学習した後、画像の生成は、変換に使用したエンコーダと対になるデコーダを用いてサンプリングした潜在変数を画像に戻すことによって行います。
VQGAN [3]
自己回帰モデルを用いた画像生成の代表的な手法としてVQGANがあります。
VQGANの学習は2-stageで行われます。
画像を潜在変数へと変換するエンコーダと、その逆を行うデコーダ、潜在変数を表現するコードブック(後述)の学習
自己回帰モデルによる潜在変数の分布の学習
VQGANの概略図を図1に示します。

(参考文献[3]から引用)
以下では、それぞれの学習について説明します。
エンコーダ、デコーダ、コードブックの学習(1st stage)
VQGANでは、潜在変数として$${K}$$個の量子化されたベクトル(コード)からなるコードブック$${\mathcal{Z} = \{z_k\}_{k=1}^K\subset\mathbb{R}^{n_z}}$$を使用します。$${n_z}$$はコードの次元数です。
補足
ここでの「量子化」とはベクトル量子化(vector quantisation, VQ)のことで、連続的なベクトル表現を離散的なベクトル表現に置き換えることを指します。VQVAEを提案した論文[4]によって、離散的な表現を用いることでVAE[5]に見られる"posterior collapse"(強力なデコーダによって潜在変数を無視した画像生成が行われる現象)を緩和できることが知られています。
入力画像を$${x \in \mathbb{R}^{H \times W \times 3}}$$、エンコーダを$${E}$$、エンコーダ出力を$${\hat{z} = E(x)\in \mathbb{R}^{h \times w \times n_z}}$$とすると、量子化された潜在変数$${z_{\mathbf{q}}}$$は、空間ごとのエンコーダ出力$${\hat{z}_{ij}\in \mathbb{R}^{n_z}}$$をコードブック内の最近傍コードにそれぞれ置き換える操作$${\mathbf{q}}$$によって、以下の式(1)ように表されます。
$$
\begin{align}
\tag{1}
z_{\mathbf{q}} = \mathbf{q}(\hat{z})
:= \Big(\argmin_{z_k \in \mathcal{Z}} \| \hat{z}_{ij} - z_k\| \Big)
\in \mathbb{R}^{h \times w \times n_z}
\end{align}
$$
補足
画像$${x}$$をエンコードしコードブックに存在するコードで表現する操作$${\mathbf{q}(E(x))}$$を"image tokernize"や”トークン化する”などと呼ぶことが多いため、以後この記事でもそのように呼ぶことがあります(この文脈では、コードは"image/visual token"や”トークン”と、コードブックの大きさ$${K}$$は”ボキャブラリー”と呼ばれたりします)。
また、デコーダを$${G}$$とすると再構成画像$${\hat{x}}$$は以下のように表されます。
$$
\begin{align}
\tag{2}
\hat{x} = G(z_\mathbf{q}) = G(\mathbf{q}(E(x)))
\end{align}
$$
VAGANの1st stageの学習では、エンコーダ、デコーダ、コードブックの学習のために以下の損失を使用します。$${\textrm{sg}[\cdot]}$$はstop-gradient operationです。
$$
\begin{align}
\tag{3}
\mathcal{L}_{VQ}(E,G,Z) =
\|x - \hat{x}\|^2 +
\| \textrm{sg}[E(x)] - z_{\mathbf{q}}\|_2^2 +
\| \textrm{sg}[z_{\mathbf{q}}] - E(x) \|_2^2
\end{align}
$$
式$${(2)}$$における、量子化での微分不可能な操作をまたぐ誤差伝播はstraight-through gradient estimatorと呼ばれるデコーダからの勾配をシンプルにエンコーダへコピーする操作によって行われます。
また、式$${(3)}$$は実際にはVQVAE[4]で提案されているものであり、VQGANでは第1項の再構成誤差をperceptual lossに変更し、Discriminatorを用いたadversarial lossを追加することで生成画像の品質向上を達成しています。
自己回帰モデルの学習(2nd stage)
一度エンコーダ(、デコーダ)、コードブックが学習できると、
画像$${x}$$が与えられたときに(その量子化された潜在変数を$${z_\mathbf{q} = \mathbf{q}(E(x))\in \mathbb{R}^{h \times w \times n_z}}$$とすると)、その画像をコードブックのインデックスの系列$${s \in \{0, …, |\mathcal{Z}|-1\}^{h \times w}}$$として表現できるようになります。
$$
\begin{align}
\tag{4}
s_{ij} = k \textrm{ such that } (z_\mathbf{q})_{ij} = z_k
\end{align}
$$
ここでインデックスの系列の並べ方としては一般的にラスタースキャンオーダー(左から右へ1行ずつ、2次元の空間情報を1次元の系列データへ並べ替える方法)が使用されます。
あとは自然言語を対象としたcausal language modelingの学習と同様に、transformerモデルを用いて、与えられたインデックス系列$${s_{< i}}$$から次のインデックスの分布$${p(s_i|s_{< i})}$$を予測する自己回帰モデルを学習します。
インデックス系列全体の尤度を$${p(s) = \prod_{i} p(s_i | s_{< i})}$$とすると、このtransformerモデルの学習に使用する損失は以下の負の対数尤度となります。
$$
\begin{align}
\tag{5}
\mathcal{L}_{\textrm{Transformer}} =
\mathbb{E}_{x \sim p(x)} \big[ - \log p(s) \big]
\end{align}
$$
次節からMaskGIT(Masked Generative Image Transformer)の説明に入ります。
動機
VQGANの自己回帰モデルの学習からも分かるとおり、従来の自己回帰モデルベースの画像生成では、各visual tokenが考慮できるコンテキストがラスタースキャンオーダーによって一方向に制限されています。実際の画家が絵を描くときにラフなスケッチから始めて徐々に細部を詰めていくプロセスと比較するとこれは最適ではない、というのがMaskGITの直感的な動機です。
また、自己回帰モデルを用いた画像生成では、解像度に比例して系列が大きくなるのに対して、推論時には一つ前の推論結果を利用する必要があるため系列内のvisual tokenを一つずつしかサンプリングできずスケールしないという課題があります。
手法
MaskGITでは、VQGANと同様に画像をトークン化したvisual token系列の分布を対象とした生成モデルを学習することで画像生成を行います。
そのため、MaskGITも1)エンコーダ、デコーダ、コードブックの学習、2)visual tokensの分布の学習、という2-stageでの学習を行う枠組みは共通で、1st stageの学習に関しては全く同じです(そのため、1st stageの学習に関しては改めて触れません)。
異なるのは2nd stageの学習で、MaskGITではbidirectional transformerを用いて双方向のコンテキストを利用しながらマスクされたvisual tokenを予測することによってvisual token系列の分布を学習します。この学習を論文ではMasked Visual Token Modeling(MVTM)と呼んでいます(学習としては自然言語処理分野でBERTの事前学習に用いられるMasked Language Modelingとほとんど同じです)。
MaskGITの概略図を図2に示します。

(参考文献[1]から引用)
以下では、MVTMによる学習、MaskGITによる画像生成、マスクスケジューリングについて紹介します。
Masked Visual Token Modeling による学習
画像をトークン化して得られるvisual token系列をここでは$${\mathbf{Y} = [y_i]_{i=1}^N}$$とします。$${N}$$はvisual token系列の長さです。また、各トークンにマスクをするかどうかに対応する二値フラグ系列を$${\mathbf{M} = [m_i]_{i=1}^N}$$とします。これは$${m_i = 1}$$のとき、$${i}$$番目に位置するvisual token $${y_i}$$を$${\mathtt{[MASK]}}$$ tokenで置き換えることを意味します。
マスク$${\mathbf{M}}$$を適用した後のvisual tokensを$${Y_{\bar{M}}}$$とすると、MVTMによるvisual token系列の分布の学習は、bidirectional transformerを用いた非自己回帰モデルによって$${Y_{\bar{M}}}$$に含まれる$${\mathtt{[MASK]}}$$ token位置でのvisual tokenを予測することで行われます。
この学習での損失は、$${\mathtt{[MASK]}}$$ token位置での予測に対する負の対数尤度として(より具体的にはクロスエントロピー)、以下のように表せます。
$$
\begin{align}
\tag{6}
\mathcal{L}_{\textrm{mask}} =
\mathbb{E}_{\mathbf{Y} \in \mathcal{D}}
\Big[
\sum_{\forall i \in [1, N], m_i=1} - \log p(y_i | Y_{\bar{M}})
\Big]
\end{align}
$$
自己回帰モデルを用いた生成モデルと比べると、MVTMで学習した生成モデルは系列の方向に限定にされないコンテキストを利用可能であり、元々系列データではない画像というドメインに対してより適していると考えられます。
後述しますが、MVTMで学習したモデルの推論(=visual token系列のサンプリング)は段階的に行われ、その進行段階$${r\in[0, 1)}$$に応じて$${\mathtt{[MASK]}}$$ tokenの割合を決定するmask scheduling function $${\gamma(r)\in(0, 1]}$$(単調減少)に従って、$${\mathtt{[MASK]}}$$ tokenをモデルの予測に基づいてサンプリングされたvisual tokenに徐々に置き換えていくことで、最終的にvisual token系列全体をサンプリングします。
推論時に様々な進行段階での予測ができるように、学習時の進行段階$${r}$$は0から1までの範囲で一様にサンプリングされることでシミュレーションされます。従って、学習時のマスクは、サンプリングされた進行段階$${r}$$を使って、$${\mathbf{Y}}$$の中から$${\lceil\gamma(r)\cdot N\rceil}$$個のvisual tokensを$${\mathtt{[MASK]}}$$ tokenに置き換えることで設定されます。
この点が、表現学習を目的とした、$${\mathtt{[MASK]}}$$ tokenの割合が常に一定のmasked modeling(自然言語処理でのmasked language modelingなど)とは異なります。
MaskGITによる画像生成:Iterative Decoding
自己回帰モデルを用いた推論と異なり、bidirectional transformerを用いた推論では系列の特定方向への依存がないので同時にいくつものvisual tokenをサンプリングすることで効率的な推論が実現できます。
図3に自己回帰モデル、MaskGITをそれぞれを用いてサンプリングされるvisual token系列とそれをデコードした画像の経過を示します。
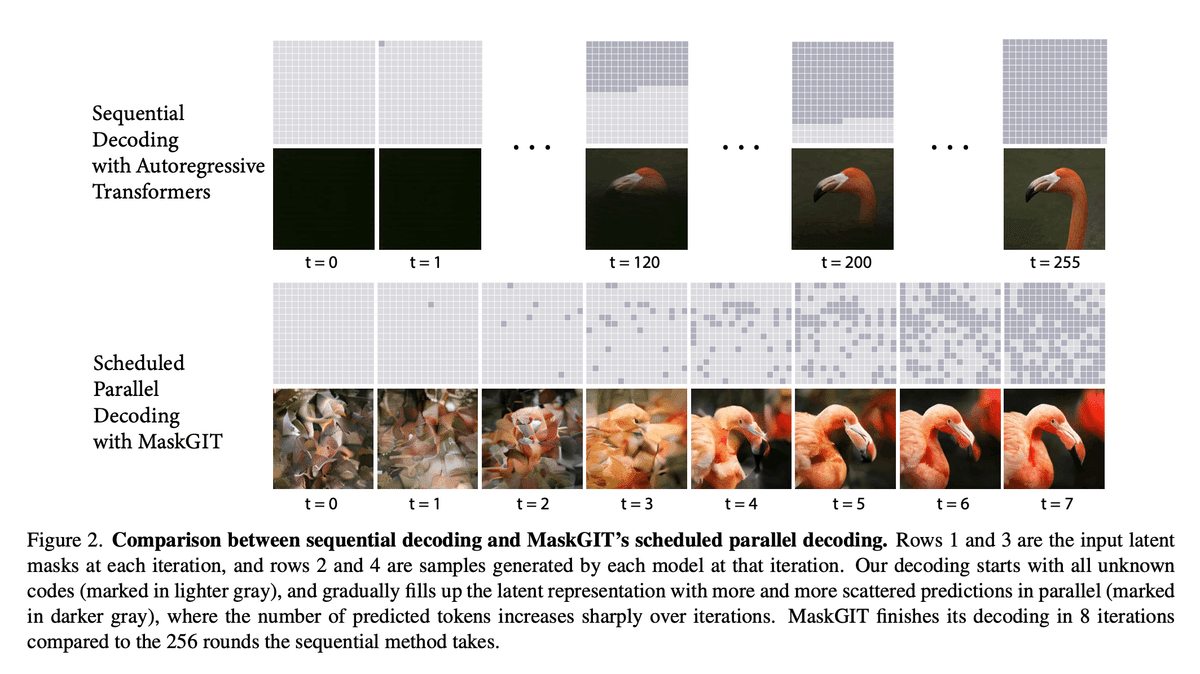
(参考文献[1]から引用)
この論文では、$${\mathtt{[MASK]}}$$ tokenのみからなるvisual token系列 $${Y_M^{(0)}}$$(比喩的に無地のキャンバス)に対して、以下の操作を$${T}$$回繰り返すことで段階的にvisual token系列全体$${Y_M^{(T)}}$$をサンプリングし、最終的にデコーダによって画像を生成する"iterative decoding"を提案しています。
以下の操作説明では、visual tokenのボキャブラリーは$${K}$$個、現在の繰り返し数を$${t}$$としています。
Predict:$${\mathtt{[MASK]}}$$ tokenを含む現在のvisual token系列 $${Y_M^{(t)}}$$を入力として、モデルから各位置のvisual tokenの確率$${p^{(t)}\in\mathbb{R}^{N \times K}}$$を予測する。
Sample:$${Y_M^{(t)}}$$内のマスクされている位置$${I}$$に対して、予測された確率$${p_i^{(T)}\in \mathbb{R}^K}$$に基づいてvisual token $${y_i}$$をサンプリングする。このときサンプリングされた$${y_i}$$に対応する確率をこのvisual tokenの"confidence"スコアとする。マスクされていない位置にあるvisual tokenの"confidence"スコアは1.0に設定する。
Mask Schedule:mask scheduling function $${\gamma}$$を用いて、マスクとして残しておくトークン数 $${n = \lceil \gamma(\frac{t}{T})\cdot N\rceil}$$を決める。
Mask:以下の式(7)のように、現在のvisual token系列$${Y_M^{(t)}}$$のうち"confidence"スコアが低い方から$${n}$$個を$${\mathtt{[MASK]}}$$ tokenのまま残し、それ以外をサンプリングしたvisual tokenで置き換えることで更新する($${\to Y_M^{(t+1)}}$$)。
$$
\begin{align}
\tag{7}
m_i^{(t+1)} =
\begin{cases}
1,&\text{if $c_i < \textrm{sorted}_j(c_j)[n]$ } \\
0,&\text{otherwise}
\end{cases} \\
\text{where $c_i$ is the "confidence" score for the $i$-th token}
\end{align}
$$
図3では、iterative decodingによって段階的に高品質かつ効率的な画像生成行えることを視覚的に示しています。
マスクスケジューリング
ここで言う「マスクスケジューリング」とは、visual token系列の推論の進行段階$${r}$$(推論時だと$${r = 0/T, 1/T, \cdot \cdot \cdot, (T-1)/T}$$)に応じて$${\mathtt{[MASK]}}$$ tokenの割合を調整することを指しており、これが画像生成結果の品質に大きな影響を与えるとこの論文では主張しています。
マスクスケジューリングは、より具体的に、mask scheduling functionとして$${\gamma(0)\to1}$$かつ$${\gamma(1)\to0}$$を満たす単調減少な連続関数を設定することで行われます。
いくつかのmask scheduling functionを適用した結果が表1と図4です。
結果としては推論の進行段階後半になるにつれて一度のステップで多くのマスクを取り除く上凸の形状をしたmask scheduling functionが良い品質を与えていることが分かります。また、最大繰り返し数$${T}$$は大きすぎても良い結果を与えず8-12程度が最も良かったとのことです。

(参考文献[1]から引用)

(参考文献[1]から引用)
結果
今回は手法をメインで紹介したかったので、実験結果に関して簡単に見ていきます!
class-conditional image synthesis
まずクラスラベルを用いた条件付き画像生成の結果です。
従来の手法との定量的な比較を表2に、定性的な比較を図5に示します。
品質の観点では、表2のFID・ISといった評価指標から従来のSOTA手法と同等もしくはより良い結果が得られています。また、多様性の観点では表2のCASといった評価指標や図5から見てとれるように、GANベースの手法と比較して良い結果が得られています。

(参考文献[1]から引用)

(参考文献[1]から引用)
inference speed
図6にvisual token系列の長さに対するVQGAN(自己回帰モデルベース)とMaskGITの推論速度の比較を示します。
visual token系列の長さが大きくなるにつれてMaskGITの方が30-64倍程度の高速化を達成できていることが分かります。

(参考文献[1]から引用)
applications
MaskGITでは、元々visual token系列のマスクを予測するといったタスクで学習を行なっているため、画像の一部をマスクして異なる条件で部分的な再生成を行うconditional image editingや、画像の外側を補完するimage outpaintingなどの応用に拡張することが容易です。
図7にclass-conditional image editingへの、図8にimage inpaintingとoutpaintingへの適用結果を引用しておきます。

(参考文献[1]から引用)

(参考文献[1]から引用)
おわりに
今回は、MaskGITという非自己回帰モデルを用いた潜在空間上での画像生成モデルを紹介させて頂きました。簡潔に紹介するつもりだったのですが、今回もまた長くなってしまいました。次回こそは簡潔に読みやすい記事を書きたいと思います。
冒頭でも触れましたが、MaskGITをtext-to-imageへ拡張した"Muse"というモデルの論文が既に同チームからプレプリントとして公開されています。その一方で、"Muse"の論文中では拡散モデルベースのDALL・E2やImagen、自己回帰モデルベースのPartiといったtext-to-imageで行われていた1024x1024サイズの画像生成結果が示されていなかったので、まだスケールへ課題があるのかそれとも更に改良の余地があるのかが個人的には気になっています。
MaskGITはデモ用のコードが公開されているので少し中身を見てみようと思っています。その中でこのブログの内容に誤りなどが見つかった時は適宜修正しておきます!
以上、ここまで読んで下さりありがとうございました!!
参考文献
Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu, William T. Freeman, "MaskGIT: Masked Generative Image Transformer", CVPR 2022, [arXiv]
Huiwen Chang, Han Zhang, Jarred Barber, AJ Maschinot, Jose Lezama, Lu Jiang, Ming-Hsuan Yang, Kevin Murphy, William T. Freeman, Michael Rubinstein, Yuanzhen Li, Dilip Krishnan, "Muse: Text-To-Image Generation via Masked Generative Transformers", 2023, [arXiv]
Patrick Esser, Robin Rombach, Björn Ommer, "Taming Transformers for High-Resolution Image Synthesis", CVPR 2021, [arXiv]
Aaron van den Oord, Oriol Vinyals, Koray Kavukcuoglu, "Neural Discrete Representation Learning", NeurIPS 2017, [arXiv]
Diederik P Kingma, Max Welling, "Auto-Encoding Variational Bayes", 2013, [arXiv]
この記事が気に入ったらサポートをしてみませんか?